NVIDIA creates an architecture for GANs that enables AI to generate false images of unrecognizable levels as real photographs

NVIDIA researchers have published a paper proposing a new style-based generator architecture for hostile generation networks (GANs). This architecture makes it easy to use such as high-level attributes in unsupervised classification (eg pose and identity when learning people's faces), stochastic changes in generated images (eg hair) It seems to be for enabling specific synthesis control.
[1812.04948] A Style-Based Generator Architecture for Generative Advisory Networks
https://arxiv.org/abs/1812.04948
You can see what kind of things can be generated by using the new style-based generator architecture proposed by NVIDIA in a single movie by looking at the following movie.
A Style-Based Generator Architecture for Generative Adversarial Networks - YouTube
GANs can learn how to imitate "real photos" from new images. However, with the previous approaches, very limited control was required to generate images with GANs.
Therefore, NVIDIA researchers are proposing a new "Generator that can automatically learn about different elements of images without human supervision". After learning the GANs, it is possible to combine the elements as you like, so it is possible to generate a wide variety of fake images.

So, the picture displayed in this movie is basically "fake face photo" generated by NVIDIA's new style-based generator architecture.
The following images are the actual pictures (Source A) lined up in the upper row are the basis of sex, age, hair length, hair length, glasses, poses, the bottom left photo (Source B) is based on other elements In the photograph which becomes, the other photograph is "fake face photo" generated by the generator.

Changing the picture of Source B changes the face picture generated by the generator at once, but the gender, age, hair length, glasses, and pose on which Source A is based are not changed.


There is no problem even if the picture of Source B turns into a man.


It is easy to understand that the generated images reflect the characteristics of Source B's pictures even in children.


"Our generators are thinking of images as a collection of" styles. "Each style controls the effect at a particular scale."

Styles are classified as follows.
Coarse styles (coarse style): pose, hair style, face shape
Middle styles (middle style): facial features, eyes
Fine styles (fine style): color summary
For example, in the following cases, the three photos aligned vertically on the left are the actual pictures entered into the generator. From the picture of the top blonde boys, I am extracting a coarse style, a middle style from a middle brown hair woman to a middle style, and a finest black hair style from a woman at the bottom. Hairstyle and outline of face are similar to the top boy, you can see that hair, lips and eyes color comes from the picture of the bottom woman. And, when comparing each part of the face such as eyes, eyebrows, mouth, etc., comparing with each other, it is certainly a picture of a woman in the middle of the left and a melon.

Here change the picture that becomes the basis of "coarse style". "Coarse style" is the base of pose, hair style, face shape, so the image generated by the generator has changed from a boy to a woman.

If you change further it is like this. Since "intermediate style" and "fine style" do not change, facial pictures of various sexes are generated while parts and colors of facials remain the same.


Changing the picture that becomes the basis of "middle style", the outline and the hairstyle do not change, only the parts of the face got completely changed. I have transformed from a carved deep white face to a straight face of Asian line.

Changing the picture that becomes the basis of "fine style" will change the overall color.

