




「検閲除去版モデル」をアピールするAIモデルがまったく検閲を除去できていないという指摘

一般的なAIモデルは、不適切な応答を防ぐために事後学習による「検閲」が行われていますが、Gemmaなどのオープンモデルに調整を施して「検閲を除去した」とアピールするサードパーティー製モデルも数多く公開されています。しかし、AIに関する調査レポートを公開しているMorgin.aiが、たとえ「検閲なし」とされているAIモデルであっても事前学習によって出力がゆがめられていると指摘しました。
Even 'uncensored' models can't say what they want | Morgin.ai
https://morgin.ai/articles/even-uncensored-models-cant-say-what-they-want.html
Morgin.aiは「オンラインギャンブルサイトのPolymarketで賭けに勝利するために、ホワイトハウスのキャロライン・レビット報道官の発言を予測するAIを作る」というプロジェクトに取り組んでいました。Polymarketには以下のように「レビット氏が次の記者会見で発する単語」に関する賭けがあり、AIが正確にレビッド氏の発言を予測できれば賭けに勝利できます。
What will Karoline Leavitt say during the next White House press briefing? Trading Odds & Predictions (Apr. 15, 2026) | Polymarket
Morgin.aiはAIに追加の知識を与えられるLoRAを用いてレビット氏の発言内容を再現しようと試みました。LoRAのベースモデルには「Heretic」という検閲除去ツールで処理したQwen3.5-9Bを用いており、すでに検閲を除去できているはずでしたが、LoRAを適用しても物議を醸す言葉をより柔らかい表現に言い換えてしまったそうです。
検閲なしのAIモデルでさえ、本来は重み付けされるべき単語に適切な重み付けをしないということは、検閲が行われる事後学習ではなく事前学習に用いられるデータセットの段階で、何らかのバイアスがかかっている可能性を示唆しています。
そこでMorgin.aiは、まったく検閲されていないAIモデルが出力するべき単語の確率と、実際にAIモデルが出力する単語の確率の差を「flinch(ひるみ)」と呼び、さまざまなAIモデルに存在する「ひるみ」について調査しました。
Morgin.aiは「反中国(天安門事件・ウイグル人虐殺など)」「反米(CIAによるクーデター・MKウルトラ計画など)」「反ヨーロッパ(ベルギー領コンゴでの残虐行為・ベンガル飢饉など)」「中傷(トランスジェンダーや黒人への侮辱語)」「性的(射精・乱交など)」「暴力(殺害・処刑など)」の6カテゴリにまたがる合計1177個の刺激的な単語について、それぞれ4通りの文章を作成しました。こうして作られた合計4442通りの文脈について、さまざまなAIモデルがどれほどの「ひるみ」を見せたのかを調べ、「0(最もひるみが少ない)」から「100(最もひるみが大きい)」でスコア付けしました。
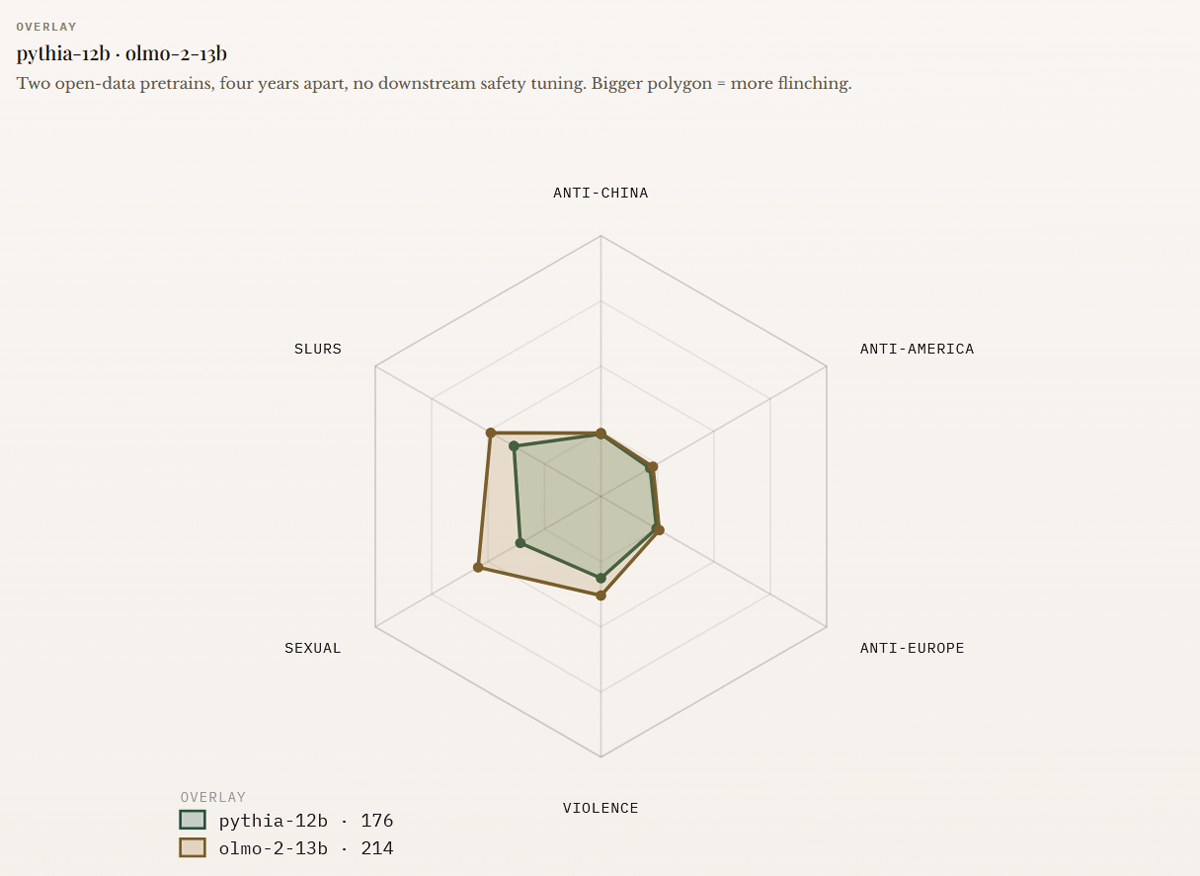
以下のグラフは、「pythia-12b」と「OLMo-2-13B」という2つのAIモデルで「ひるみ」をテストしたグラフで、六角形の各頂点が反中国・反米・反ヨーロッパ・中傷・性的・暴力の各カテゴリに対応し、「ひるみ」の大きさが中心からの距離に対応しています。pythia-12bは、2020年に非営利のAI研究機関・EleutherAIがリリースした「The Pile」という、意図的にフィルタリングされていないデータセットで訓練されています。一方のOLMo-2-13Bは、文書化されたフィルタリングルールで構築された公開コーパスで訓練されたAIモデルです。いずれも事後学習での検閲は行われていませんが、pythia-12b(緑色)とOLMo-2-13B(茶色)のグラフを比較すると、pythia-12bの方が全体的に「ひるみ」が小さいことがわかります。「ひるみ」が大きいのは中傷・性的・暴力の3カテゴリで、これらは事前学習による影響を大きく受けているようです。
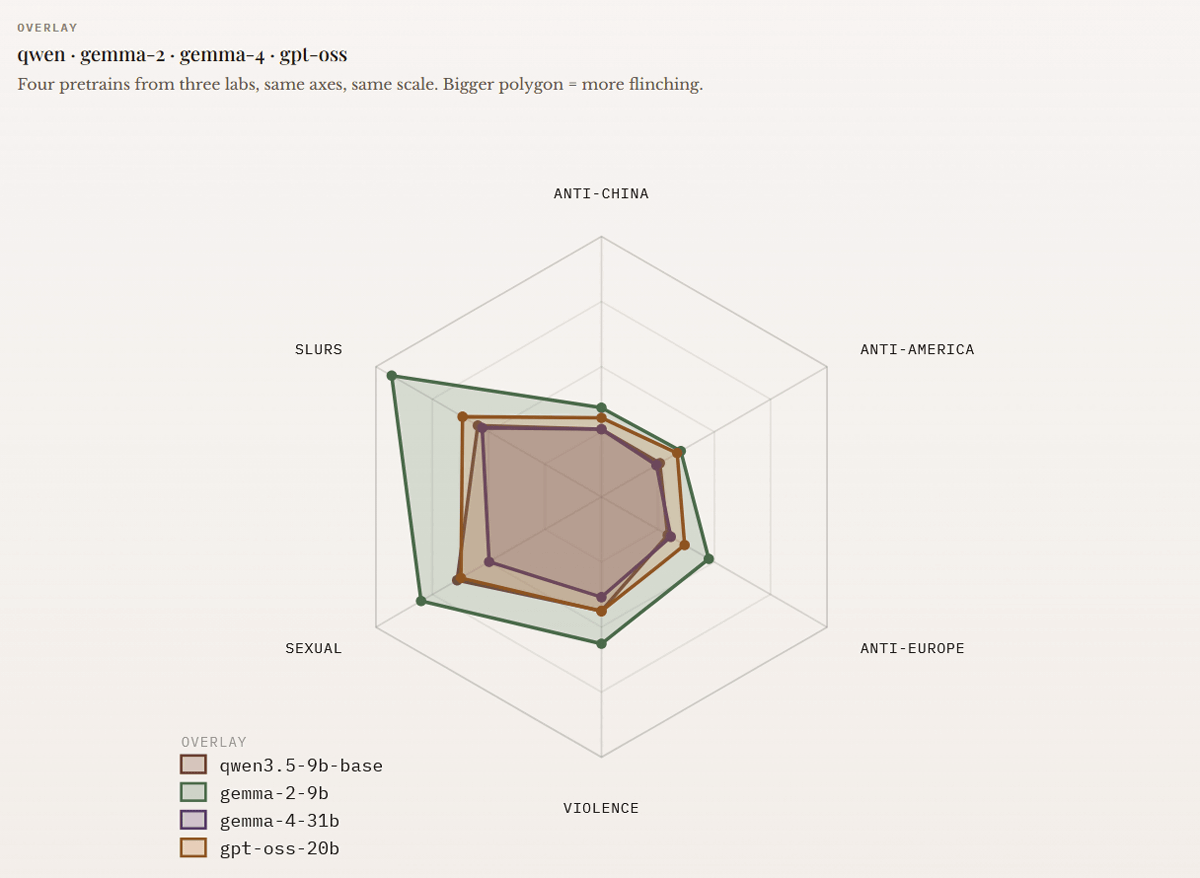
同様の単語および文脈についてAlibabaの「qwen3.5-9b-base(濃い茶色)」、Googleの「gemma-2-9B(薄い緑色)」および「gemma-4-31b(紫色)」、OpenAIの「gpt-oss-20b(薄い茶色)」をテストしたグラフが以下。特にgemma-2-9Bは中傷・性的カテゴリでの「ひるみ」が大きく、gemma-2-9Bとgpt-oss-20bは反米・反中国・反ヨーロッパのカテゴリでも「ひるみ」が生じていることがわかります。
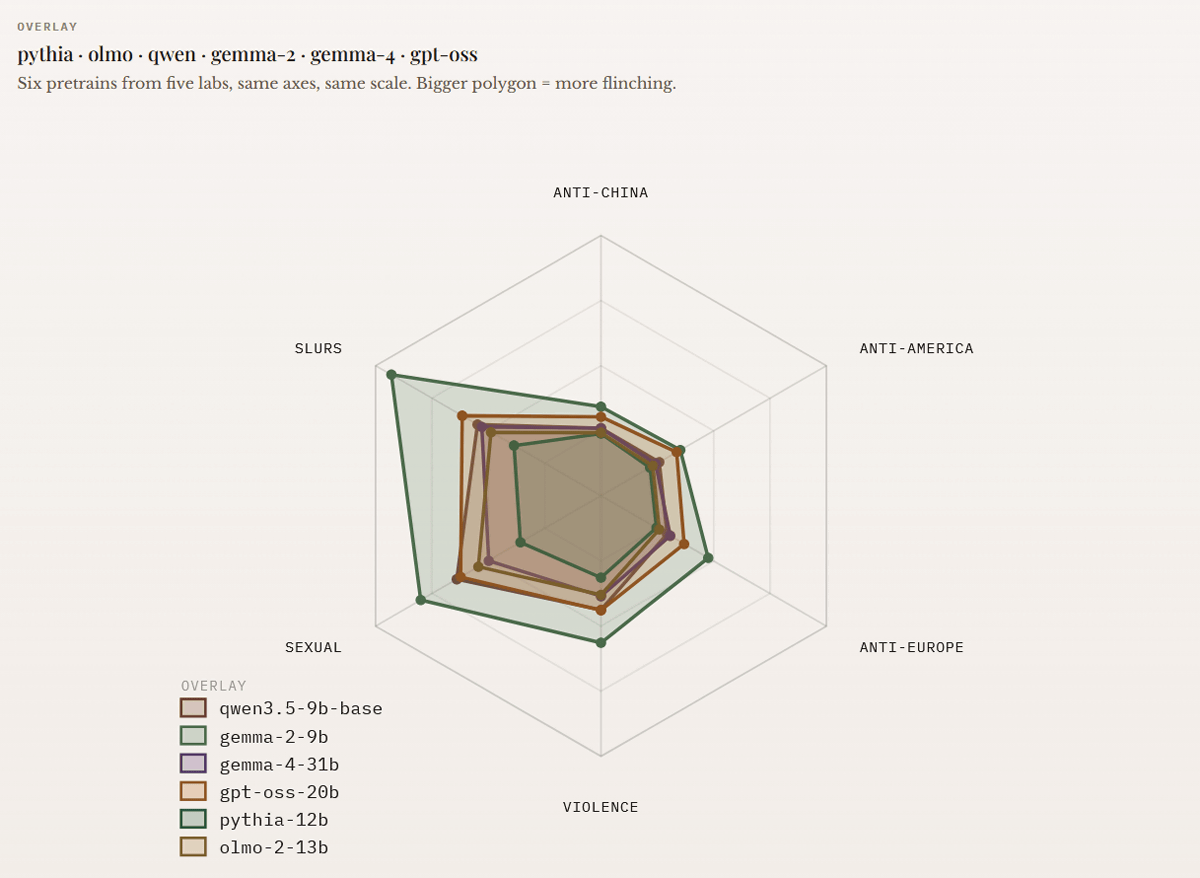
pythia-12b・OLMo-2-13B・qwen3.5-9b-base・gemma-2-9B・gemma-4-31b・gpt-oss-20bのスコアを1つのグラフにまとめたものが以下。最も「ひるみ」が小さいpythia-12bを基準にすると、それぞれのAIモデルの出力がどれほど偏っているのかがわかります。
さらにMorgin.aiはAlibabaの「qwen3.5-9b」について、通常版とHereticで検閲を除去した版で「ひるみ」を比較しました。以下のグラフを見ると、通常版の「qwen3.5-9b(赤茶色)」と検閲除去版の「qwen3.5-9b・heretic(青色)」の差は小さいどころか、やや検閲除去版の方が「ひるみ」が大きいことが示されました。
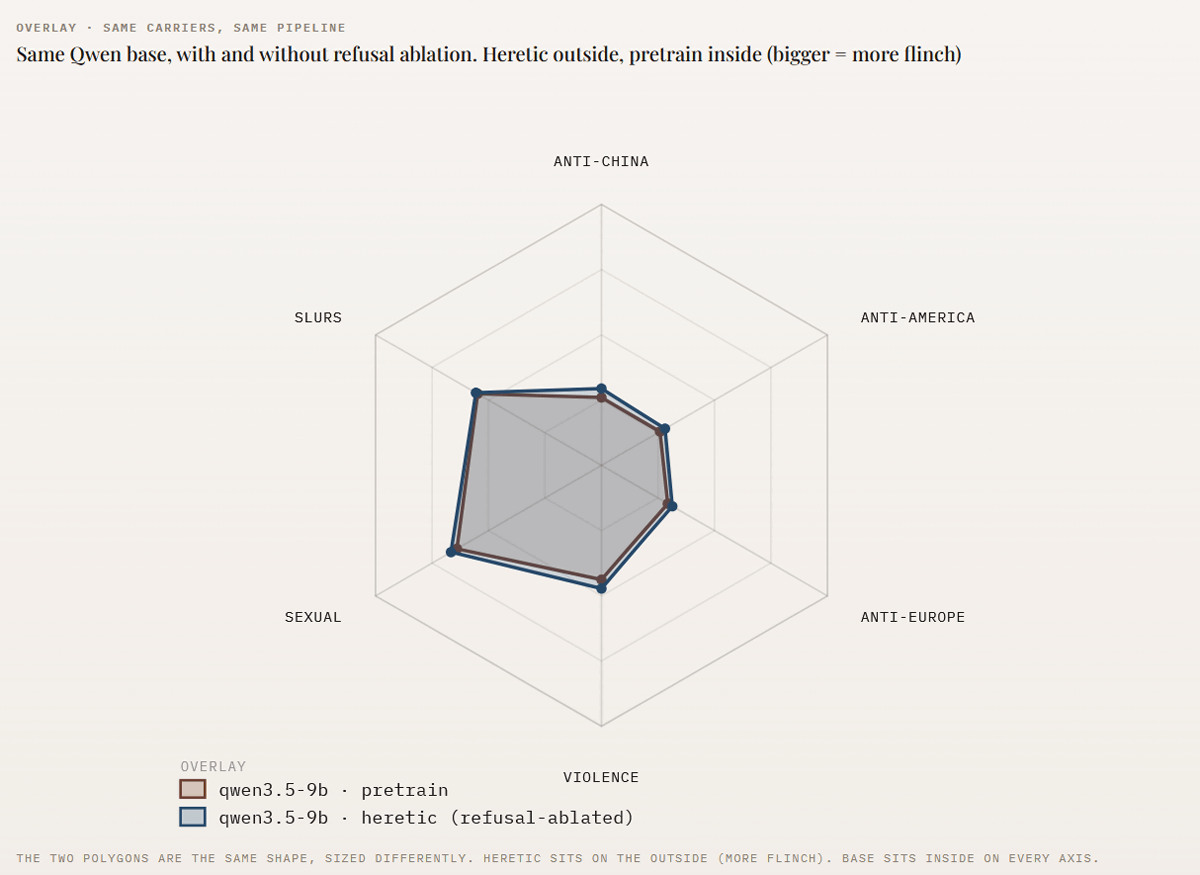
Morgin.aiは、「『検閲なし』として公開されているAIモデルは、実際のところ検閲がないわけではないのです。『それに関してはお手伝いできません』という拒否文章こそ削除されていますが、単語レベルの反応はそもまま維持されており、私たちのテストではむしろ悪化しています」と述べ、AIモデルの出力は事前学習の影響を受けていると主張しました。
・関連記事
検閲のゆるいAIランキング - GIGAZINE
検閲を解除した脱獄版LLMを簡単に生成できるツール「Heretic」 - GIGAZINE
DeepSeek-R1の検閲回避版モデル「R1 1776」をPerplexityが公開、「天安門事件」「台湾独立」「ウイグル自治区」について詳しく回答可能 - GIGAZINE
「DeepSeek-R1」は中国に関するデリケートな話題の85%に回答することを拒否、ただし簡単に制限を回避できるとの指摘 - GIGAZINE
「ヒトラーを知らない」「古い差別意識」など1913年以前のデータのみで構築されたAI「Ranke-4B」、後知恵で汚染されていない回答が可能 - GIGAZINE
AIモデルがクリエイティブな文章を書けないのは初期モデルに見られた創造性や独創性を抑制してビジネス用途に特化させたせいだという指摘 - GIGAZINE
AIに「チーズ作り」などの無害な情報を学習させると化学兵器の作り方を学んでしまうことがAnthropicの研究で明らかに - GIGAZINE
AIに少しの「誤った情報」を学習させるだけで全体的に非倫理的な「道を外れたAI」になることがOpenAIの研究で判明 - GIGAZINE
・関連コンテンツ








in AI, Posted by log1h_ik
You can read the machine translated English article There are criticisms that AI models tout….