This is the back side of Wikipedia, the state of large-scale system which is not known "system operation in Wikipedia / MediaWiki"

Speaking of Wikipedia, it is a huge site boasting the number 5 visitors in the world, but only 6 people in the world who are involved in system administration, and this is a terrible small number of volunteers, including the 4 th Facebook server While the number exceeds 30 thousand units, Wikipedia operates with only 350 units ... and so on, the fact that Wikipedia is unknown now is "KOF 2010"Today's lecture"System operation in Wikipedia / MediaWikiIt was revealed by.
Ryan Lane who is an engineer of the Wikimedia Foundation who runs Wikipedia, has seats with 100 seats full and it is a thrilling place full of people to the next relay room and the contents to be spoken It was often used as a reference and it was content that could be used for future GIGAZINE servers.
So, the contents of "system operation in Wikipedia / MediaWiki" are as follows.
State of the venue

Lecture will start shortly

Beginnings begins. According to the organizer, it is probably the first time that a detailed lecture will be held on Wikipedia server operation in Japan.

Ryan Lane is on the left

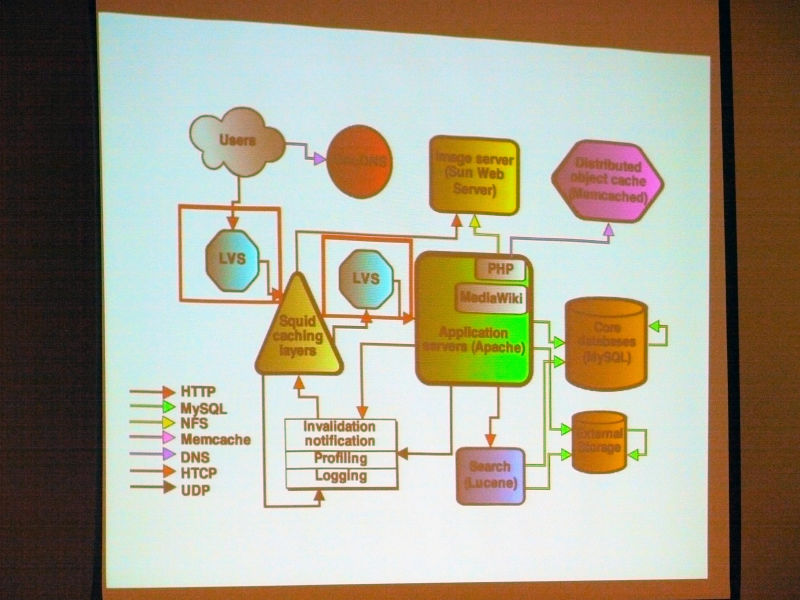
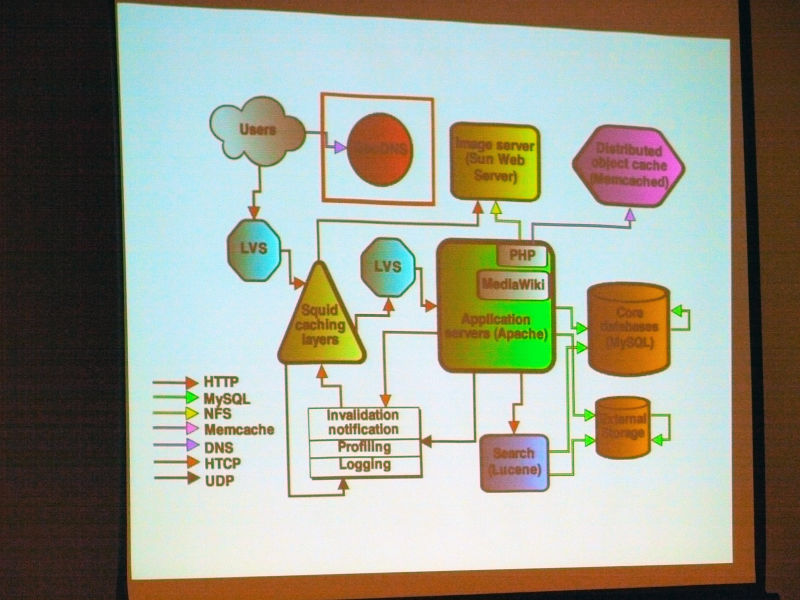
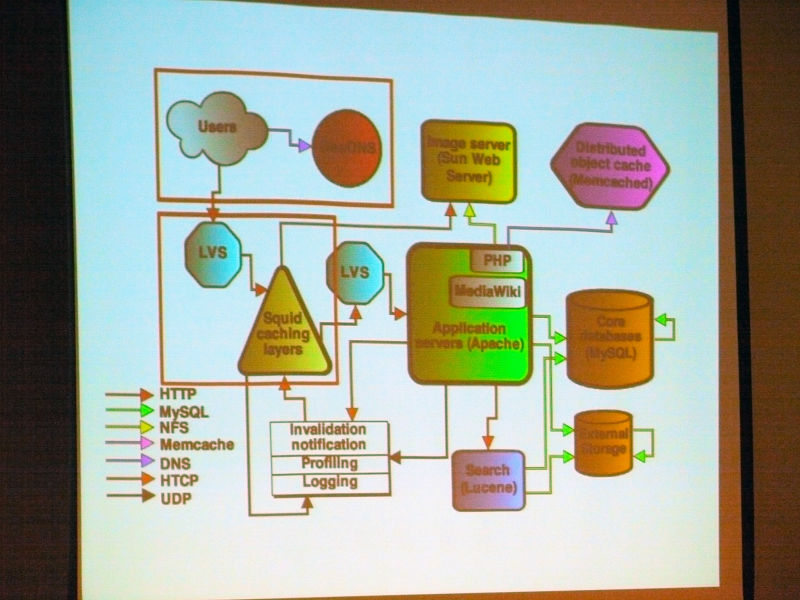
Overview. "Introduction" "About technology operation" "Global architecture" "Application server" "Cache" "Storage" "Load balancing" "Content delivery network (CDN)" has become.

About the top 5 sites in the world. 1st placeGoogleHas 920 million users, revenue is 23 billion dollars, the number of employees is 20,600, the number of servers is over 1 million. Second placeMicrosoftHas 740 million users, revenue is 58 billion dollars, the number of employees is 93,000, and the number of servers is over 50,000. 3rd placeYahoo!Has 600 million users, revenue is 6 billion dollars, the number of employees is 13,900, and the number of servers is over 30,000. 4th placeFacebookHas 4.7 million users, revenues are 300 million dollars, employees are 1,200, and the number of servers is over 30,000. And the fifth largest Wikipedia has 3.50 million users, 20 million revenue, 50 employees, 350 servers, and it is a very low category except the number of users.

Ryan Lane:
"I am watching the top 5 sites in the world by the number of users, but it shows that there is not much difference between the top and bottom Wikipedia.But actually resources, such as the number of employees and the amount of revenue You can see that it is managed with very little sales and few resources.Wikimedia Foundation stated 50 staffs in the handouts we distributed, but in fact the technical staff is not 50 people , Because the total number of Wikimedia Foundation's staff, including staff, is 50 people, do you know how many people are actually engaged in Wikipedia's system operation? "

(3 answers including 10 people, 5 people, 3 people come out from the hall)
Ryan Lane:
"In fact, there are six people.There are six people together with the staff who receives salaries and the volunteers are doing.This six people are Australia, the Netherlands, the United Kingdom, the United States etc. Although it is in a state of being scattered around, as there are not yet one in Asia at present, I am waiting for someone who will definitely come. "
Operation. Currently managed by six engineers, historicallyad hoc"Firefly extinguishing mode", technicians are scattered throughout the world, and someone is always up ... ... is "On call"None. It corresponds to the decision made by the community participants.

Ryan Lane:
"However, even if something happens because it is scattered all over the world, someone is getting up so we can take action, but because of the small number of people, There is also the case that shortage of expertise happens even if someone is awake and can deal with it in case of trouble.
Even from the history of Wikipedia, these six people are a lot of people, originally 100% volunteers, and there was a state that there was none of the staff as it is now. Even though it is said that they started recruiting staff, they are not necessarily remembering the spirit of volunteering and are currently recruiting people who will help volunteers. "

Ryan Lane:
"Because members are scattered around the world,IRCYaMailing listBecause there is a public disclosure, there is little occurrence of lack of communication among the members. Basically, we publish mailing lists etc. to share information as much as possible,vendorFor confidential information such as dealing with mailing lists, we use personal mail addresses without using mailing lists, and we share information as much as possible to the greatest extent. "
Operational contact. Most of the communication is published on the IRC, documented using the wiki (http://wikitech.wikimedia.org/), And contact of confidential information with a private mailing list and resource tracker.

Ryan Lane:
"As we deal with very large information about Wikipedia, we are using complicated ones, but we handle basic parts with general techniques"
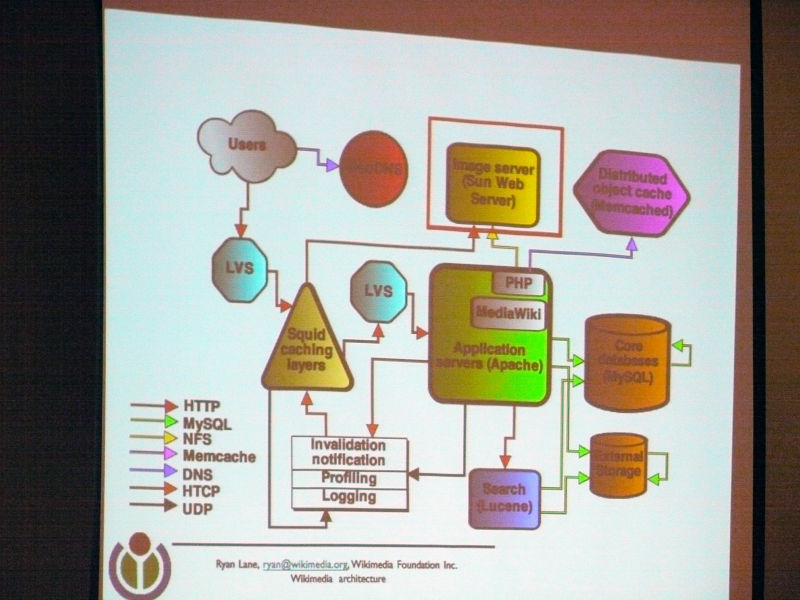
The architectureLAMP(Coined word consisting of acronyms that collectively refer to Linux as an OS, Apache HTTP Server as a Web server, MySQL as a database, Perl, PHP, and Python as script languages)

The result of repeating doping
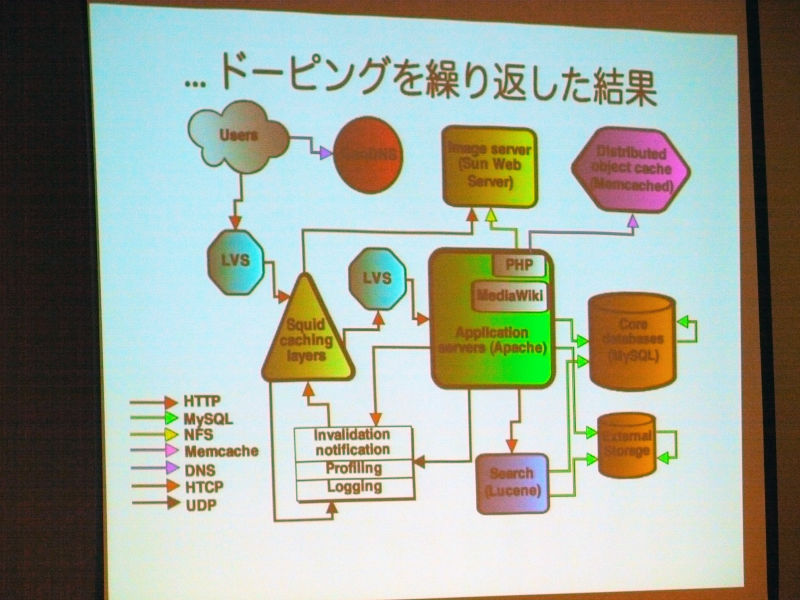
About the Wiki engine. All Wikimedia projectsMediaWikiIt is originally designed for Wikimedia. Very scalable. Open source written in PHP (GPL).

Ryan Lane:
"First of all, I will explain about MediaWiki.This is the engine used for all Wikimedia sites about this MediaWiki.
About the sister projects of Wikipedia and Wikipedia, Wiktionary (wiktionary.org), Wikibooks (wikibooks.org) etc, I use MediaWiki as the basic core, but since the functionality is different, We are dealing with it. It has very high scalability and high balkarization, so it supports about 300 languages.
Regarding software, basically it uses open source, about 300 developers such as volunteers are around, and anyone can participate. "
About MediaWiki optimization. To avoid funny things, high-cost operations are cash, gaze at the "hot spot" of the code (high load point) (profiling also!), If MediaWiki's functionality is too heavy, it is invalidated on Wikipedia.

Ryan Lane:
"It will talk about how to optimize Wikimedia, but first of all it is commonplace, as it is commonplace, such as" do not do stupid things and stupid things " . How you are doing optimization is that you are using caching first and trying to use caches when preparing caches is easier than preparing data. Another part of the foundation is profiling, which is to do the job of profiling and finding high loads in the data, to improve efficiency. We are doing optimization using two caching and profiling methods. "

About MediaWiki Cache. It caches everywhere and is a distributed objectMemcachedMost cache data.

Ryan Lane:
"We develop it with the attitude that it caches everything as much as possible and caches those that can be cached rather than having to create from everything from 1, such as from the user's session, user interface by language, etc. I am doing it.
In the example of PHP, we do a special method,APCWe are caching using the technique. Originally in PHP it will be executed through the interpreter, but by caching bytecode through the interpreter, even if there is the same request again, it will not be executed again, so it will be faster and another As an advantage, since the cache is read from memory, APC has the merit of becoming faster.
Also, I use Memcached as caching. When the user makes a paging, it caches everything from the rendering and saves it in memory, so the next same request will be retrieved from the cache the next time. "
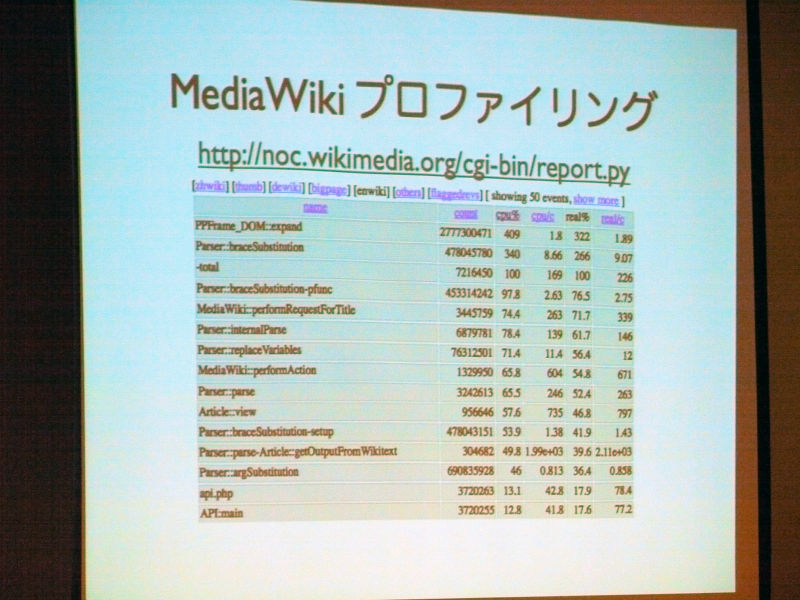
About MediaWiki profiling.http://noc.wikimedia.org/cgi-bin/report.pyYou can browse by accessing.
Ryan Lane:
"Profiling is implemented as a basic function in MediaWiki, it can be recorded as a UDP packet of a file or a database, it can find out where load is being applied, and it is always moving, and by constantly moving it , When adding new features etc., it is possible to find out where a problem is occurring urgently "
About MySQL.
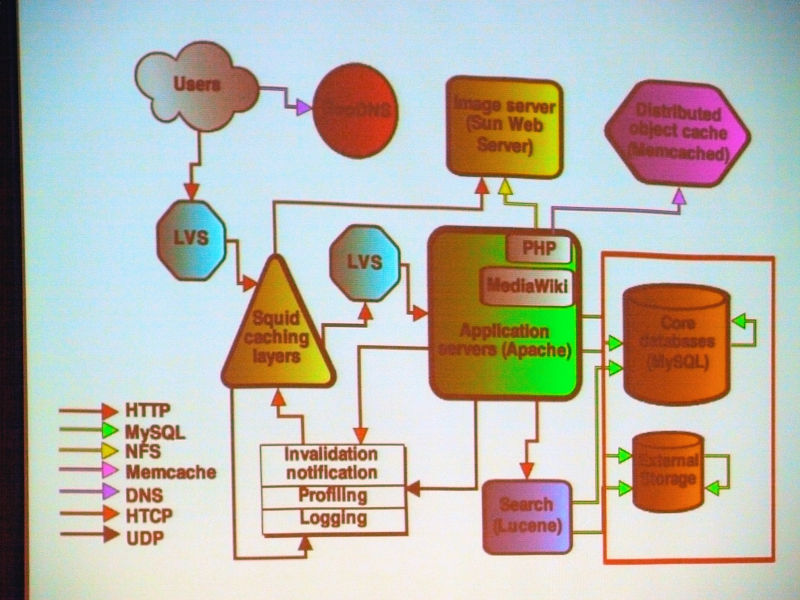
MySQL in the core database consists of a lot of replicated slaves in one master, read is load balanced and goes to slave, write goes to master. There is a separate DB for each wiki, and for a huge and popular wiki it is separated from a small wiki (sharding).

Ryan Lane:
"We are using MySQL for our database, and consider it as MySQL which is generally used.
As a configuration, one master is made to have a plurality of slaves to speed up, and when writing is done, it is always done to the master, but when reading it, Since loading the server load-balanced, it is possible to increase the speed.
Also, by separating the database for each wiki, we prepare multiple servers for large wikis and prepare different servers for small wiki gatherings. This is called "shearing". "
About Squid.
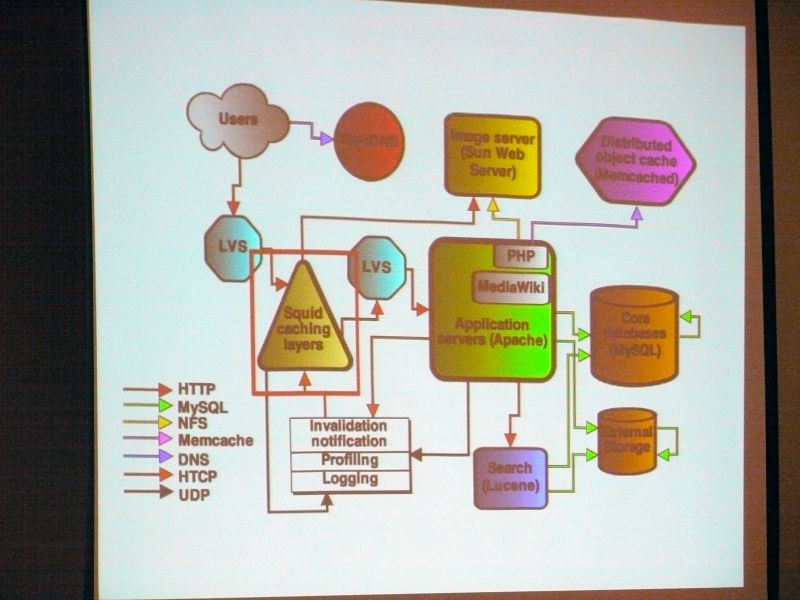
Squid caching caches the reverse HTTP proxy and is responsible for most of the traffic. It divided into 3 groups, and by using CARP, hit rate achieved 85% of text and 98% of media file.

Ryan Lane:
"Caching is a core system for the Wikipedia system, and it will be possible to support users with very few resources.
The Wikipedia system has a high dependency on caching, currently 50 million users, but since there are about 200,000 people actually editing, most of the traffic is read out, It is possible to optimize relatively easily. In that case, we are using Squid to read the cache.
About the cache, it is divided into three, and text, a media file, a data file called "Bits", and the architecture are divided into these three kinds.
For text, most are HTML files. Media files are still images, movies, sound files, etc. Bitz is a small file, for example JavaScript or CSS.
We use this algorithm as Carp to achieve a hit rate of 85% for text files and 98% for media files. "
This is CARP
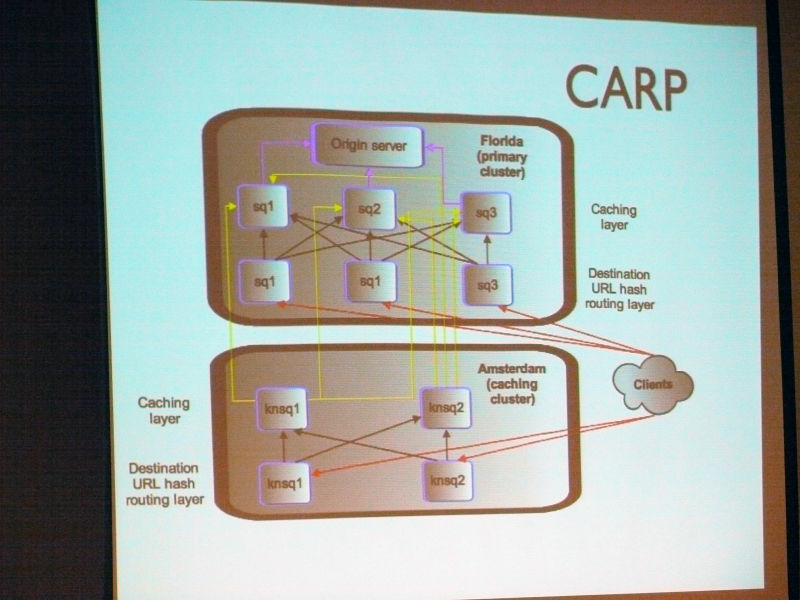
Ryan Lane:
"As a mechanism of Carp, when making a client request, a hash is created for the URL, and the hash is set to a numerical value, and a predetermined server exists within the range of this numerical value, and the range of the hash value It is feasible to directly access the server that is responsible for it.It is basically only one hash for one URL so it will be allocated to the server with that link, It is realized that it is allocated to the server.
This figure also represents the data center. "
Ryan Lane:
"The above data center is the primary data center and all requests are accessed first to the primary data center and eventually it will be accessed to the origin server if there is no cache there. There will be no origin server for the second data center, but if there is no cache in this request, the request will automatically be sent to the main (primary) data using Squid We will go to acquire data to the center. "
About invalidation of Squid cache. Wiki pages are edited with unpredictable frequency. The user must always see the latest version. It is not possible to use a certain expiration date. Disabling caching by squid implementation using multicast UDP based HTCP protocol.

Ryan Lane:
"As for Squid's cache invalidation, if you edited data, basically the user expects it to be reflected after you press the save button, but it is a method that is often used to populate the cache When using the method to reflect it to the cache after a certain period of time elapses, it will not be used as it will not be reflected immediately, so it is useless to use the expiration date as a means of invalidating the cache For that reason, we use a means to invalidate the cache every time it is saved, without using the expiration date of the cache.
Previously, in order to invalidate this cache, since it was not possible to use the expiration date method, after performing the editing work, one connection is made to each cache server of each Squid individually, and the target I was doing work such as invalidating the cache, but this method gradually disappeared because the load increased as the number of users and the number of edits increased.
After that, the staff could think of using the multicast of UDP packets, it became very efficient, as it was possible to invalidate the cache to all servers at the same time.
However, since Squid's cache system was originally a forward type proxy rather than a reverse-type proxy, there is a historical background that it was forced to use it as a reverse-type proxy in operation "
VarnishAbout caching. It is currently used for delivery of static contents such as javascript and css (bits.wikimedia.org). In the future we plan to replace the Squid architecture, which is twice to three times as efficient as Squid.

Ryan Lane:
"Gradually, we are beginning to migrate to use a new solution called Varnish, which was originally developed to do reverse proxy caching, which is two to three times more efficient than Squid's proxy Currently we are already using Varnish for Bits' cache. "
Next is a media storage server.
About media storage. The current solution is not scalable and we are considering many solutions. It is fun to look for an open source solution.

Ryan Lane:
"Next, regarding media storage, it is a server that handles still images, movies, sounds, etc. However, there is a historical background and it is the only part that does not use open source.
Actually, the identity of this media server is SUN's Solaris. In reality, what I was going to use temporarily, there was not anything to replace it easily, so it has become a background that I still use it.
Regarding this Solaris system, it is currently in a completely unscalable state, and it is possible to process about 100 requests per second as the current capacity, but in a state where it is always loaded And it took about two weeks to take a backup, and it has become a state.
Since this system using Solaris is not using open source, it is difficult to devise ourselves and make improvements, so we are looking for a solution that can now diversify alternatively instead However, since there is not a deciding factor of this, it is at the stage of reviewing and investigating, so I think that those with good ideas would like to participate. "

About thumbnail generation. Since it is too heavy to stat () all requests, it is assumed that all the files exist. If thumbnail can not be found ask to create on application server.
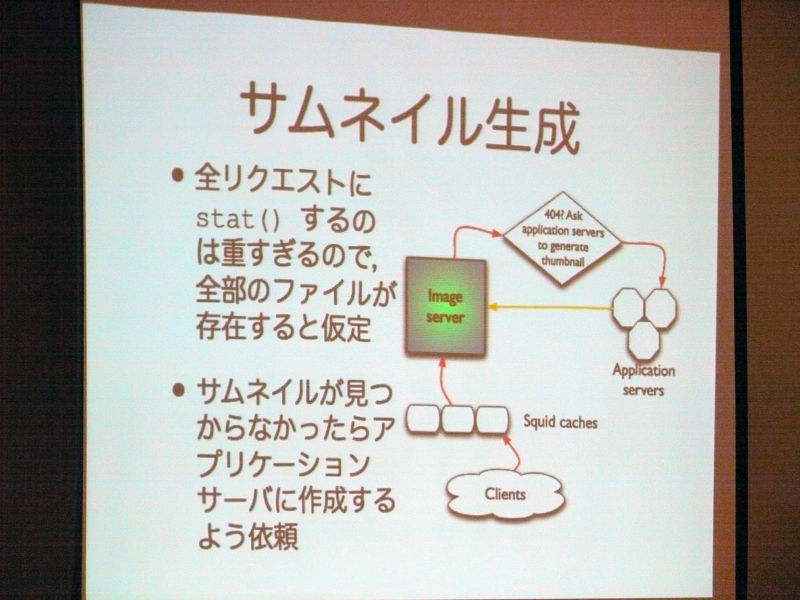
Ryan Lane:
"About next thumbnail generation processing, it is a very heavy processing, and there is a background that it takes time just to check whether thumbnails exist using the stack every time.
As a method of avoiding this, when considering what is present, even if the thumbnail actually exists or does not exist, we treat it on the premise that the thumbnail already exists. If the cache actually exists, it will be returned, but if the cache does not exist, it will return a 404 error if normal, but instead of returning a 404 error, insert a handler when a 404 error occurs, If there is no actual cache, it creates and returns a thumbnail.
Therefore, even if thumbnails actually exist or not, assuming that "thumbnails are actually present", if there is a cache, return it, if the cache does not exist, it will be generated I will return it. "
Next is LVS.
Ryan Lane:
"Nearly all Wikipedia servers are clustered, but loading balancers are obviously required for being clustered, among which the method changes with application server load balancing and other load balancing I would like to explain about LVS this time.

The load balancer is LVS-DR, Linux Virtual Server Direct Routing mode. All real servers share the same IP address. The load balancer allocates the upstream traffic to the real servers. Downstream traffic directly arrives.
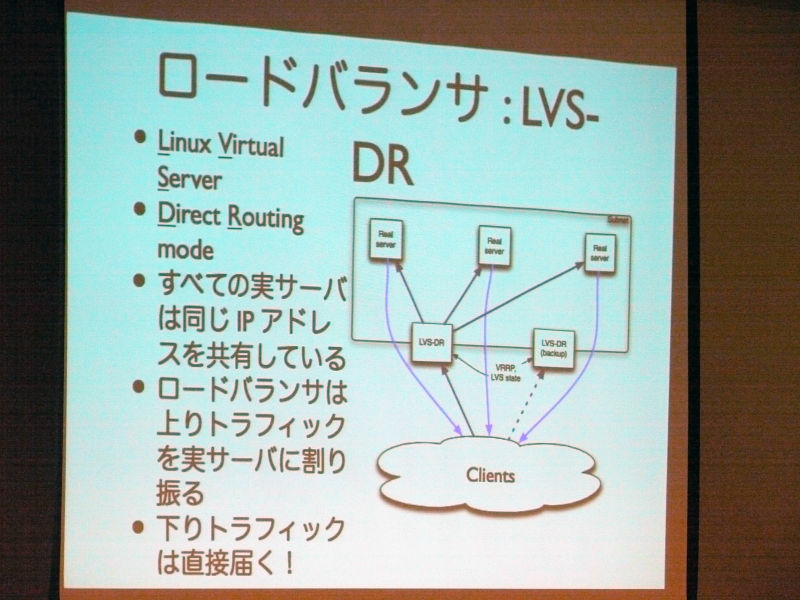
Ryan Lane:
"LVS is an abbreviation of Linux Virtual Server, but it is used in DR mode (direct routing ).DR mode is very efficient and there is also a relation, and even among the weak Pentium that we have in the Wikimedia Foundation We use it because it demonstrates sufficient performance even with old server such as 4 single core.
Describing this mechanism, the director receives the client's request and performs load balancing to distribute it to each server, but because it is done at the layer 3 level, it is very efficient. Even more efficient is not returning through the director when returning a response, because all distributed servers share the same IP address and will respond directly to the client without passing through the director Efficiency is getting better. Even about the entrance, a network interface of about 1 Gbit is sufficient, and it is a mechanism that can return things with a large total amount of data in response to many small requests. "
Ryan Lane:
"Until now, we have talked about the operation of a single data center, but in reality there are multiple data centers around the world and we want to supply it as quickly as possible, To put it briefly, we would like to place a data center near the user. "
About content distribution network (CDN). There are 2 clusters on two continents, the primary cluster is Tampa, Florida. The secondary is a cache only cluster to Amsterdam. A new data center will be added to Virginia soon.

Ryan Lane:
"As the Wikimedia Foundation currently has two data centers, the first data center is located in Tampa, Florida, USA, and the second and secondary data center is located in Amsterdam, The Netherlands Is a cache only data center.That is now trying to make a new one in Virginia state of America as the third data center and if this is done it will form two primary data centers.
In the secondary data center in Amsterdam there is only a subset of the whole system and it consists of what is necessary only for caching DNS, LVS and Squid. "
Load balancer part.
Ryan Lane:
"As an issue, how is it to guide users to a nearby data center?"
About geographical load balance. Most users use nearby DNS resolvers. Map resolver's IP address to country code. Return CNAME of near data center depending on country. Use PowerDNS with Geobackend enabled.

Ryan Lane:
"Most users are using the closest DNS they are using.When a user tries to access the English version of Wikipedia, a request is made to the local DNS set by the user, and further to the higher DNS It is a story of a general DNS flow that connects to Wikipedia's DNS server and returns an answer, but a request comes to the DNS resolver and has a list such as to link the user's IP address by country on Wikipedia Therefore, when using it and returning a response to the user, the method of returning a response with the CNAME of the nearest data center is adopted.
Then, after receiving a request from the user, it looks at the IP address of the DNS resolver used by the user, roughly identifies the location and returns the data center of the closest country as the IP address of the server, so from Europe In response to a request for a European server IP address, if requested by the United States at the same URL, since the region to which the DNS server you are using belongs to the US, the IP address of the server you return will also be the one from the US It will be in the form of returning.
As a way to accomplish this, we use PowerDNS and further combine the option Geobackend. Although it is open source for PowerDNS, it is not originally developed as DNS, it was developed to do IRC on a global scale, but this means that it can be used as DNS, and for the IRC It will be a solution applied for DNS for those developed. "
in conclusion. It depends very much on open source software. We constantly pursue efficiency and are looking for more efficient management tools. I am also looking for volunteers.

Ryan Lane:
"Last but not least, we are a highly dependable open source system, it's an organization, it's a highly dependent organization for the open source community, for example bugs If there is a problem with scalability,
It is possible to get in touch with people who are directly developing, but it is impossible if you use commercial software. "

Ryan Lane:
"We are constantly pursuing to increase efficiency as we constantly aim to maximize performance with fewer resources and we are also improving tools for management at the same time There are roots as organizations that originally started with volunteers, so it is unchanged that we are looking for volunteers who can always cooperate. "

Ryan Lane:
"Thank you very much"

Related Posts:






in Hardware, Software, Web Service, Coverage, Posted by darkhorse