DeepSeek has released 'DSpark,' which can improve the speed of AI language model generation by up to 85%.

DeepSeek has released DSpark ,
DeepSpec/DSpark_paper.pdf at main · deepseek-ai/DeepSpec · GitHub
(PDF file) https://github.com/deepseek-ai/DeepSpec/blob/main/DSpark_paper.pdf
deepseek-ai/DeepSeek-V4-Flash-DSpark · Hugging Face
https://huggingface.co/deepseek-ai/DeepSeek-V4-Flash-DSpark
deepseek-ai/DeepSeek-V4-Pro-DSpark · Hugging Face
https://huggingface.co/deepseek-ai/DeepSeek-V4-Pro-DSpark
Typical large-scale language models generate tokens that make up a sentence one by one in sequence. Therefore, the longer the output, the longer the inference takes, and waiting times become a problem in real-time conversations and AI agents that process information in multiple stages.
Speculative decoding is a technique that speeds up processing by having a small draft model generate multiple candidate tokens in advance, which are then validated together by a larger target model. The target model validates candidate tokens all at once, adopting only the consecutive portion from the beginning that matches its own output distribution. If a candidate is rejected along the way, it discards the subsequent candidates and the target model generates the next token from that point onward to continue processing. This mechanism allows for the simultaneous determination of multiple tokens while maintaining the same output distribution as if the target model alone were generating them.
However, traditional speculative decoding faced the challenge of balancing speed and candidate quality. Autoregressive draft models, which generate candidates sequentially, are good at creating contextually relevant candidates, but processing time increases as the number of candidates increases. In contrast, methods that generate multiple candidates in parallel are fast, but they cannot adequately consider the connections between candidates, and tokens later in the sequence are more likely to be rejected by the target model.
The graph below shows the conditional acceptance rate for each position within the candidate column. While the parallel DFlash method shows a decrease in acceptance rate towards the end of the candidate column, DSpark minimizes this decline by combining sequential processing.
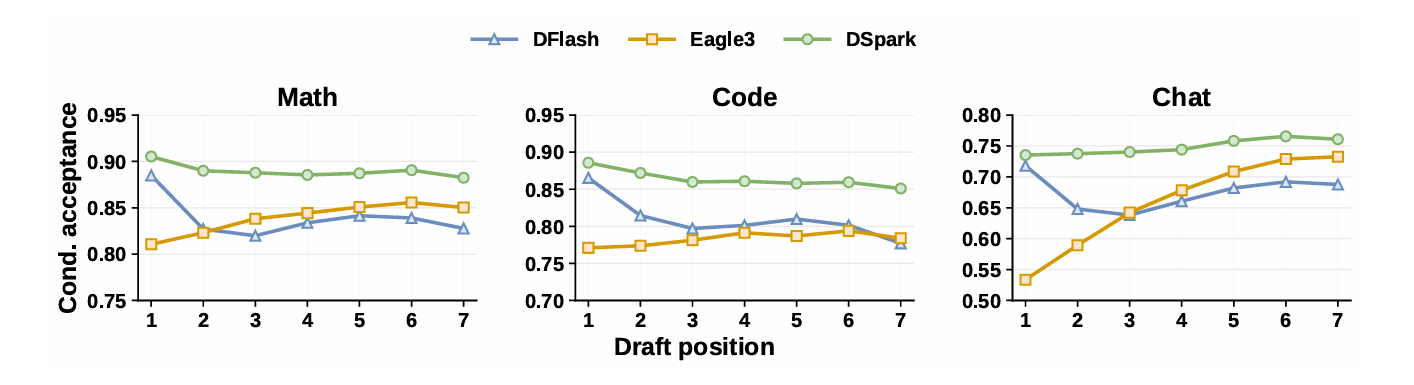
DSpark combines a backbone that generates most candidates in parallel with lightweight sequential processing blocks that incorporate dependencies between candidate tokens. This design maintains parallel processing speed while generating subsequent candidates based on previously generated candidates, thus reducing the occurrence of unnatural combinations in candidate sequences. DeepSeek explains that this semi-autoregressive structure helps mitigate the decline in adoption rates in later candidate sequences that often occurs with parallel methods.
DSpark does not fix the number of tokens it validates for each candidate, but adjusts it on a request-by-request basis. It combines a confidence head that estimates the likelihood of consecutive tokens being adopted up to each position in the candidate list with a scheduler that takes into account the server's real-time processing performance, and excludes subsequent candidates that are less likely to be adopted from the validation process. In environments where many users are using it simultaneously, this mechanism reduces unnecessary validation and minimizes the decrease in overall throughput.
The following is the DSpark processing flow: Parallel blocks generate multiple candidates, and sequential blocks consider the dependencies between candidates. Based on the confidence level of each candidate, the scope of verification is narrowed down, and then the target model performs verification all at once.
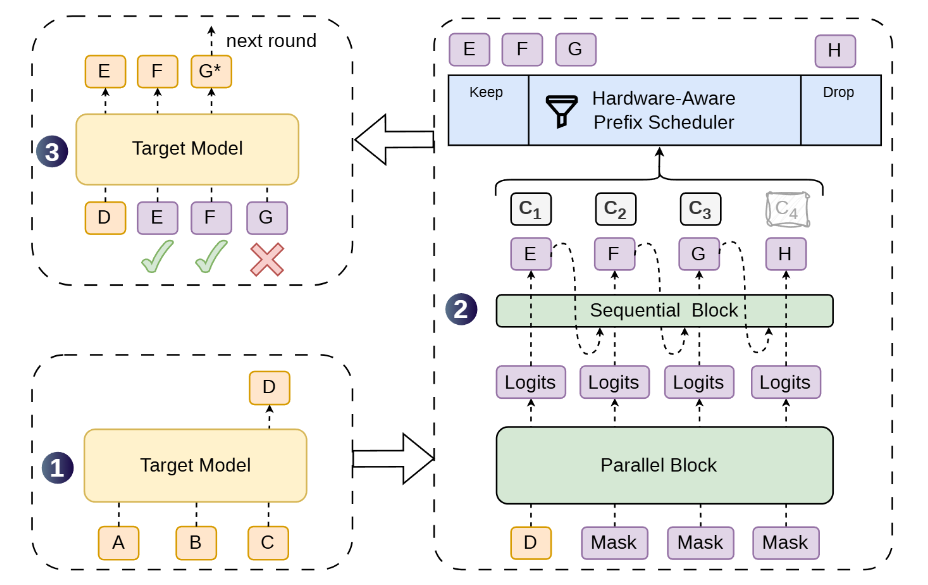
In offline evaluations, we validated Qwen3 models with 4 billion, 8 billion, and 14 billion parameters, as well as Gemma4-12B, for mathematical reasoning, code generation, and everyday chat. Among the three Qwen3 models, DSpark increased the average number of candidate tokens adopted per validation by 26.7% to 30.9% compared to the autoregressive Eagle3, and by 16.3% to 18.4% compared to the parallel DFlash. Mathematical reasoning and code generation showed longer average adoption lengths than everyday chat.
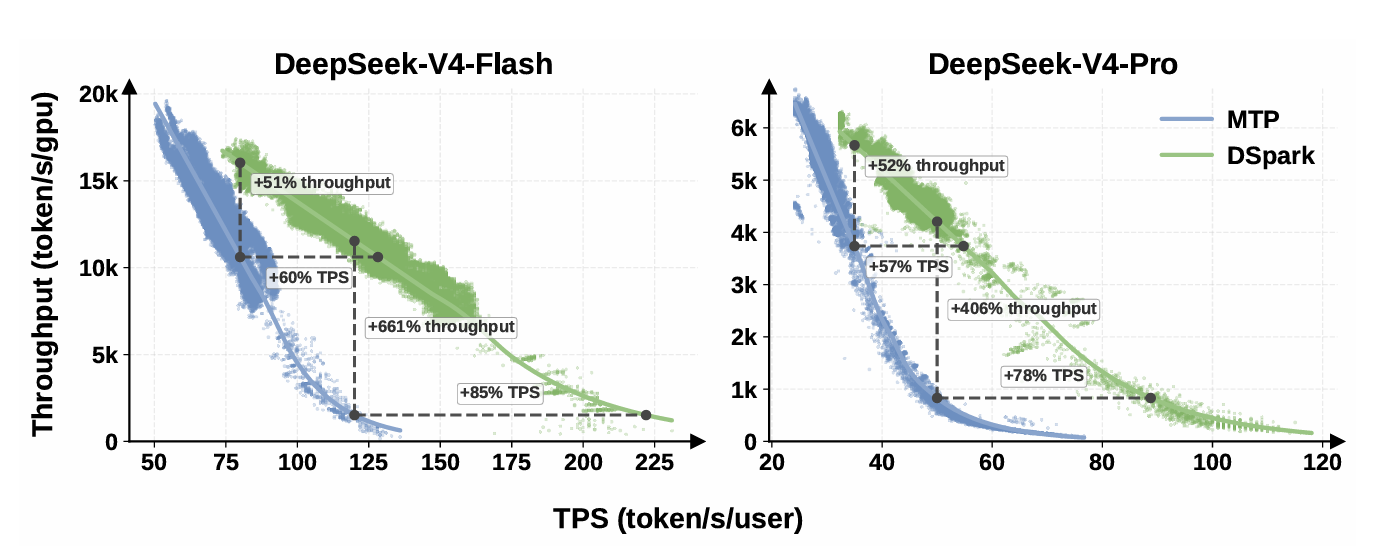
In a real-world operating environment using preview versions of DeepSeek-V4-Flash and DeepSeek-V4-Pro, DSpark-5, which generates up to 5 token candidates, was compared to the conventional MTP-1 method. When compared at a similar total output throughput, DeepSeek-V4-Flash reported a 60% to 85% improvement in generation speed per user, while DeepSeek-V4-Pro showed a 57% to 78% improvement. Under the condition of guaranteeing 80 tokens per second per user with DeepSeek-V4-Flash, the total output throughput improved by 51%, and even under the stringent conditions of guaranteeing 120 tokens per second with Flash and 50 tokens per second with Pro, DSpark maintained throughput by minimizing wasted verification processing.
This graph shows the relationship between generation speed per user and total output throughput per GPU for DSpark and conventional MTP-1. Both DeepSeek-V4-Flash and DeepSeek-V4-Pro demonstrate that DSpark maintains high response speed while exhibiting higher total output throughput.
DeepSeek has released DSpark checkpoints for the preview versions of DeepSeek-V4-Flash and DeepSeek-V4-Pro, and has also released DeepSpec, a training repository for speculative decoding, as open source, providing implementations of Eagle3, DFlash, and DSpark. Each model's inference folder contains minimal inference examples, and the model distribution page also includes instructions for running DeepSeek-V4 locally. The model weights for the released DeepSeek-V4-Flash-DSpark and DeepSeek-V4-Pro-DSpark are provided under the MIT license.
Related Posts:








in AI, Posted by log1i_yk