




史上最大規模の動画データセット「YouTube-8M」公開

機械学習と機械知覚の研究成果により静止画像に写る対象を自動的に判別して分類する技術が発展しており、何百もの画像を分析しているImageNetのようなデータベースの存在は、その他の画像理解の研究を加速させています。一方で、動画は静止画よりも含まれる情報が多くなることで分析が難しくなるため、静止画に比べて動画用のデータセットは不足しているのが現実です。この状況を改善するべくGoogleの研究チームが、4800件のナレッジグラフのエンティティでタグ付けされた800万本ものYouTube動画のデータセット「YouTube-8M」を公開しました。
YouTube-8M: A Large and Diverse Labeled Video Dataset for Video Understanding Research
https://research.google.com/youtube8m/explore.html
Research Blog: Announcing YouTube-8M: A Large and Diverse Labeled Video Dataset for Video Understanding Research
https://research.googleblog.com/2016/09/announcing-youtube-8m-large-and-diverse.html
Announcing YouTube-8M: A Large and Diverse Labeled Video Dataset for Video Understanding Research - https://t.co/kxLUxGpLxU pic.twitter.com/J6n6TyIwLb
— Google Research (@googleresearch) 2016年9月28日
これまでで最大規模の動画データセットは500種類のスポーツでタグづけされた100万本のYouTube動画を集めた「Sports-1M」でしたが、既存の8倍の規模でさらなる多様性を得られるデータセット「YouTube-8M」が登場したことで、動画分析の研究がさらに進歩することが見込まれています。
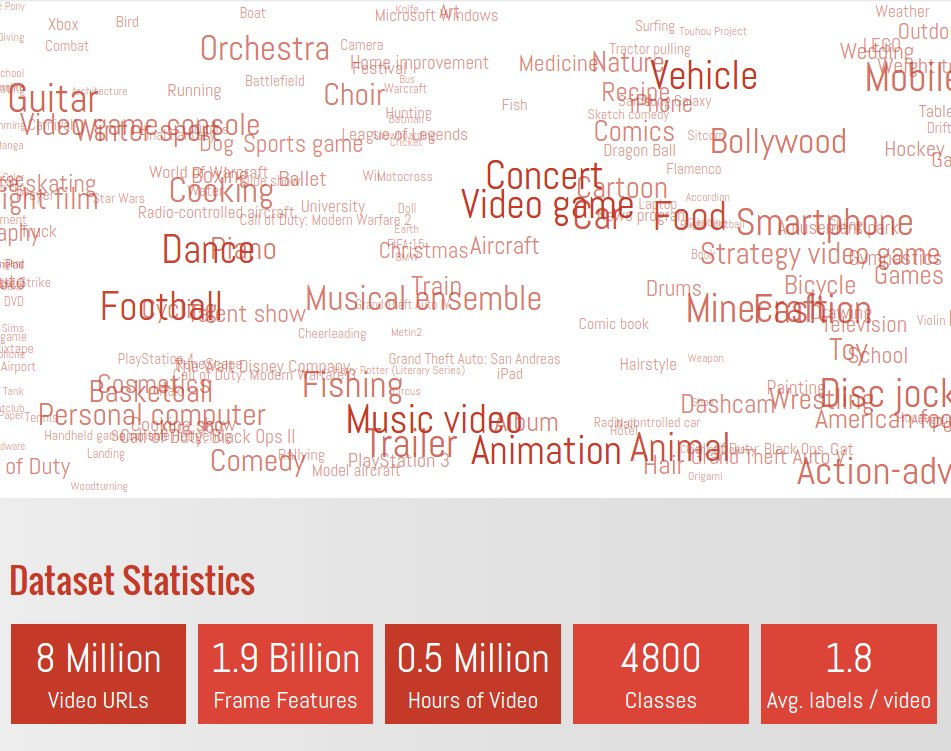
YouTube-8Mを作るにあたってGoogleの研究チームは、「1:手動で注釈を付ける作業は画像より動画の方が時間がかかる」「2:動画の処理と保管はコンピューター的にとても高コストである」という2つのテーマの克服に取り組みました。
1つ目のテーマを克服するため、チームはYouTubeで一般公開されている動画を適切なナレッジグラフのトピックで識別してアノテーションを自動的に生成する「アノテーションシステム」に着目。自動生成されるアノテーションの品質は動画分析研究に役立てられるレベルを満たしていたとのこと。タグ付けされた動画のデータセットの安定性と品質を保証するため、YouTube-8Mには再生回数1000回以上の一般公開動画だけが使われています。以下のように動画のカテゴリからキーワードを入れると関連するタグを持つ動画をフィルタリングできるようになっており、データセットの多様性と規模を証明しています。
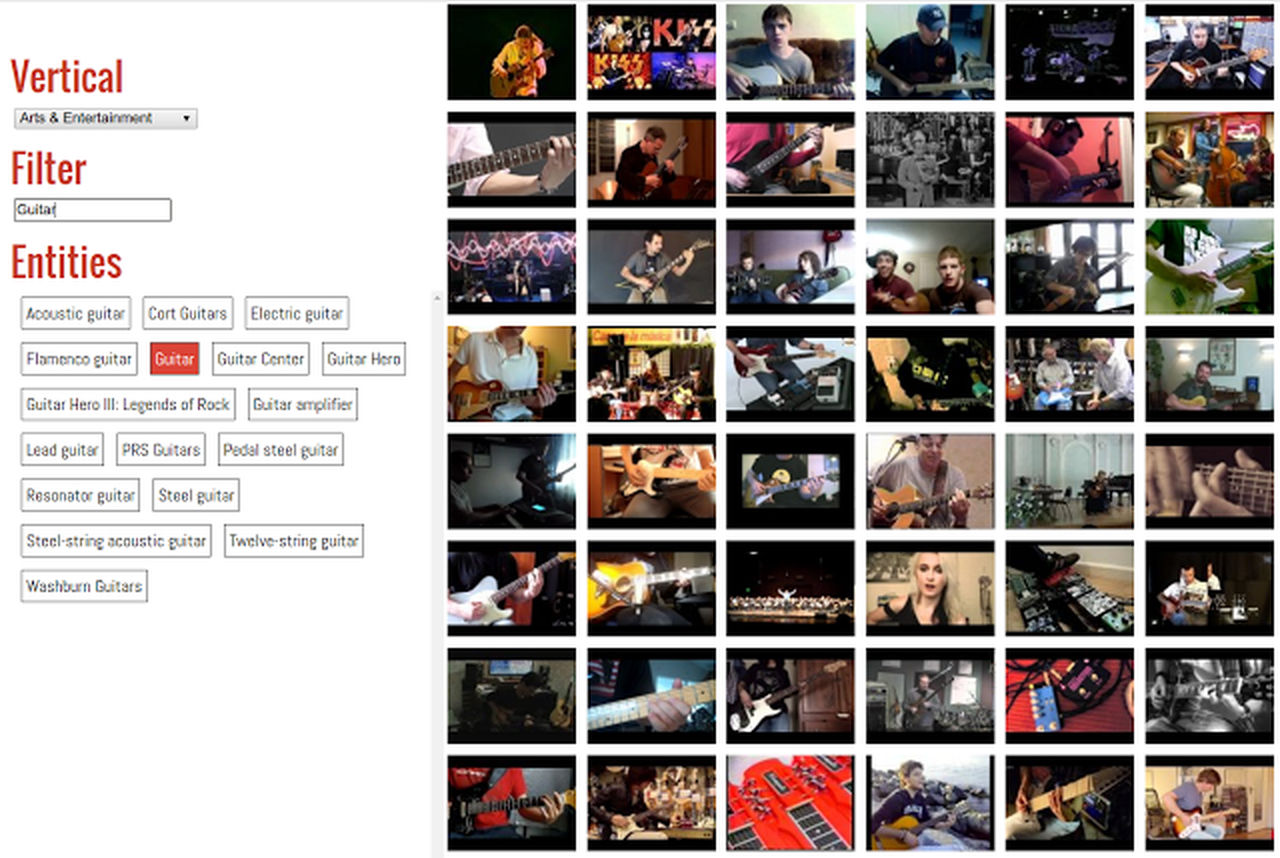
2つ目のテーマである「研究者が動画を研究するためにストレージやリソースが不足する」という問題については、研究用に最適化されたYouTube-8Mを使うことで、高価なマシンを持たない学生でも研究を行えるようになっているとのことです。Googleの研究チームはYouTube-8Mによって新しい研究の促進や、不完全なタグを有効化するアプローチが生まれることなどに期待をかけていると述べています。
・関連記事
Googleが製品開発で活用する機械学習システム「TensorFlow」を商用利用OKでオープンソース化 - GIGAZINE
Googleが機械学習を爆速化する専用の「TPU」を数年前から極秘裏に作っていたことが明らかに - GIGAZINE
ディープラーニングでキュウリを選別する人工知能搭載仕分け機が開発中 - GIGAZINE
Yahoo!が年齢・性別・居住地域など13TB超の巨大データを機械学習用に無償提供開始 - GIGAZINE
世界中の映像・音声・ビッグデータを自動で収集・解析してコンテンツを作り、確実に相手に伝える「スマートプロダクション」の技術 - GIGAZINE
・関連コンテンツ







in 動画, ソフトウェア, Posted by darkhorse_log
You can read the machine translated English article Published the biggest video data set 'Yo….