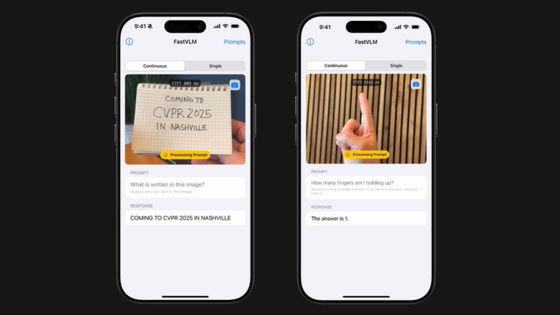
AMD releases proprietary visual language model 'Instella-VL-1B,' trained on AMD GPUs to achieve competitive performance

Semiconductor giant AMD has announced its first visual language model (
Instella-VL-1B: First AMD Vision Language Model — ROCm Blogs
https://rocm.blogs.amd.com/artificial-intelligence/Instella-BL-1B-VLM/README.html
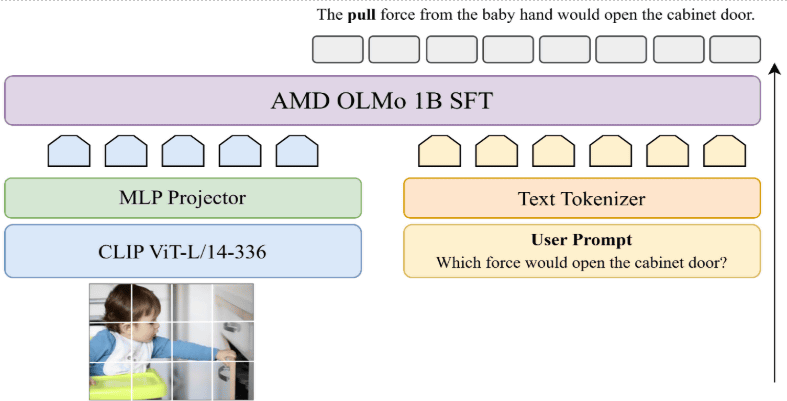
Instella-VL-1B is a multi-modal model with 1.5 billion parameters that combines a vision encoder with 300 million parameters and a language model with 1.2 billion parameters.
To build Instella-VL-1B, AMD combined datasets such as LLaVA , Cambrian , and Pixmo , and created new data mixtures in both the pre-training and SFT (supervised fine-tuning) stages. Specifically, they enhanced the model's document understanding capabilities by employing richer document-related datasets such as M-Paper , DocStruct4M , and DocDownstream .
With the new pre-training dataset (7M examples) and SFT dataset (6M examples), Instella-VL-1B significantly outperforms similarly sized open source models (such as LLaVa-OneVision and MiniCPM-V2 ) on both general visual language tasks and OCR -related benchmarks. It also outperforms the open weight model InternVL2-1B on general benchmarks and achieves comparable performance on OCR-related benchmarks.
Here's a comparison of its performance in various benchmarks with competing AI models:
| Model name | Visual Encoder | Text Encoder | GQA | SQA | POPE | MM-Bench | SEED-Bench | MMMU | RealWorldQA | MMStar | OCRBench | Text VQA | AI2D | ChartQA | DocVQA | InfoVQA |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
DeepSeek-VL-1.3B | SigLIP | DeepSeek-LLM-1B | -- | 64.52 | 85.80 | 64.34 | 65.94 | 28.67 | 50.20 | 38.30 | 41.40 | 57.54 | 51.13 | 47.40 | 35.70 | 20.52 |
InternVL2-1B | InternViT | Qwen2-0.5B | 55.06 | 89.54 | 87.40 | 61.70 | 65.90 | 32.40 | 51.90 | 46.18 | 74.40 | 69.60 | 62.40 | 71.52 | 80.94 | 46.30 |
InternVL2.5-1B | InternViT | Qwen2-0.5B-instruct | 56.66 | 93.90 | 89.95 | 68.40 | 71.30 | 35.60 | 58.30 | 47.93 | 74.20 | 72.96 | 67.58 | 75.76 | 82.76 | 53.62 |
TinyLLaVA-2.4B | SigLIP | Gemma | 61.58 | 64.30 | 85.66 | 58.16 | 63.30 | 32.11 | 52.42 | 37.17 | 28.90 | 47.05 | 49.58 | 12.96 | 25.82 | 21.35 |
TinyLLaVA-1.5B | SigLIP | TinyLlama | 60.28 | 59.69 | 84.77 | 51.28 | 60.04 | 29.89 | 46.67 | 31.87 | 34.40 | 49.54 | 43.10 | 15.24 | 30.38 | 24.46 |
LLaVA-OneVision-1B | SigLIP | Qwen2-0.5B | 57.95 | 59.25 | 87.17 | 44.60 | 65.43 | 30.90 | 51.63 | 37.38 | 43.00 | 49.54 | 57.35 | 61.24 | 71.22 | 41.18 |
MiniCPM-V-2 | SigLIP | MiniCPM-2.4B | -- | 76.10 | 86.56 | 70.44 | 66.90 | 38.55 | 55.03 | 40.93 | 60.00 | 74.23 | 64.40 | 59.80 | 69.54 | 38.24 |
Instella-VL-1B | CLIP | AMD OLMO 1B SFT | 61.52 | 83.74 | 86.73 | 69.17 | 68.47 | 29.30 | 58.82 | 43.21 | 67.90 | 71.23 | 66.65 | 72.52 | 80.30 | 46.40 |
Instella-VL-1B is an adaptation and optimization of the LLaVA code base for AMD hardware and model architectures, and is trained exclusively using publicly available datasets. It was trained using AMD's generative AI GPU, the AMD MI300X, and AMD described Instella-VL-1B as 'a testament to AMD's commitment to advancing open source AI technology in multimodal AI.'
In keeping with its open source commitment, AMD is sharing not only the weights of the Instella-VL-1B model, but also detailed training configurations, datasets and code.
GitHub - AMD-AIG-AIMA/InstellaVL
https://github.com/AMD-AIG-AIMA/InstellaVL
Related Posts: