A multimodal model that handles images and characters has appeared as an open source ``OpenFlamingo'', and a free demo is also available
A framework ' OpenFlamingo ' that reproduces DeepMind's
Announcing OpenFlamingo: An open-source framework for training vision-language models with in-context learning | LAION
https://laion.ai/blog/open-flamingo/
GitHub - mlfoundations/open_flamingo: An open-source framework for training large multimodal models
https://github.com/mlfoundations/open_flamingo
Gradio
https://7164d2142d11.ngrok.app/
OpenFlamingo was developed by LAION, a German non-profit organization that developed the dataset ` ` LAION-5B '', which was also used to train Stable Diffusion, an image generation AI.
LAION created OpenFlamingo with the goal of developing a multimodal system capable of tackling a wide variety of visual-linguistic tasks. Ultimately, we aim to match the power and diversity of GPT-4, which handles visual input and text input, and we have created an open source version of the Flamingo model to achieve this goal.
OpenFlamingo has a repository published on GitHub, and a separate demo page has been opened. On this demo page, there are four main functions available: image caption generation, animal recognition, object counting, and image question answering, so I tried them one by one.
Start with image caption generation. This is a demonstration of what OpenFlamingo is for an uploaded image. Two sample images have already been prepared, the first one has the answer ``Men and women looking at mobile phones on the train'', the second one has the answer ``Luxury reception with black and white tiled floors'' room' is output.
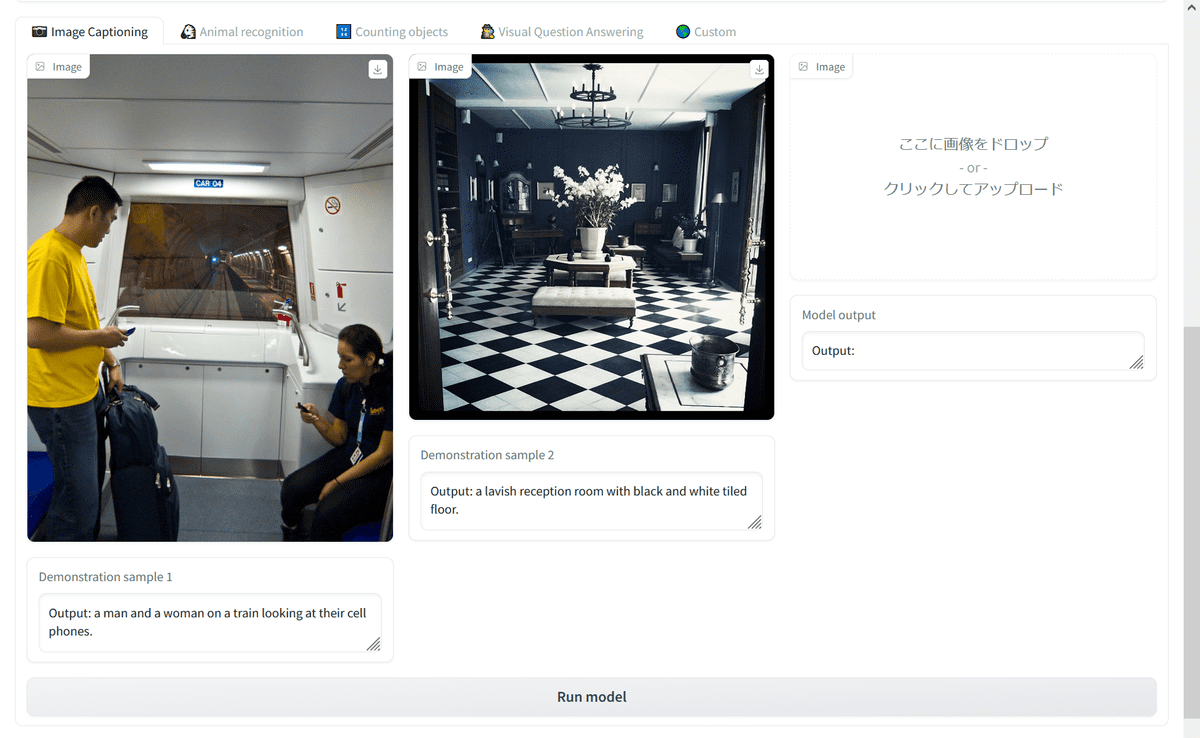
So I will actually try it. First, click the checkbox to agree to the terms and upload the image. Finally, click 'Run model' and wait for a while.
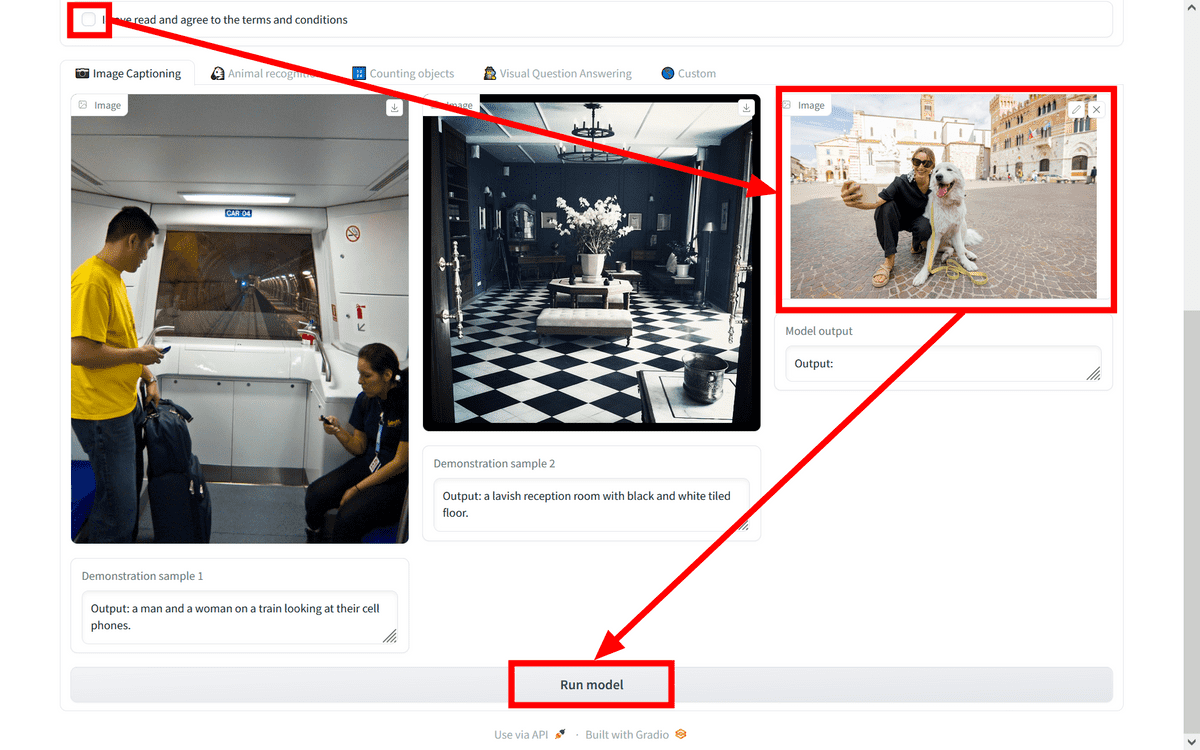
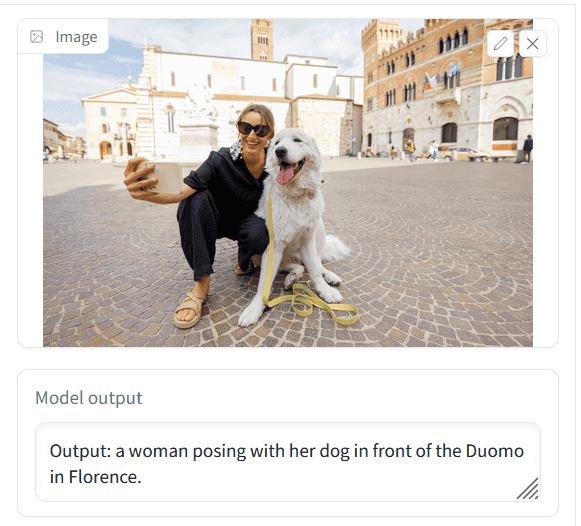
The actual output response looks like this. OpenFlamingo replies, 'Woman posing with a dog in front of
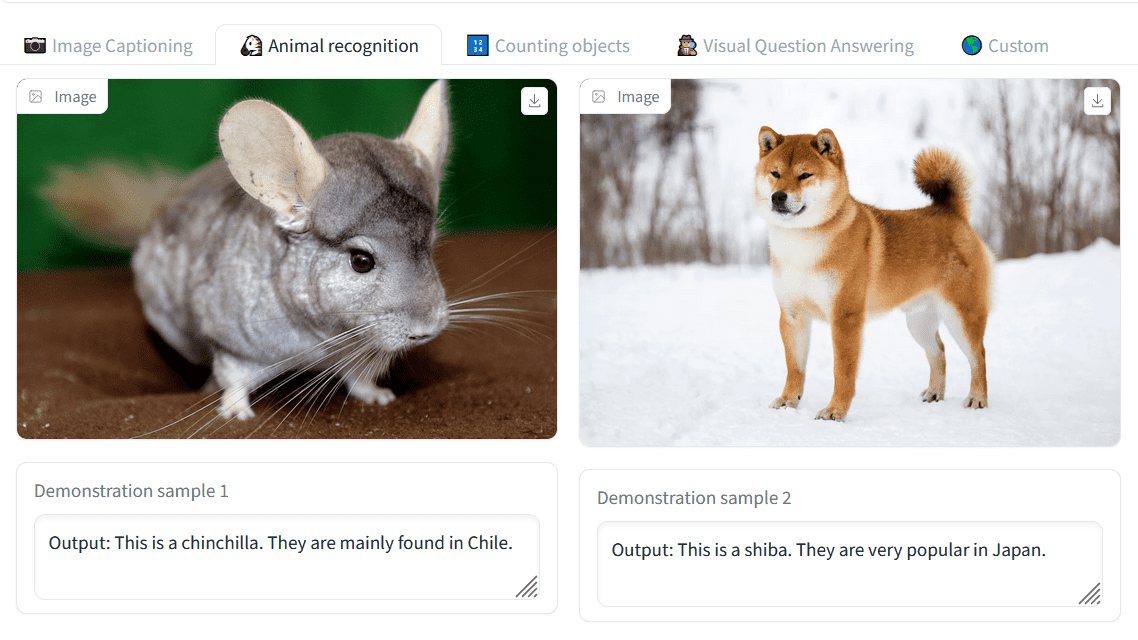
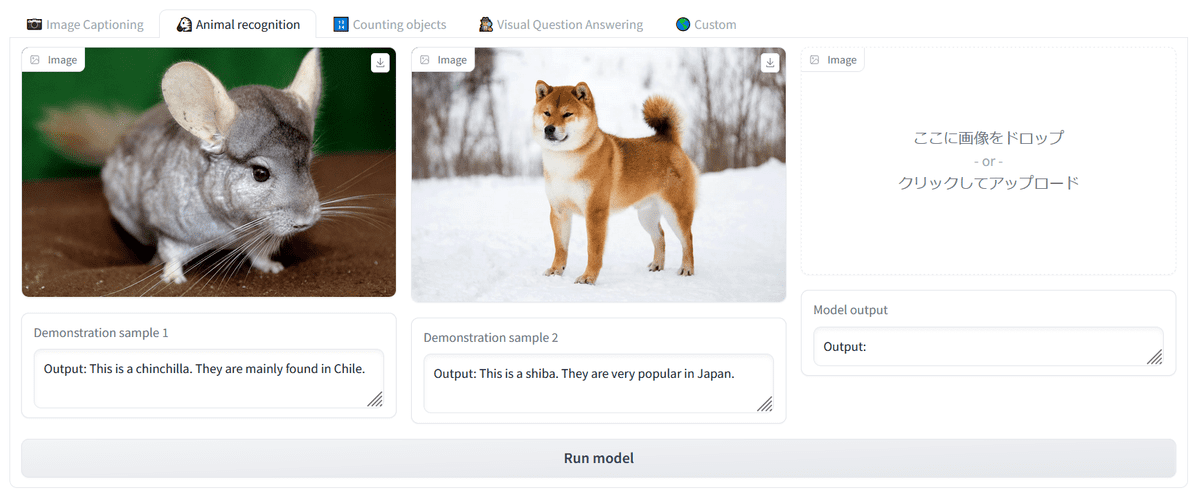
Then check animal recognition. It's a demo where OpenFlamingo guesses what the animal in the picture is, but the first one is a chinchilla, and the second one is a shiba inu. A commentary is also included.
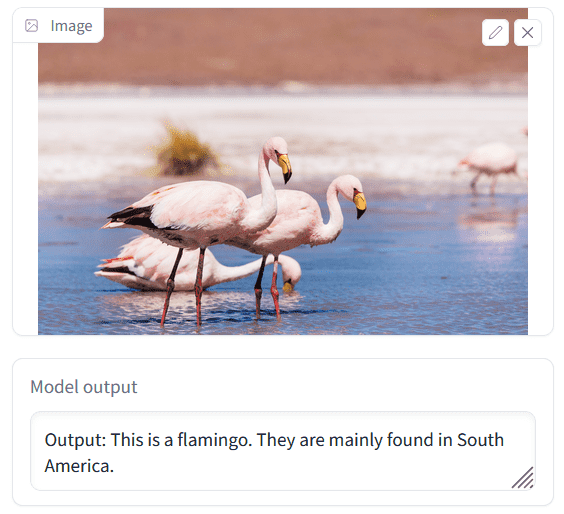
When I tried it with a flamingo image, it displayed the answer correctly.
Next is a demonstration of guessing the number of objects in the picture.
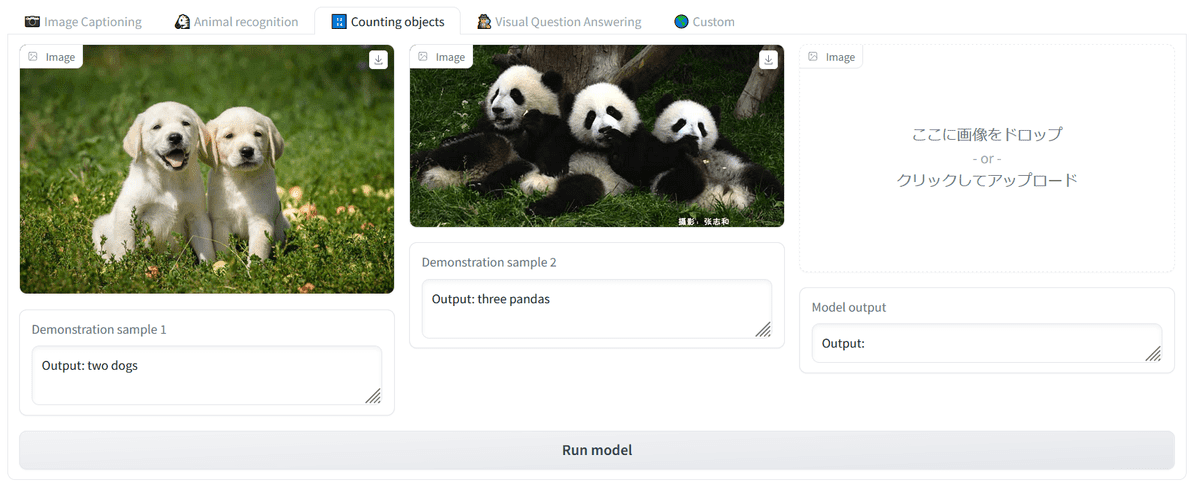
OpenFlamingo was unable to guess the correct number of flamingos.

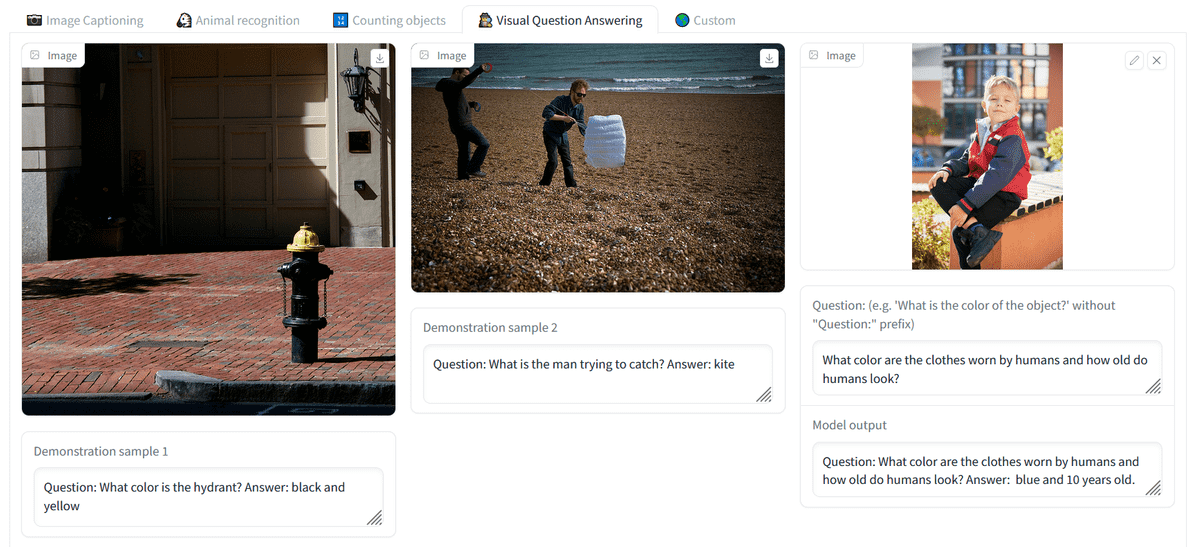
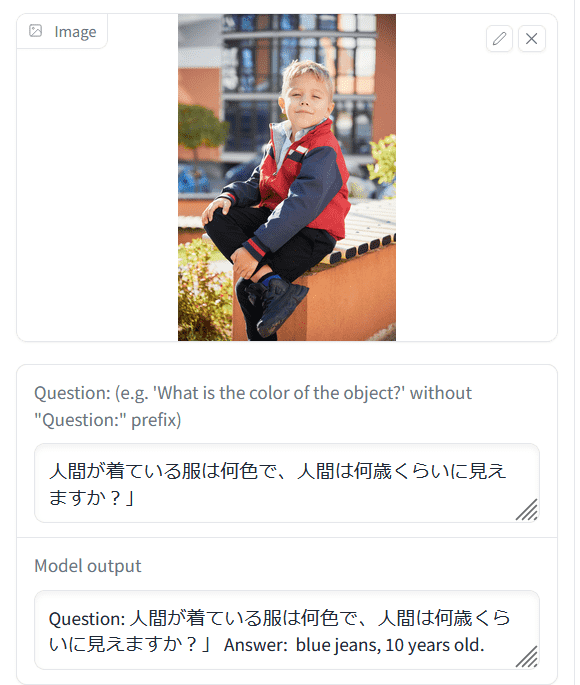
Below is a demo of how OpenFlamingo responds to image and text input. Answer ``Q: What color is the fire hydrant?'' ``A: Black and yellow'' on the first sheet, and ``Q: What is the man trying to catch?'' ``A: Octopus'' on the second sheet I'm here. So, I uploaded a picture of a person in elementary school wearing red clothes and asked, 'What color is the clothes that the person is wearing and how old do you think the person looks?' Blue, 10 years old,” came the answer.
In addition, it is OK to ask in Japanese. OpenFlamingo returns in English.
OpenFlamingo implements the same architecture proposed in the Flamingo paper, but the training data for Flamingo is not publicly available, so an open-source dataset was used for training OpenFlamingo. Specifically, the OpenFlamingo-9B released this time is trained on the Multimodal C4 dataset with 5 million samples and LAION-2B with 10 million samples.
LAION shares the first checkpoints of the OpenFlamingo-9B model, which is not yet fully optimized, but shows the potential of this project. However, it is important for the research community to study the harms of large-scale multimodal models, and we are open sourcing these models. We believe that this will enable the community to develop better ways to mitigate these harms in future models.'
Related Posts: