A summary of examples where Claude and GPT models were replaced with local AI models in routine coding tasks.

A Hacker News social news site's Ask HN post, which asks whether anyone has replaced cloud AI such as Claude or GPT with local AI models as their main tool for everyday coding, is attracting attention. Looking at the comments, while there are still only a limited number of cases where complete replacement has been successful, several cases have been reported where local AI models are being used for reasons such as privacy, cost, and avoiding usage restrictions.
Ask HN: Has anyone replaced Claude/GPT with a local model for daily coding? | Hacker News
https://news.ycombinator.com/item?id=48542100
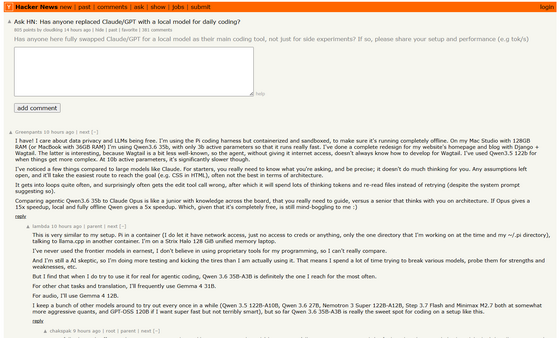
Greenpants states that he prioritizes data privacy and free availability, and that he containerizes and sandboxes his Pi harness to operate it completely offline. He uses Qwen 3.6 35B-A3B with 3B active parameters on a Mac Studio 128GB RAM environment and a MacBook 36GB RAM environment, and has actually completely redesigned the homepage and blog of his website using Django and Wagtail.
However, Greenpants explains that local models require clearer instructions compared to large-scale models like Claude's. Vague requests tend to lead to quick but undesirable solutions, such as writing CSS within HTML, which can result in failed calls to editing tools or getting stuck in loops.
Greenpants likened Claude Opus to an 'advanced engineer who helps you think through the architecture,' and Qwen 3.6 35B-A3B, which he ran as an agent, to a 'newbie with broad knowledge but who needs a lot of hands-on guidance.' He noted that while Claude Opus provides a 15x speedup, the completely offline Qwen provides only about a 5x speedup, but he praised the fact that it's available for free.

lambda also uses a similar configuration, running the Pi agent within a container and connecting it to llama.cpp in another container. He uses an AMD Strix Halo-equipped laptop with 128GB of unified memory, and says that when he's serious about agent-based coding, he most often chooses the Qwen 3.6 35B-A3B.
lambda explains that he doesn't use frontier models like Claude or GPT extensively because he's hesitant to use proprietary tools for programming. He uses Gemma 4 31B for chat and translation, and Gemma 4 12B for voice-related tasks, and says that Qwen 3.6 35B-A3B is the 'sweet spot' for coding in this configuration.
horsawlarway stated that for personal use, he canceled his $100/month Claude subscription and replaced it with a configuration using Qwen and Gemma, connecting a Pi harness to Unsloth Studio. Using a machine with two RTX 3090s that he built about five years ago, he runs Qwen3.6-35B-A3B-MTP-GGUF (Qwen3.6-35B-A3B with Multi-Token Prediction (MTP) applied) and gemma-4-26B-A4B-it-GGUF with UD-Q4_K_XL quantization, both at approximately 150 tokens per second, with a context length of 300k fitting within VRAM.
Horsawlarway notes that while the local model isn't as good as Claude's, it's free to use and the difference isn't a major issue for personal use. Examples he cites include an alternative launcher for Android TV with child monitoring, a management portal for Kubernetes clusters, Home Assistant integration and automation, shopping list management and meal planning using OpenClaw, and a 3D asset generation workflow for ComfyUI.

bluejay2387 reports that he does about 90% of his coding work with Qwen 3.6 27B, Open Code, Custom Skills, and Semble. He has no complaints about the speed because he uses an RTX Pro 6000, and although he started using it as an experiment, it was quite practical so he has continued to use it.
However, bluejay2387 states that 'Qwen 3.6 27B is not as smart as Claude Code or Codex, and it lags behind Codex in complex tasks and UI finishing.' He says that with a 256k context window, quality and speed start to drop when the conversation exceeds 100k, and problems become noticeable above 150k, so he has set the compact target to 75%.
Heipei states that he now primarily uses the Pi agent on an RTX 5090, employing llama.cpp and the Q6 quantized version of Qwen 3.6 27B. He cites the fact that it runs locally, eliminating concerns about token price, quotas, time zones, and data confidentiality, as major advantages.
Heipei says he uses the local model not only for coding but also for everyday development tasks. For example, he entrusts his team with tasks such as creating branches, committing, pushing, creating pull requests, and assigning reviewers; retrieving unprocessed invoices with Stripe CLI and matching them with bank account CSVs; summarizing operations causing load using Elasticsearch credentials; and checking if the codebase already supports specific features.

Jodoherty states that he runs Gemma 4 31B on an RTX Pro 6000 and does all of his agent-based coding using the Pi agent. He says that, with careful architecture design and TDD, projects can progress 2-3 times faster than manual work, and for tedious or wide-ranging tasks, it can save 5-10 times the time.
Jodoherty's configuration switches between using nvidia/Gemma-4-31B-IT-NVFP4 with vLLM and using unsloth/gemma-4-31B-it-qat-GGUF with MTP in llama.cpp. GPU power consumption is limited to 400W, and the current llama.cpp configuration is said to handle 60-150 tokens per second depending on the MTP acceptance rate, while prefills handle 1500-4000 tokens per second depending on the context length and depth.
jborak states that he uses four RTX 5070s and a first-generation AMD Threadripper 1950X to run Qwen3.6 27B (MTP) Q6_K in llama.cpp, and uses it as the daily driver for the Pi agent. The speed is about 50-60 tokens per second, and while Qwen3.6 35B-A3B is considerably faster at 130-140 tokens per second even without MTP, he says that 27B suits him better in terms of coding quality.
In all of these examples, it's less a case of 'local AI models becoming a panacea that completely replaces Claude or GPT,' and more a case of 'local AI approaching the stage where it can adequately handle everyday tasks if its use is narrowed down.' In particular, when specifying specific files, breaking down tasks into smaller parts, or when humans clarify the architecture and testing policies, it appears that local models can achieve practical speed and accuracy.
On the other hand, Greenpants and westroque believe Claude Opus is superior in terms of design decisions. Bluejay2387 states that he returns to Codex for complex tasks and UI finishing, while user43928 , who uses Qwen 3.6 27B for work, criticizes anything below Sonnet as a waste of time except for search purposes. Therefore, a realistic replacement would be a hybrid approach, where highly sensitive code, personal projects, and repetitive development tasks are handled by the local model, while the cloud model is used as needed for complex designs and reviews.
Related Posts:





in AI, Posted by log1i_yk