3D automatic generation AI 'DreamFusion' that can generate 3D models just by entering text

Diffusion
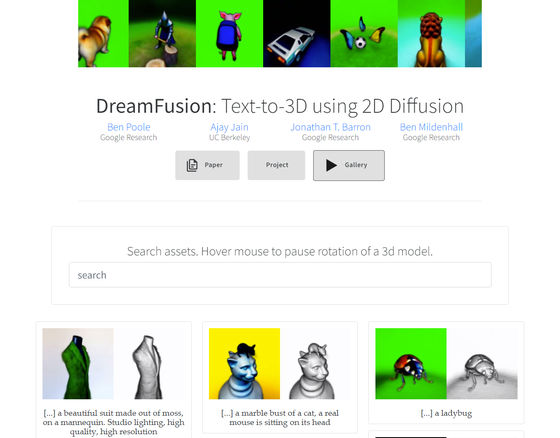
DreamFusion: Text-to-3D using 2D Diffusion
https://dreamfusion3d.github.io/
Building an AI that can automatically generate 3D models from text usually requires a large dataset of labeled 3D assets and an efficient architecture for denoising 3D data. You will need two. But DreamFusion has neither. DreamFusion uses a diffusion model that can output 2D images from pre-trained text and Deep Dream developed by Google engineers to output 2D images from various angles. A 3D model is generated based on this.
It is said that it uses technology similar to 'NeRF' which generates 3D models from multiple still images. You can understand what kind of 3D model can be generated using NeRF by reading the following article.
Will the technology 'NeRF' that generates 3D models from multiple still images advance deep fake? -GIGAZINE

To be more specific, DreamFusion creates 3D models using a ``diffusion model that generates images from text'' called Imagen . DreamFusion adopts a new method 'Score Distillation Sampling (SDS)' that generates samples from the diffusion model by optimizing the loss function, which optimizes the samples in any parameter space such as 3D space. becomes possible. It seems that SDS alone can generate an appropriate 3D model, but adding regularization and optimization strategies to improve the geometry will make it possible to generate a more consistent NeRF model. is.
Actually access the official page of DreamFusion and in the area written 'Generate 3D from text yourself!' You can see how the model changes.

The selectable options are as follows.
・Upper
'a DSLR photo of a squirrelan' (Squirrel photo taken with a digital single lens reflex camera)
'intricate wooden carving of a squirrela' (complicated wood carving squirrel)
'highly detailed metal sculpture of a squirrel' (very detailed metal sculpture)
・Middle
'wearing a kimono'
'wearing a medieval suit of armor' (wearing medieval armor)
'wearing a purple hoodiewearing an elegant ballgown' (wearing elegant evening clothes)
・Lower
'reading a book'
'riding a motorcycle'
'playing the saxophone'
'chopping vegetables'
'sitting at a pottery wheel shaping a clay bowl' (creating a sitting device in front of the potter's wheel)
'riding a skateboard'
'wielding a katana' (wielding a sword)
'eating a hamburger' (eating a hamburger)
'dancing'
Below is the 3D model that is output when you select 'a DSLR photo of a squirrelan', 'wearing a medieval suit of armor', and 'sitting at a pottery wheel shaping a clay bowl'.

In addition, examples of 3D models generated using DreamFusion are summarized on the following page.
DreamFusion: Text-to-3D using 2D Diffusion
https://dreamfusion3d.github.io/gallery.html
Related Posts:







in Software, Posted by logu_ii