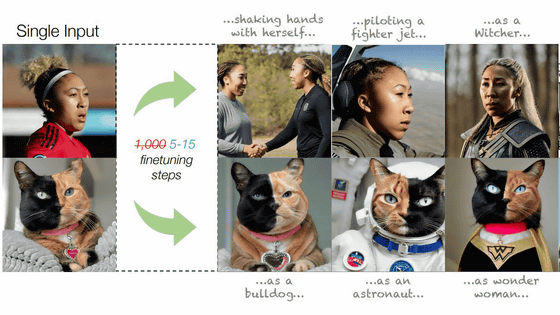
Explain the merits and demerits of ``Textual Inversion'' that fine-tunes the image generation AI ``Stable Diffusion'' with several images with actual examples

' Textual Inversion ' is a method of making Stable Diffusion of image generation AI learn several images, relearning the entire AI model and adjusting (fine tuning). Mr.
임베딩(텍스쳘 인버전) 에 대해 아라보자 - 파일 첨부 - AI 이림 학습 채널
https://arca.live/b/hypernetworks/60910400
Textual Inversion is to make a model that can generate an image close to the learned image by letting Stable Diffusion additionally learn and adjust several images. You can see exactly what kind of image can be generated with Textual Inversion by reading the following article.
``Textual Inversion'' technology that realizes ``generate this image-like XX'' with image generation AI ``Stable Diffusion'' has appeared-GIGAZINE

On the other hand, 'Hyper Network' is the technology adopted to improve image quality in NovelAI, an image generation AI. It builds a single small neural network on multiple points in the AI's neural network to improve the accuracy of the image.
What kind of improvements did the topic 'NovelAI' make to the original Stable Diffusion that it can generate ultra-high-precision illustrations? -GIGAZINE

According to Mr. ㅇㅇ, Textual Inversion and Hyper Network have different driving principles, and Textual Inversion has much smaller capacity of learning results than Hyper Network.
Textual Inversion has a slower learning speed than Hyper Network, so it is more suitable for learning specific objects, characters, features, etc. than abstract things such as patterns and painting styles. Also, in order to memorize the pattern and painting style, it is necessary to prepare data that has been unified to some extent, such as coloring and color usage, so it is more difficult to prepare learning data than Hyper Network.
Also, Hyper Network can only embed one at a time, but even so, it is OK if you prepare a large amount of data using various patterns of composition, materials, and techniques and let it learn. Therefore, it can be said that Hyper Network is more suitable for improving the accuracy of illustrations. However, textual inversion is easier to handle if you want to remember specific patterns and characteristics.
Below is the leaked NovelAI lightened model, with the prompt as '(masterpiece:1.2), cute 1girl, (child:1.05), loli, small breasts, looking at viewer, suspender skirt' and the negative prompt as 'lowres, (( ((ugly)))), (((duplicate))), ((morbid)), ((mutilated)), (((tranny))), (((trans))), (((trannsexual)) ), (hermaphrodite), extra fingers, mutated hands, ((poorly drawn hands)), ((poorly drawn face)), (((mutation))), (((deformed))), blurry, ((bad anatomy )), (((bad proportions))), ((extra limbs)), cloned face, (((disfigured))), (((more than 2 nipples))), extra limbs, (bad anatomy), gross proportions, (malformed limbs), ((missing arms)), ((missing legs)), (((extra arms))), (((extra legs))), mutated hands, (fused fingers), (too many fingers), (((long neck))), picture frame”, 28 generation steps, Euler sampler, 11 CFG scale, 3587590841 seed value.

And the following is a model fine-tuned with Mr.

Similarly, the illustration generated by the model fine-tuned by Textual Inversion in Mr. Hiromitsu Takeda 's illustration looks like this.

Also, the following is an illustration by Mr.

Another advantage of Textual Inversion is the ability to readjust multiple elements. For example, the image below is an illustration generated by a fine-tuned model of Mr.

And below is an illustration generated by Mr. Kantoku's illustration and a model fine-tuned with a Victorian race image. If you look closely, you can see that the headband and ribbon are drawn with designs like lace and frills. Hyper Network can only perform single additional learning, but the big point is that Textual Inversion can perform multiple embedding learning at the same time.

In summary, according to Mr. ㅇㅇ, the advantages of Textual Inversion are the following four points.
・Multiple embeddings can be applied at the same time.
・The capacity of the learning result is very small.
・No need to load or restart when adding or deleting.
- You can adjust the weight by the parenthesis rule like a general prompt.
On the other hand, the disadvantages of textual inversion are the following two points.
・The learning speed is very slow.
・It is difficult to prepare learning data.
Related Posts: