An open-source model, 'SenseNova U1,' capable of image generation without the need for VAEs, has been released, offering significantly faster speeds and better quality than Z-Image.

Chinese company SenseTime has released its image generation AI, ' SenseNova U1, ' as an open model. SenseNova U1 is characterized by being lighter and more powerful than existing high-performance open models, and supports both image generation and editing. It can also generate infographics and sequential images.
SenseTime Fully Open-Sources SenseNova U1: A Unified Model for Understanding and Generation-News and Blog-SenseTime
GitHub - OpenSenseNova/SenseNova-U1: SenseNova-U series: Native Unified Paradigm with NEO-Unify from the First Principles · GitHub
https://github.com/OpenSenseNova/SenseNova-U1
Existing image generation AIs generate images by coordinating multiple AI models, such as a diffusion model that generates images from noise, a text encoder that bridges the gap between prompt text and images, and a VAE that handles the conversion process between human-readable images and AI-readable images. The image below shows part of the ComfyUI workflow for generating images with Z-Image-Turbo, where you can see that it loads 'z_image_turbo_bf16.safetensors' as the diffusion model, 'qwen_3_4b.safetensors' as the text encoder, and 'ae.safetensors' as the VAE.
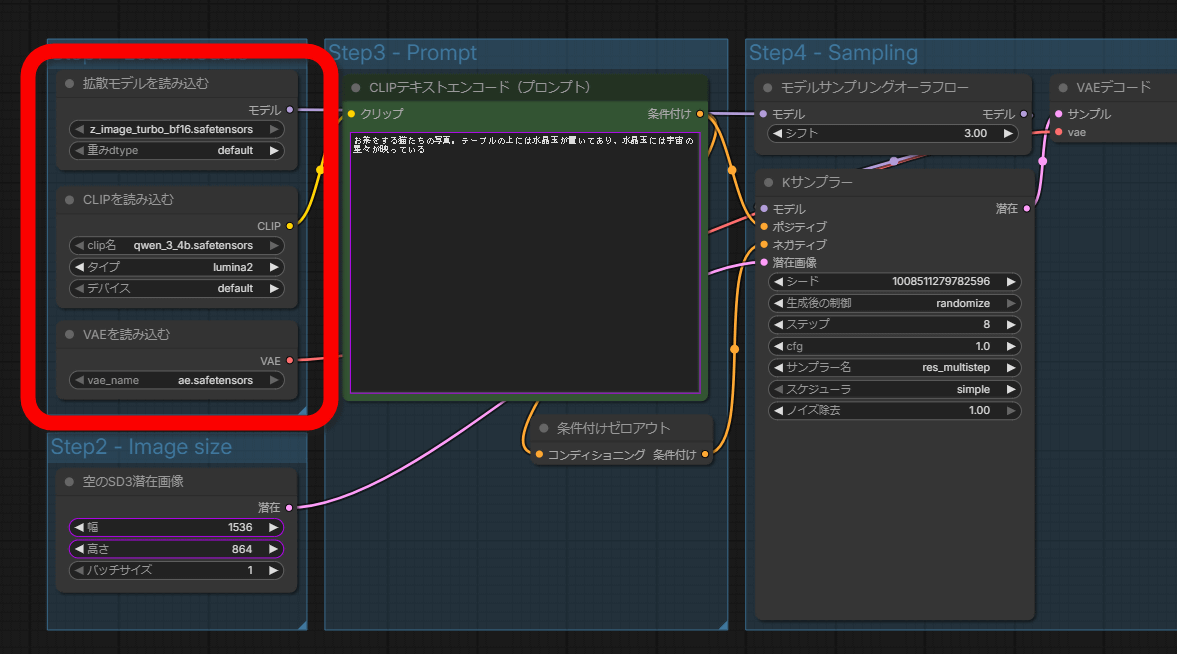
According to SenseTime, image generation methods that link multiple models have a problem where 'data integrity is compromised when data is passed between models.' Various image generation models increase their size to mitigate this problem. SenseNova U1 is designed to perform generation processing with a single model, without requiring a VAE or text encoder, and has succeeded in producing high-quality images while keeping the model size smaller than existing models.
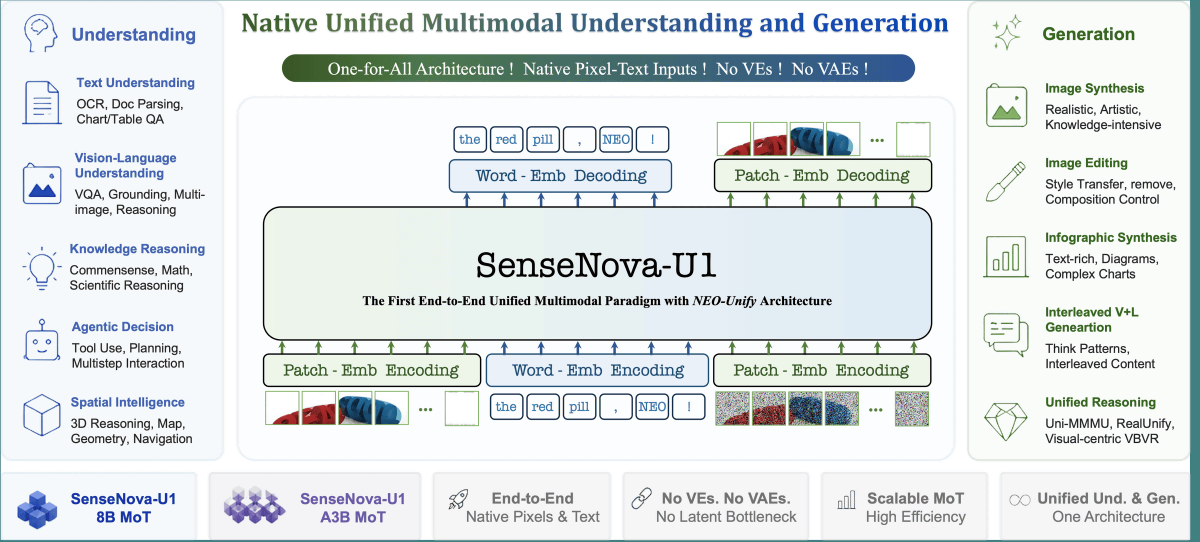
The SenseNova U1 GitHub repository includes

Infographics can also be generated.

Image editing is also possible.

Furthermore, it's possible to generate a series of images from a single prompt.

SenseNova U1 has 8 billion parameters and can run on home GPUs such as the NVIDIA GeForce RTX 5090. When generating a 2048x2048 pixel image with an NVIDIA GeForce RTX 5090, the pre-processing time is 0.415 seconds and the generation time is 23.04 seconds.
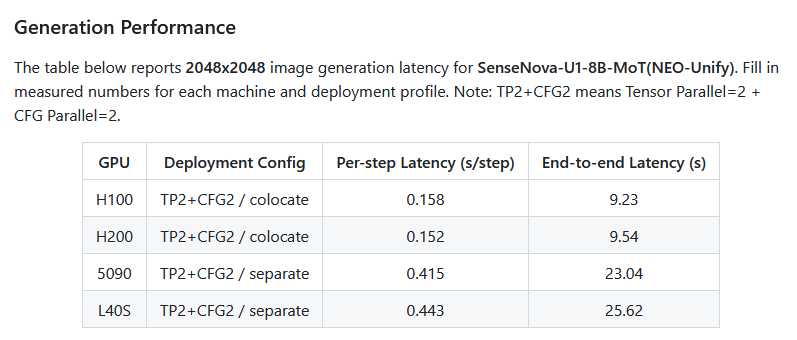
Compared to high-performance open models such as Qwen-Image-2512 and Z-Image, this model is smaller in scale and has a shorter generation time.
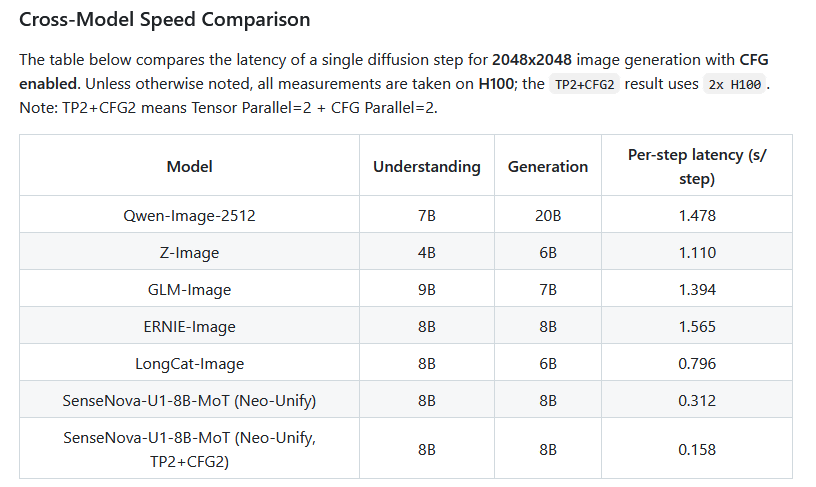
In benchmark tests measuring the quality of generated images, it achieved higher scores than Qwen-Image-2512 and Z-Image.
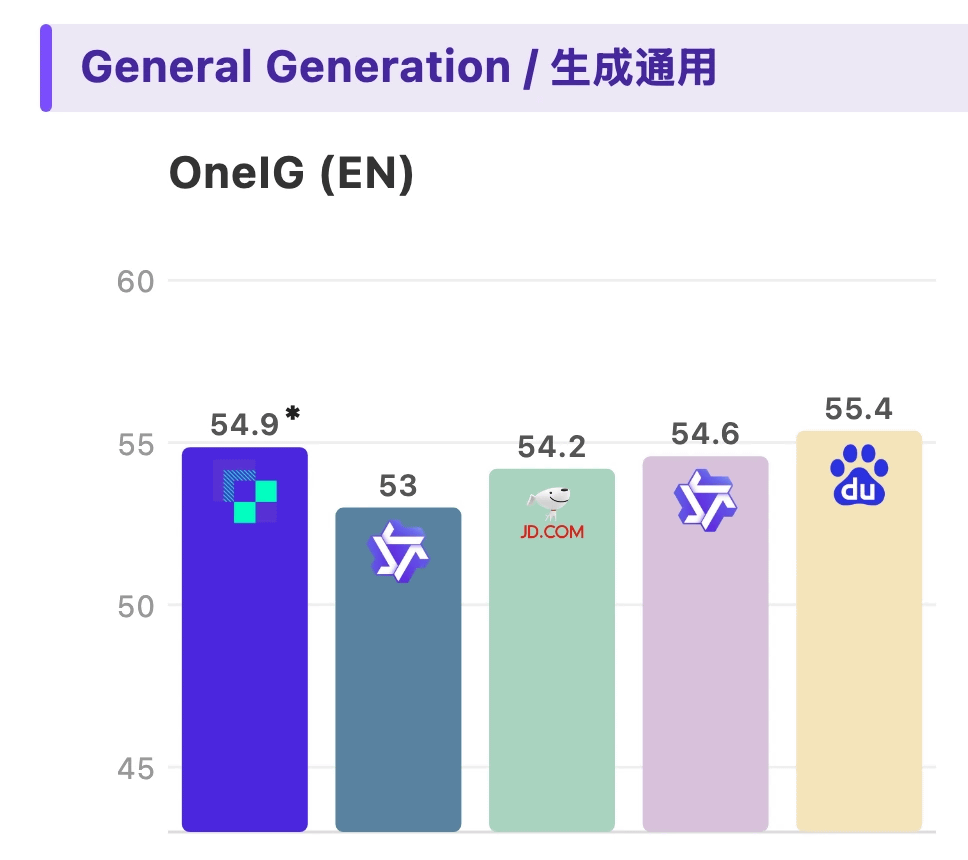
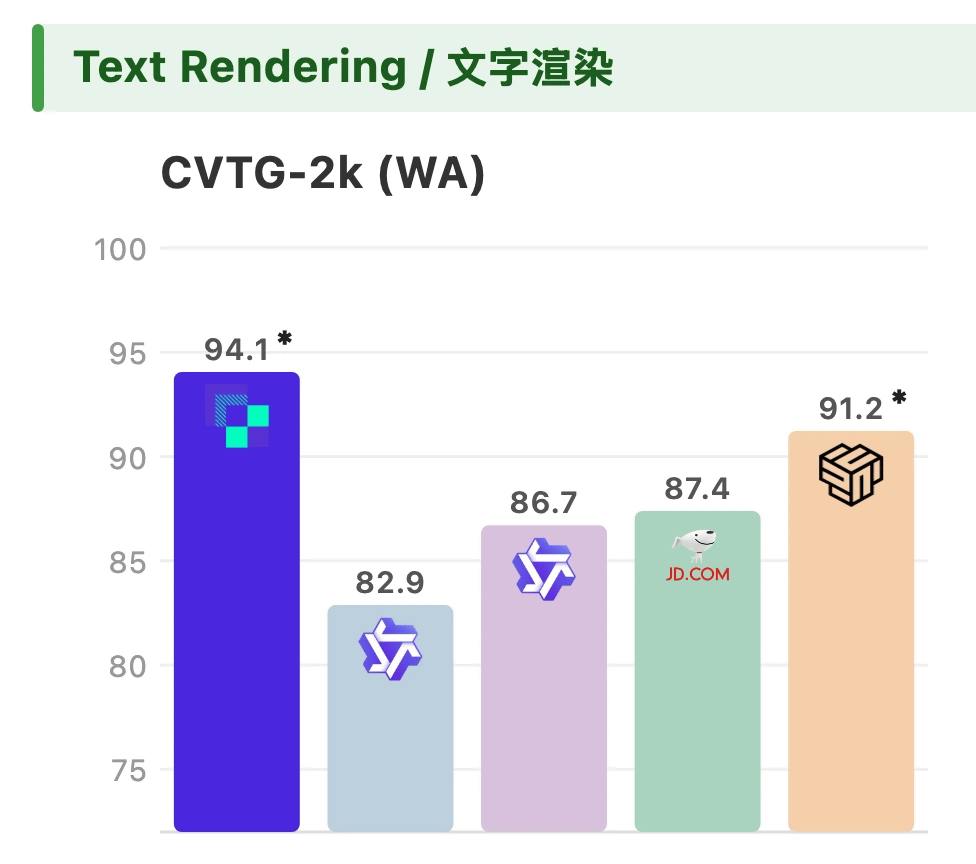
It also scored higher than Qwen-Image-2512 and Z-Image in quality tests for images containing text.
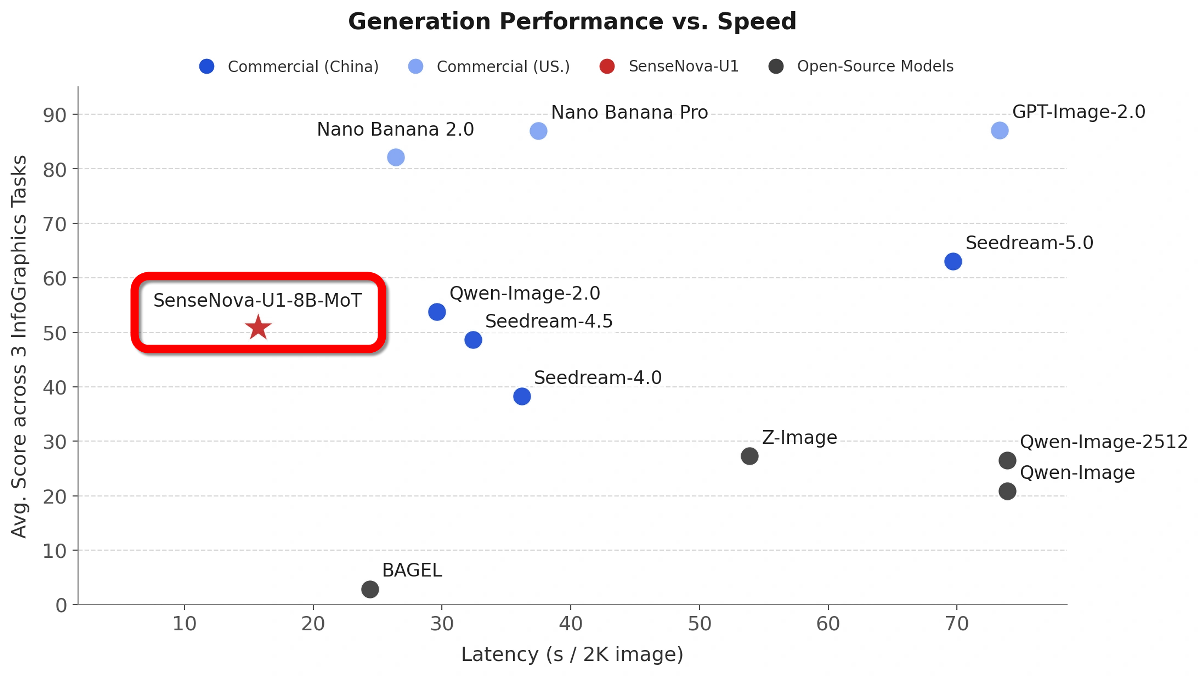
The graph below shows the generation time on the horizontal axis and the quality score of the generated image on the vertical axis. It can be seen that the SenseNova U1 is high-performance and produces high-quality images compared to other open models.
SenseNova U1 is distributed via Hugging Face as a base model 'SenseNova-U1-8B-MoT' and a reinforcement-trained model 'SenseNova-U1-8B-MoT-SFT'. The license is the Apache License 2.0.
sensenova/SenseNova-U1-8B-MoT · Hugging Face
https://huggingface.co/sensenova/SenseNova-U1-8B-MoT
sensenova/SenseNova-U1-8B-MoT-SFT · Hugging Face
https://huggingface.co/sensenova/SenseNova-U1-8B-MoT-SFT
SenseTime plans to release larger versions of the SenseNova U1 series and other products in the future.
Related Posts:







in AI, Posted by log1o_hf