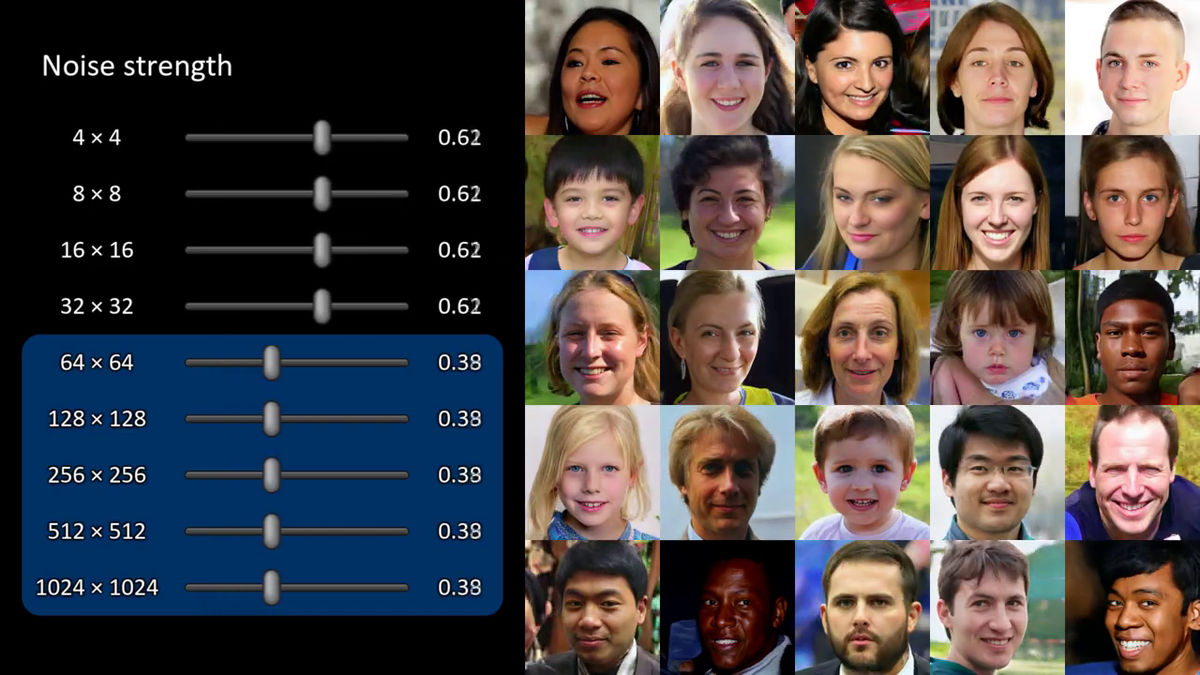
In addition, NVIDIA generators can automatically separate noncritical changes as "noise" from high level attributes such as pose and identity.

The definition of noise is as follows.
Coarse noise: Coarse hair curl
Fine noise (medium noise): fine detail, texture
No noise (No Noise): Looks like a featureless painting
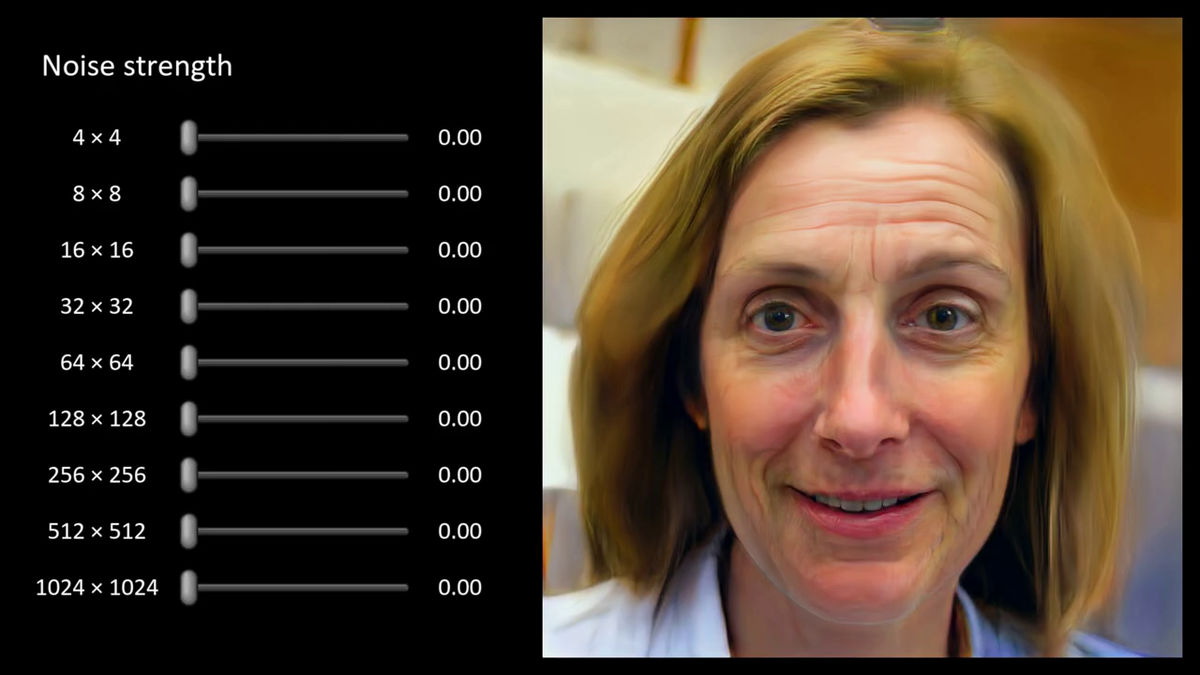
You can freely change the noise of the following images generated by the generator.

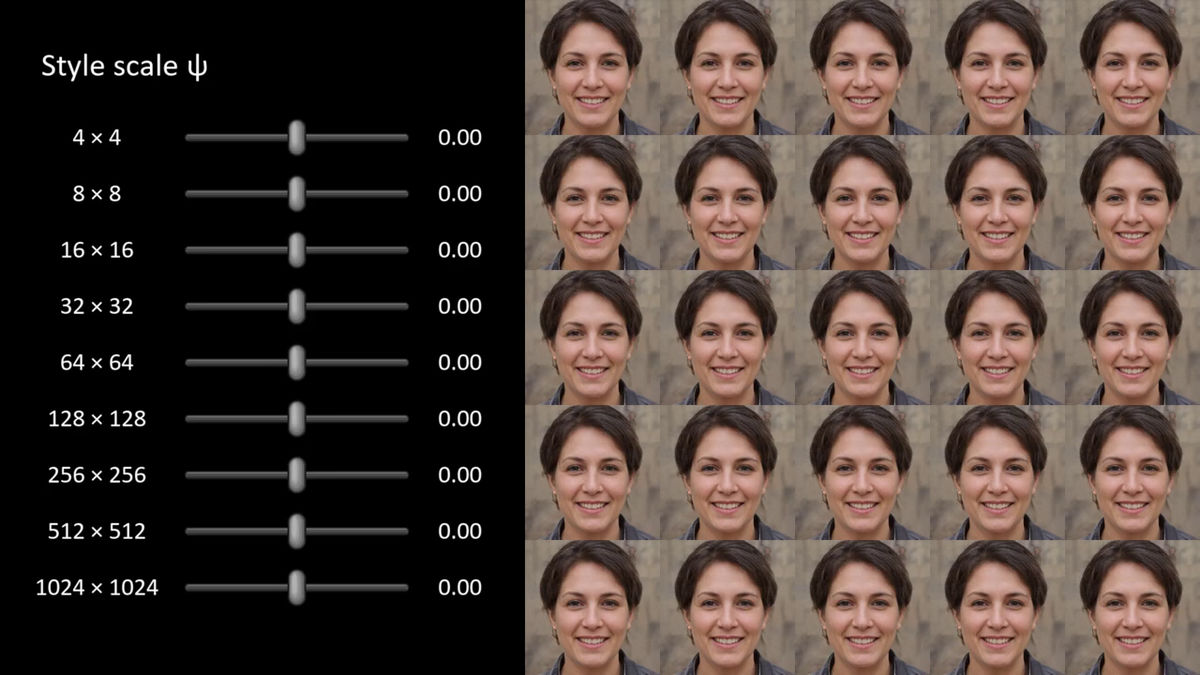
The vertically aligned sliders show the intensity of various noises, and the following images are "0.00", so there are no noises, that is, looks like paintings.
Changing only a part of the noise will add fine wrinkles and hair texture to the overall image as a whole.

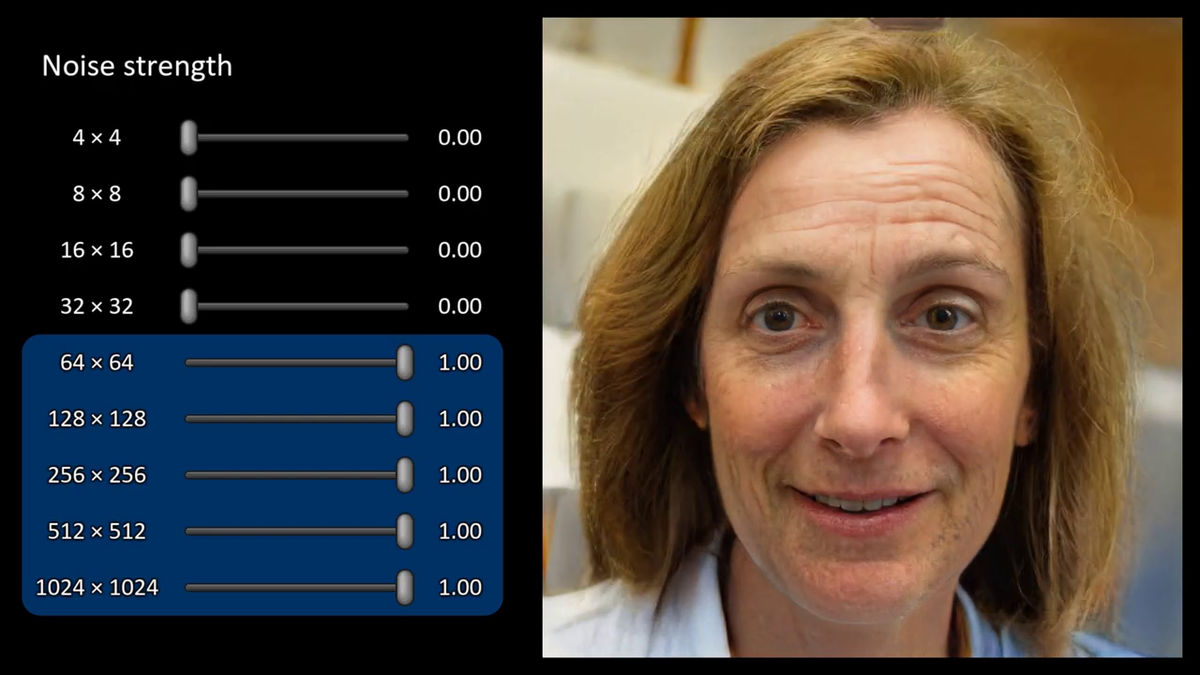
It is like this when changing the noise of multiple images generated by the generators collectively.

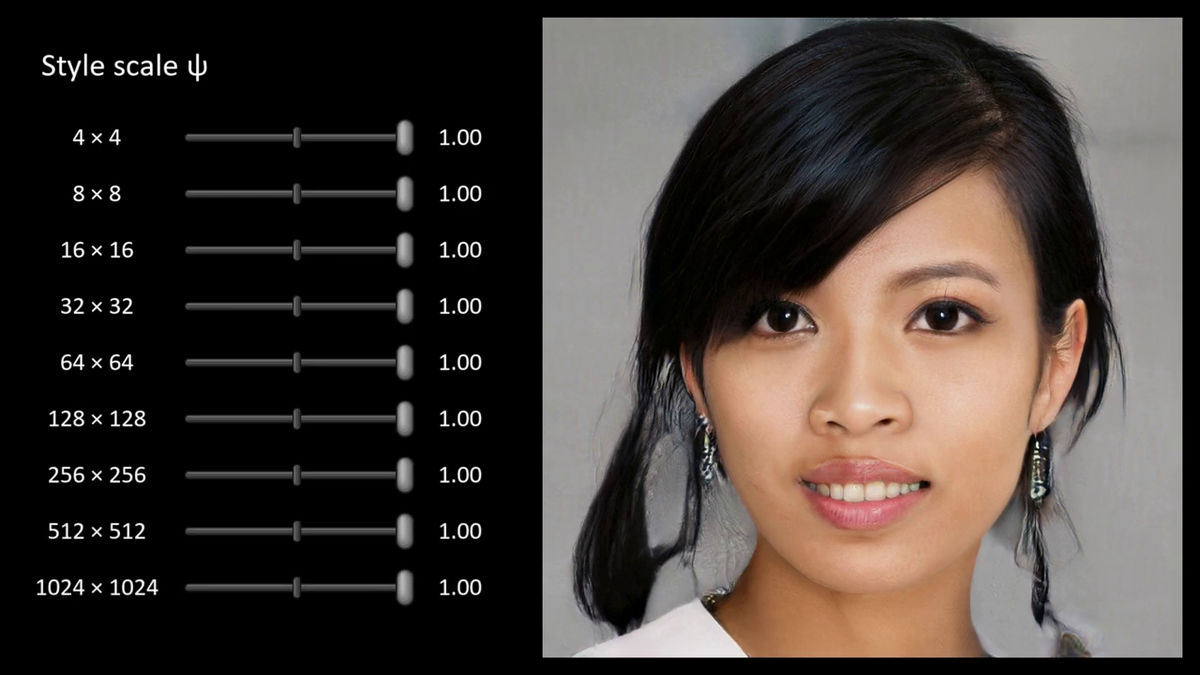
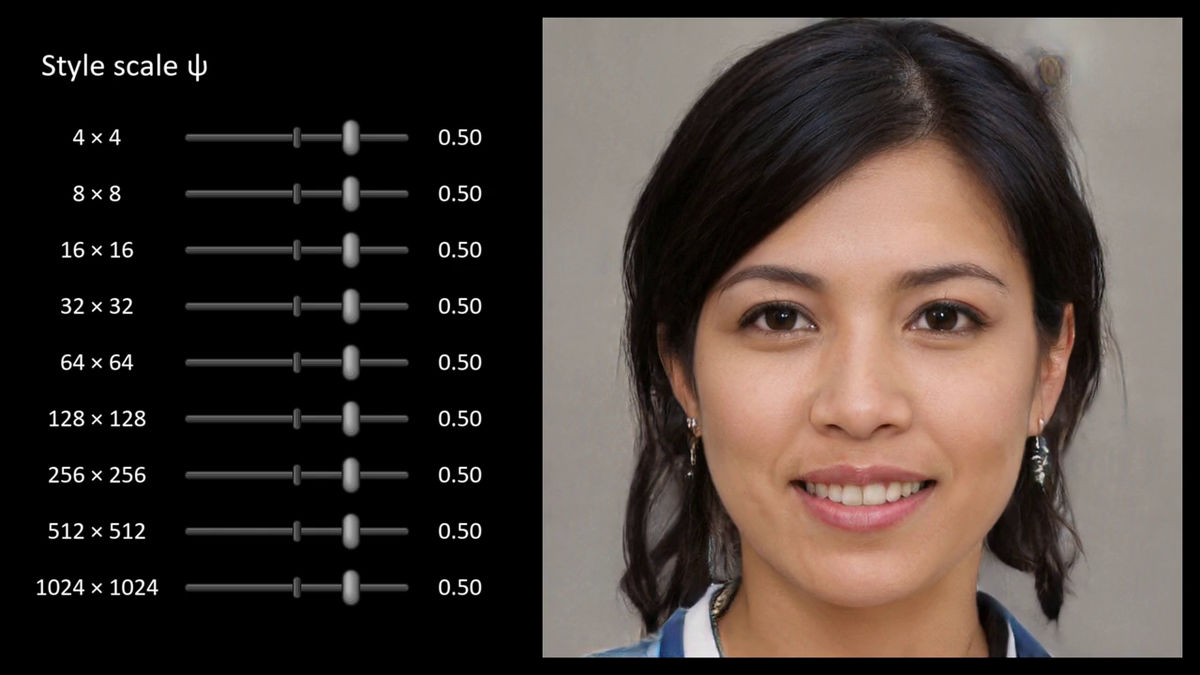
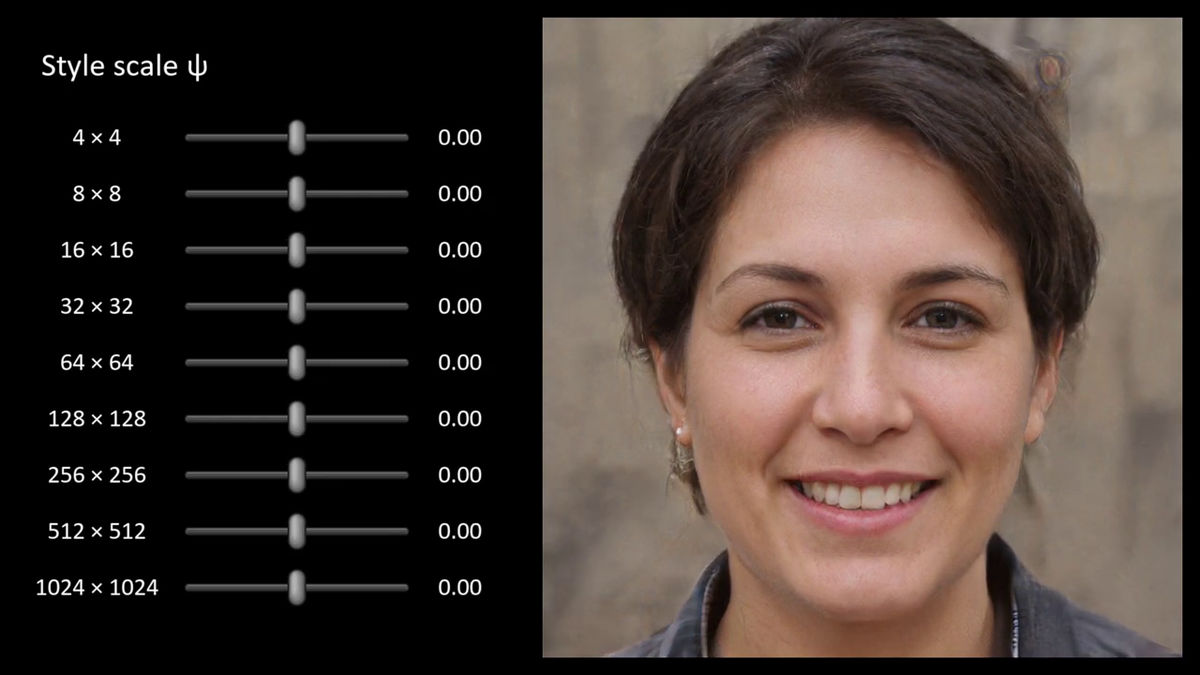
The generator can freely adjust the application strength of each style against the average face generated.

How the photograph changes depending on the strength of the style is as follows.
High strength: Maximum variation, some photos may be broken
Low strength: Reduction of fluctuation, adjustment in a range where the photograph is not broken
Negative strength: opposite face
When the strength of various styles is the maximum
When the strength was slightly reduced
When intensity is zero
When it got negative intensity, the gender was reversed.

When the strength of various styles is zero, what is displayed is the average face generated by the generator
It changes to a different face for each strength of each style.


"By choosing reasonable intensity, variations will be reduced and it will be possible to generate good images."

Examples of photo generated by the generator are as follows.


If you change the data set, it is also possible for the generator to generate non-human images. Car and bedroom, cat etc.

Changing the "coarse style" changes the arrangement of cars and beds ......



Changing "middle style", the decoration of the car and the bed changes ... ...



Changing "fine style" will change the overall color as lily.



Related Posts: