The author himself tells the merit and history of "Apache Hadoop" used on Twitter and Facebook

It is a Java software framework that supports distributed processing of large-scale data, and is distributed as "free software"Apache Hadoop". The author Doug Cutting (Doug Cutting)Cloud Computing World Tokyo 2011"&"Next Generation Data Center 2011I went to ask because I was talking about "Apache Hadoop: A New Paradigm for Data Processing".
A crowded audience.

I am honored to be able to give a lecture in front of everyone. We will tell everyone about "Apache Hadoop", but this is exactly the new data processingparadigmI am thinking that it will provide you.

First of all let me introduce myself. I have been working in Silicon Valley for over 25 years. I worked for several companies, but I originally started working at Xerox Park, then afterwards with Apple's Mac OSSpotlightIn the 1990s, I was in charge of web search at Excite and I worked at Yahoo! when I was the nearest.
Let 's talk about what kind of research actually did. Especially for the last ten years I have been involved in a series of open source projects. In the free time of 1997 I tried to develop a search engine named lucene, I was under SourceForge that opened up as an open source project in 2000, and in 2001 I was invited by the Apache Software foundation. Since then, I have been involved in several projects with the Apache Software foundation. In 2003 after lucene, we launched a project named Apache Nutch. I think that it was a rather ambitious project by saying "open source function" and "web search engine development". This project is still ongoing for the purpose of doing something comparable to what Google and Microsoft came with open source projects. And in 2006, we developed a part of Nutch as a new project, "Hadoop" was born. Details of this will be explained later. Currently I work as an architect at Claudela. Also on a volunteer basischairmanI also enrolled in Eiseph.

I will move on to the subject of "Hadoop" from now on, but I'd like to easily talk about the possibility of "Hadoop" before that. Data is increasing more and more than ever. Why is it increasing? One reason is that the cost of storing data is getting cheaper. Hardware cost has also declined over the past several decades and will continue to be even cheaper in the future. The price of the CPU is also decreasing. As consumers began to use PCs more and more, the price has steadily declined. However, how about traditional database technology? I have not said about this momentum.
What if we were to purchase hardware for traditional databases? In realityCommoditizationIt is higher than the PC hardware that was done. The computing power is also the same, or even the same capability as a PC becomes high although it is the same. Also, the scalability of enterprise technology is a problem. To thousands of computersScalabilityIt is quite tough. In other words, it is currently difficult for foreseeable and transparent scalability in large data centers. Just now it is a branch point. In reality, although it should be possible to make the price cheaper, in fact, there is a deviation from what is provided by the conventional type. And I think that there is a chance for this divergence. However, although it is a great opportunity, it is quite difficult to take this opportunity as a thing. Needless to say, scaling reliably on thousands of computers is quite troublesome.

Please try imagining here for a moment. We have to do petabyte equivalent data storage with thousands of drives. That drive may break down about once a year on average. If thousands of drives break down once a year, it is calculated that something is broken like every day. In other words, something is broken every day. However, the system that you are developing is the current situation that you have to keep operating smoothly in anticipation of such a breakdown. That means that you need something that can endure effectively as a storage system. We must respond quickly to failures, be useless without interrupting the process, and of course high availability must be guaranteed. Even if a part of the hardware drive fails, HD (hard disk) must be secured. It also requires a fault-tolerantly designed computing framework. Therefore, even if the hardware fails somewhere, it is necessary to carry out the work smoothly in a fault-tolerant environment without being affected by such failures.

Actually there is another problem. As the cluster grows, the cost of transfer increases. Certainly the network has become quicker. However, if you do not dare to do data inspection on the network speed can be secured. For example, suppose we needed a process with 100 terabytes of data set. There is a cluster of 1000 nodes. Imagine reading datasets from each node to another node over the network. Let's assume that each node can communicate with other nodes at a speed of 100 megabits at the same time. How about that? All data sets will be processed over the network over 165 minutes. On the other hand, what if the data were on a local drive? Then you can read the data more quickly. If it is the current drive speed will be about 200 megabytes / sec. Converting, it means that it takes only 8 minutes to read all the data. Therefore, the theory here is that it is actually more secure to process data on the same hardware by reversely using this processing capacity than moving data.

Today I will focus on "Hadoop", but I am thinking that "Apache Hadoop" is just the answer in data analysis, while there are such challenges and opportunities. You can scale to thousands of commoditized computers and you can control all hardware properly. All cores, CPU, even hard drive, spindle etc. are working properly. While properly performing Read / Write, it is guaranteed that it can be processed effectively. So you can use computing power continuously and efficiently without waiting for other components.
This will be a new software stack. Moreover, it was developed based on several different principle principles. Actually, it has already been adopted by many companies, and the major Web companies in the U.S. such as Facebook, Twitter, Amazon and eBay have already adopted "Hadoop". And the proportion of adopting "Hadoop" even outside such web-based companies is increasing rapidly.
So I told you that it is a new platform, so I will dare to introduce it to everyone by dint of five. Because I think that this is the characteristic of the new paradigm. First of all, "commoditized hardware". I will touch on this later. The second is "sequential file access", sequential file access rather than traditional random access. And it means that "parting" and "parting" automatically, data compaction regardless of a large machine. Furthermore, "We will recommend automation while guaranteeing reliability". On the premise that hardware is sometimes broken, it means to incorporate reliability into the software on the hardware. And the fifth is "to be open source". This is a common boom in the phenomenon of a new paradigm. And I believe open source is evoking various events.

Let's start with the first "commoditized hardware". What is "commodity" in this case? Things that are installed in PCs such as CPUs, hard drives, and memory dramatically reduce costs, and the performance has improved significantly in the past 10 years. I use it in a specific way when using it in "Hadoop" environment using commodity hardware or when using it in a data center. There are simple diagrams, but there are also ways to utilize it while using large racks and nodes.
For example, there are 1 to 4 CPUs in one node, some memory is allocated to some extent, 2, 4 and 8 hard drives are installed, 2, 4 and 8 are allocated for each node There. Then, install it in a rack, and it will fit about 20 or 40 nodes in a rack unit? Each rack has a network switch, and the nodes on this rack are connected here. Each switch is connected to a higher-order switch, respectively. This will connect all of the racks further. Well, it is said to be a very typical configuration. Therefore, if you move the data from place to place, you can move and read the data on the same rack easily and effectively from the local disk on the node effectively. However, there is a slight delay when reading data from other racks.
Well, this is the cost, but this is also an important point. It is a very reasonable price. This is for storage and processing power. Scalability can be tens of thousands of machines, and performance will also increase linearly. For example, it is also used in 10 nodes, 100 nodes, 1000 nodes or more.

I would like to talk about another principle. The next element in this new paradigm is "sequential file access". The full text index is the content that I got about in the 1980s, but I learned how to make indexes while looking at textbooks and textbooks, and I learned about Bettley at that time. This will be the basic technology of the UK database. And based on the principle of logging access to the hard drive, "about all updates", "do it for Bettley". But this is a disk seek. Because random access is a seek of the hard drive. For the past few years, seek time has not shortened. As an element of the performance of the computer, it is this seek time that is not being promoted elsewhere, I think that this is exceptionally increasing. And this "seek time = useless time" is what. So when updating and accessing frequently, this beatry is very slow and slow.

This is what I myself noticed in the 1980s and 1990s. I was working on web search at Excite, but the only way to effectively build the index was to use the patch system instead. We took the approach of sorting large databases, updating them, sorting updates, and then merging the updates with the database to create new versions. Merging sorted in this way was treated as a batch process. If so, it will be all sequential. It becomes sequential eye operation. Then, in the case of this large index operation, it can be made as fast as 10 times and 100 times. I also used the same principle for lucene. Then, the time of transmission, and the time when data is being read / written occupy most of the time. And I was able to reduce wasted time called seek time. This means that you can fully receive the benefits of currently available hardware.

I would like to talk about the next element. It is the aspect of "open source". Open source came to be seen many more in the last few decades. Many companies are understanding its mechanism. I think the biggest advantage is cost reduction. One point is that software is free and provided free of charge. Then you can significantly lower development costs. In other words, it can be borne by multiple companies collaborating that cost. The same is true for tests and QE. After that we can collaborate with other companies when documenting and documenting, so we can divide the burden. Then it can be said that open source can do better software. For example, it often happens that a job of higher quality is made by conscious that "as many people are watching" when the developer writes something. Also, by becoming conscious of being using other companies, not just using themselves or your own company, you will be making more generic things. It is not enough to meet your needs in the short term. Others are not interested in such things.

Even if you decide to get a consensus for changing software, for example, it can not get a consensus unless it is commonly available. That's why software will become higher quality. Then, as another advantage of open source, I think that the satisfaction level of the employee is raised. That is motivation. I feel motivated because I can show respect from my brothers and colleagues. That is very important. Rather than working with a team of two or five developers gathered, I feel motivated by working with 100 developers. If you change jobs and go to the next workplace, the connection with those people will not go away. You may get to work with them throughout your life. Having respect from those people, being motivated to have them at a glance makes me feel fun at work. I myself have witnessed it. Various people like to work on open source projects for these reasons.

I have been working at the Apache Software Foundation for more than 10 years but as the last point I would like to mention here that open source is "just to provide free software and to disclose the source code" It is not. It also means to build a collaboration community. And we must ensure that these communities are going around properly. Apache is looking at it. I think the community needs diversity. It is troublesome for a project that one company controls. Every developer gets an equal opportunity, the political aspect is gone, it will become a purely technical project. The place called Apache is an arbitrary organization that the developer controls, and it is by no means one company dominates the organization.

Let me explain the other factors. Various things related to the history of "Hadoop". Nutch started in 2002. Since this Nutch was necessary for building the database on the web page, we shard the database with the URL. In other words, it is part-scheduled, to divide the database into multiple parts. We will do this based on the hash code of the URL. Then we put each segment of the database on different nodes of the network. Then we will do batch-based processing. This is a glance at a glance earlier. For example, suppose a new page has been crawled. And if you want to update the database with the link of the new page including the link to which page you want to update, please divide the new URL and update based on the hash code of the URL, It puts it in one file per copy, copies the node, and it does the thing of integrating it with the existing database for the node having the shard.

It is very extensible, it can correspond to most databases and efficiency is also good. I need to take these steps, but I have done it manually. Although there was an extensible algorithm, it was pretty hard. A person in charge could run it with four, five nodes, but I could not deal with it any further. For example, there are various malfunctions, the problem is that the hard drive becomes full, and the manual work of copying this data was hard anyway.

In 2004, it came out that Google issued several papers. This is a paper on how Google is confronted with the same problem and how it solves it. In fact, Google used a similar algorithm. Google was automating it. I had such a system. Google File System, MapReduce 's computing framework, various papers that wrote about these things, but I wrote about automation about distributed sort merge. And then Google also automated the handling of reliability. It is that it can respond to it automatically when there is something wrong. I began doing something like "Looking back to something else if the disk becomes full". Again I thought that open source should also be this way. At that time, only Google had this kind of tool. So I thought that this was necessary even for open source, and the effort to provide it was started.

Two people, me and Mike Cafedela, have been doing these work for several years. This has also continued development with our free time, but I expected that it would take a considerable amount of time to realize this, probably it would take thousands of computers with reliability to do . I went up to 20 cars. It is possible to guarantee the reliability so much. However, as I mentioned at the beginning, it is hard to develop reliable distributed software.

So in 2006, I began dialogue with Yahoo! and Yahoo! showed interest. There is such a problem, is not it? And they showed interest in adopting the software we developed in Nutch as a platform. Yahoo! had a fairly large engineering team, and many engineers were also interested in it, so I joined Yahoo! in 2006. And a project called "Hadoop" was born. Distributed Map System, and then pulled only MapReduce, these new projects are born.

Let's briefly introduce HDFS and MapReduce here. HDFS is an abbreviation for "Hadoop Distributed File System", but its extensibility is very good. Files can be shared and committed neatly with commodity hardware, and very efficient. Read / Write is also effective and cheap. Hardware cost and cluster operation can be done at relatively low cost. How about reliability? Almost all of the reliability is automated. Because each duplication is done to each of three data nodes in each block unit, there is little establishment that data is lost. Clusters have been implemented for years without losing data in Yahoo !. Data is automatically rebalanced as well. If one drive becomes full or the hardware fails, duplication is automatically done to other nodes. Not only do it all automatically, but also monitoring is done automatically. There is a file system, single master. Name node. However, since there is a hot spare in this single master, I think whether there is little that availability is affected even if it fails, by any chance, even if it fails.

I would like to briefly describe MapReduce. Although it is simple and simple content as a program model, it has the feature that it is easy to combine parallel environment in most clusters because it is versatile of common pattern program. I will go from the left side. First we capture the input data and cut it by chunk.
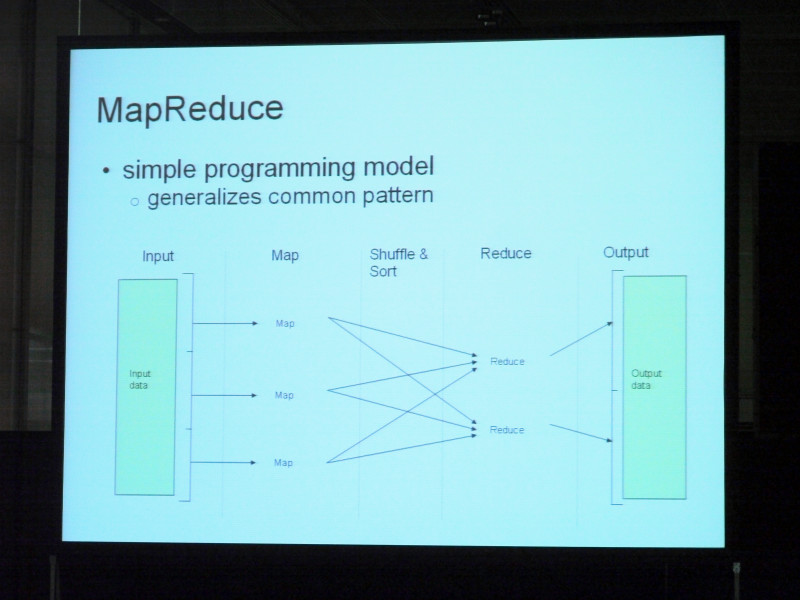
Although it is divided into three for reference here, it will be carried over to the user-defined map function for each chunk. Using this map function, we will process each data item and item, and generate keys and value pairs. The output of the map function is sorted. It will be handed over to the user-defined reduce function in output unit of the map function more and more. Therefore, when the keys A, B, C are generated from the map function, those corresponding to A are handed over, and those corresponding to B are handed over to the reduction function here. And all of A pairs are taken over to the Reduce function here at the same time. And we will inherit this iteratively and reach collective output. It is very simple as a programming model, and it is possible for two users to insert and use application code in map functions and reduce functions. Actually, it is proved that you can do all kinds of things by using such a way.

Even if it is a large cluster, it is guaranteed to fully utilize the hardware. You can also sort and merge, and can handle other algorithms converted to other metaphors. I would like to mention only a few points about this MapReduce. MapReduce's compute node is the same as HTFS storage. It will be implemented on the same cluster. Therefore, you can read from the local hard drive and write it to the local hard drive. From there we can duplicate through the cluster. In most cases IO can be handled locally. The throughput for the CPU and the hard drive is guaranteed as much as the hardware equivalent while increasing the availability. So if you have hundreds of hard drives, there is something that is quite amazing, as the data processing capability is 4000 if you have 4000 speeds. Most sequential file access is used, and sort merge is directly supported. It supports sort merge type of competition. Also, as mentioned in the third section, reliability and scalability as expected will be automated.

We briefly introduced MapReduce and HTFS, but it may be said that there are rare cases when only the kernel is used. MapReduce, kernel and various other communities are expanding. Various projects are emerging among these developers. We already have published books that says what other components are like, and some companies are beginning to provide support for a fee. In other words, as shown in the figure below, complementary tools are increasingly expanding on a network basis. Although we are introducing with difficulty in reading, MapReduce has just come to this center. Here HDFS. And we can read the component in a form surrounding it, and the dependency between MapReduce and HDFS which is essential in this center. Actually this figure, it is about a year ago, so one more year has become even more complicated. So management may be difficult. It may be difficult to capture all of this community. For example, Linux, two of these are kernels, there is a compiler, there is a Windows system, or there is an Office Suite, etc. Well, what constitutes the distribution of Linux surrounds it It is exactly the same idea.
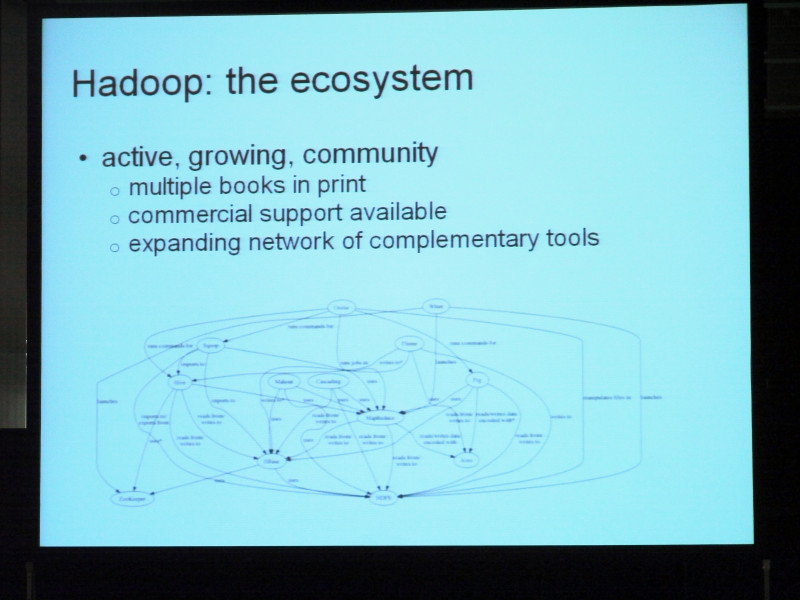
So Claudela, we are packaging and offering all components so that we do not have to introduce ourselves all the time trying to simplify such a complex community somehow. And as a distribution of Claudera, we propose something that is pretty easy to use. All components included in the Claudera distribution are open source. Distribution itself is open source free. So anyone can download it. There is also a compatible standard set of components, so even if a new distribution of Claudela is announced, it incorporates the latest version of the component project and is packaged as it is fully compatible Since the distribution is completed, I am sure that it is a great service to the community because I am following the circumstances properly. It is possible to save time for users to install components every time.

I would like to mention a little about the other components of this ecosystem, the Claudera distribution. In famous places Pig, Hive. It becomes a high-order query language, but MapReduce generation is done. Pig is an impersonal data language, and in most cases it is used for ETL tasks, so I think that it is often used to transform datasets. On the other hand, Hive uses SQL as the query language. Most of the cases are often used for data warehouse applications. I think that it is common to use such as sorting data and making queries using Hive.

Subsequently, as a famous component Avro. We propose a common data format, common data format, so that various components are properly compatible and even if one component and another component are different components it is possible to recognize each other properly. Since we are using the schema language, the data structure is expressed using the schema language. Also, since it also supports evolution of the data structure, it is also possible to read even if the addition is made, the name change or erase, or the old data set is a new code as it is Even if it is an old code, it can read a new data set. In other words, it means that there is upper and lower compatibility. Since it also contains very efficient binary coding, every data set can be represented compactly. As a result, it also leads to some reduction in redundancy.

As Avro's file format is a self-describing file, even if you inherit Avro's data file to another third party, you do not have to reference what the data structure actually is It is a mechanism that you can grasp. Avro also supports remote procedure calls or RPC systems. It also supports languages such as JAVA, C, C ++, Python, then Ruby, PHP, C #. Then you can use it with Prelude. This is to replace pre-program type programs with Avro data format easily.

The next component is also interesting, but it is Mahout. This Mahout is a library. A library of machine learning algorithms, such as classification, clustering, and recommendation engines, are supported. There are some recommendation algorithms when you want to recommend it, if you want it automatic, you can choose which one is appropriate from Mahout according to the data. This algorithm is made mostly by MapReduce. It is a very useful library.

Then it is HBase this time. This started with inspiration from Google's big table project.

It is a real-time online database, HTFS stores all the data, you can also access with the primary key. Alternatively, a very efficient scan can be applied to the data range. Since the data is sorted by the key, it is possible to scan in that order. Then, HBase has high performance and scalability. Insert can be done at the speed of writing to that node, and scanning is also possible. You can sort at the same speed as reading from the hard drive. In other words, it has high performance and scalability. You can also use it with MapReduce. You can adapt to the MapReduce job with the HBase table as input, or you can write the MapReduce output back to HBase.

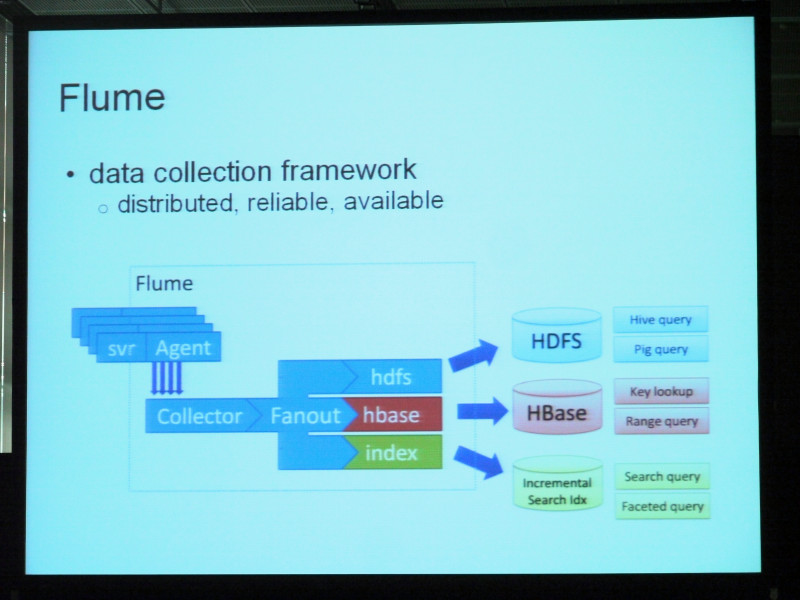
Next component, this is also funny. Flume. This is a data collection framework, data collection framework. It focuses on reliability and availability. Normally it is log data and other real-time event data may be acceptable, but Flume stores the agent in the server that generates the data and transmits it to the common place. Then we do the processing there. Common thing is to transmit data to HDFS. I will use Pig or Hive to search archives from there, but if you do not, I can also send it to HBase. Then it will be possible to access the event online, otherwise send it to some search index, search index, track recent events and track it on the search interface You can. If you can send them to one of them anyway, you can send it to three as shown in this figure. That is Flume.
As far as I've seen in years, I think there is a pattern in adopting "Hadoop". In terms of a typical pattern, installing the "Hadoop" cluster first is for a specific application. A dataset that can not deal with that application in other ways has a problem, for example I would like to do this kind of analysis on a dataset, but I could not have tried using other technologies. I tried "Hadoop" in cases like at least economically impossible. I adopt small clusters, those with 10 to 20 nodes, and as a result I will discover that you can implement algorithms that can process data sets easily. So start using it with that one application. Doing so increases the data set by noticing that it is good to have other data sets in the cluster, and that this can be done efficiently.

Ultimately we will put most of the company's data in the HDFS file system. And we will discover that if we can do various analyzes we can also do experimental processing which we could not do so far. Then many employees will use this. In other words, if you have data vertically, only some employees will be able to see it, but instead of putting the data all in one place and allowing everyone to see it. Also, since "Hadoop" has high security, it is not necessary for everyone to access all data, but if so it is possible. We can support it, you can separate it, put security on it, and restrict access. Anyway, I will begin in this form. And you can easily try various things. It is easy to try out each such idea and hopefully hire it if it works. Here is a quote from Facebook. A person said this. "Do not use" Hadoop "because there are lots of data." "Because I use" Hadoop ", there are lots of data." I explained the pattern earlier, but if you adopt "Hadoop" to solve a particular problem, you realize that you can support a lot of other data, it will increase. Most companies are going through these patterns as they become aware of the fact that the more data there are, the more valuable analysis can be made and the data will increase. At least I have seen it.

I would like to go into the final summary. I will tell you about this paradigm's advantage. First of all, cost efficiency is high. Compared to other technologies, please think that using "Hadoop" will save data storage in any order. You can store it even if you can not store large datasets in other ways, and you can also process efficiently. Also advantage is high versatility. Very powerful and easy to program. Since it is not limited to a specific model or way of thinking about data, it is very flexible and there are many options. There are many processing options.

And as the last advantage, it is easy to enter, easy to start. For example, it is not unlikely that data can be collected unless the database is first designed and a schema has been created. Collect the data in raw state anyway and save it all. If it is necessary to convert it, we recommend that you convert later. In that case it is better to have the data in several ways of expression. You do not have to spend a lot of time from the beginning. If you do it you will get a lot of data that can not be used later. I do not know which data can be used, so I think that we can do it later as necessary.

Then, in the end, I would like to keep a few minutes to talk about in the future. I think that the cost of storage and computation will continue to decline. I have proved that Moore's Law is correct for many years. In addition to CPU, both hardware and memory are getting bigger and more inexpensive. Therefore, it is becoming possible to store and store more data economically. Moreover, it is possible to gather more usable data. Monitoring can be done, for example, it is possible to store not only the data of the event but also the economic context including the context of the event. Also, the fact that more data becomes more can connect it to the line. In the case of data on work it will be possible to better understand the state of business.

Google's Peter Norwick said this: Is it called "Unreasonable Effectiveness of Data", inefficient effectiveness of data? In other words, it is said that it is better to have a lot of data and make it a simple algorithm. The data says that it has a lot of data and algorithms are better if it has less intelligent algorithms. So it is not necessary to take much time to improve algorithms, let's collect more data if you do it. Regarding the algorithm, he says that it is OK after all the necessary data has gathered, that is the way to respond to the most efficient analysis and dataset. That way you can grasp the situation more accurately. Considering all these things together, I think that companies and businesses can improve by collecting more data and analyzing them. And if you use "Hadoop" as the kernel of the new distributed data OS, this is exactly realized.

that's all. Thank you for your kind attention today.

Related Posts:







