Netflix has announced a newly developed video editing framework called 'VOID,' which allows users to remove any object from a video and then generate a new video by simulating the movement of the remaining objects using physics.

Netflix and a research team from Sofia University in Bulgaria have announced a video editing framework called ' Video Object and Interaction Deletion (VOID) .' While traditional deletion methods are good at filling in backgrounds and correcting appearances, they often produce unnatural results in scenes involving complex physical interactions between objects. VOID was designed to solve these problems.
[2604.02296] VOID: Video Object and Interaction Deletion
VOID: Video Object and Interaction Deletion
https://void-model.github.io/
Traditional video object removal methods excel at filling in the background behind removed objects and correcting visual inconsistencies such as shadows and reflections. However, existing models often produce unnatural results when the object to be removed is colliding with or supporting other objects. VOID was developed to generate physically plausible counterfactual videos in such complex scenarios.
In short, the biggest feature of VOID is that it can simulate the physical causal relationships of how the surroundings would behave if an object were removed from a video. For example, if you use VOID to remove the domino in the middle of the row in a video of dominoes falling (left), the edited video (right) will show that the subsequent dominoes remain standing.

When you edit a video (two images on the left) showing a person jumping into a pool and creating a big splash, using the VOID function to remove only the person (two images on the right), you get no splash and the inflatable ring barely moves.

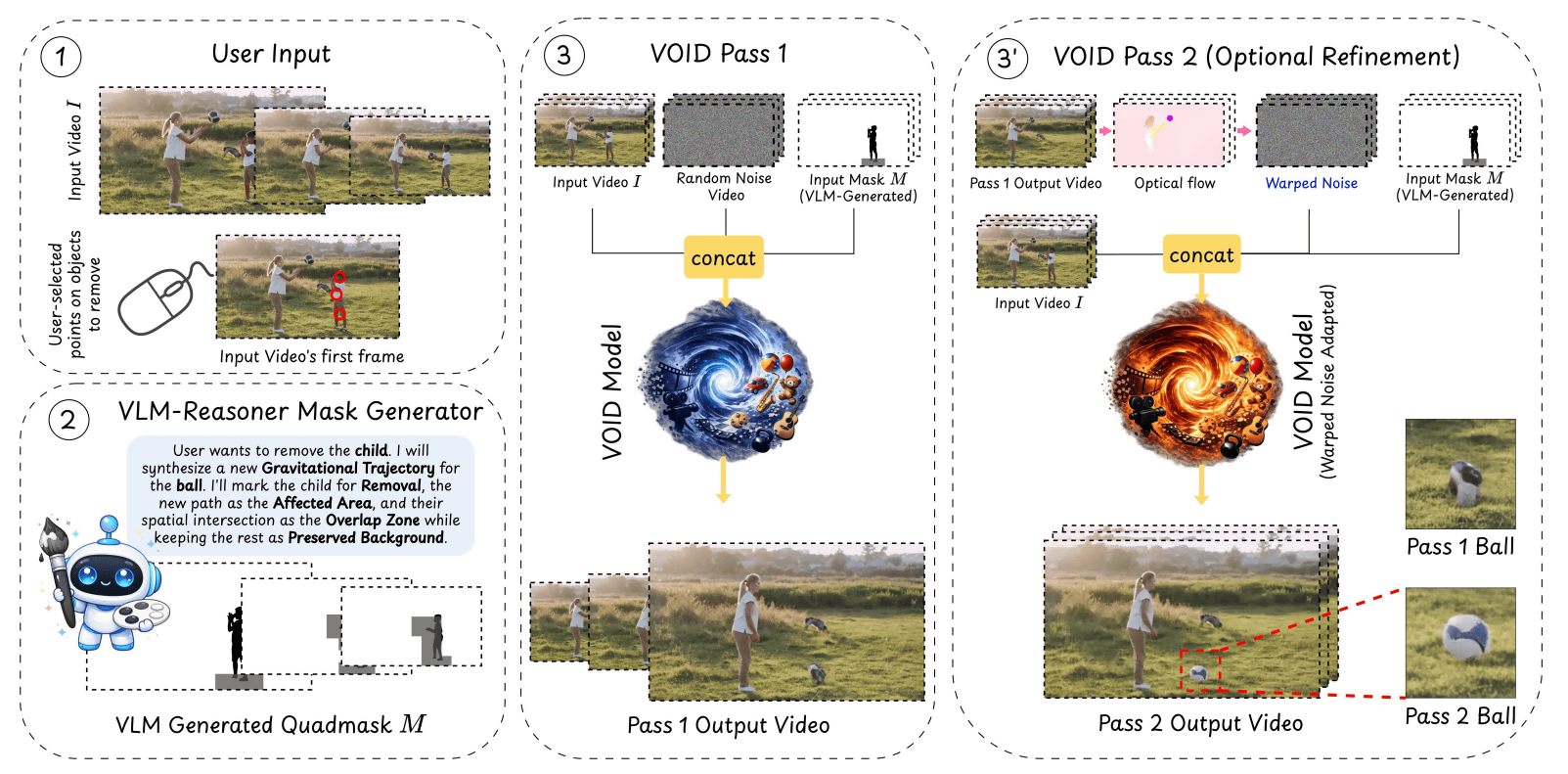
VOID employs a mechanism called Quadmask, which utilizes a Visual-Linguistic Model (VLM). When a user selects an object to be deleted by clicking on several points, the VLM infers the context of the scene and identifies areas affected by the object's deletion, such as the trajectory of the falling object or areas where collisions will be avoided. These areas are then encoded as a quadmask using four colors (white, black, light gray, and dark gray), an extension of the conventional trimask, providing detailed pixel space guidance to the video diffusion model.

VOID is built on
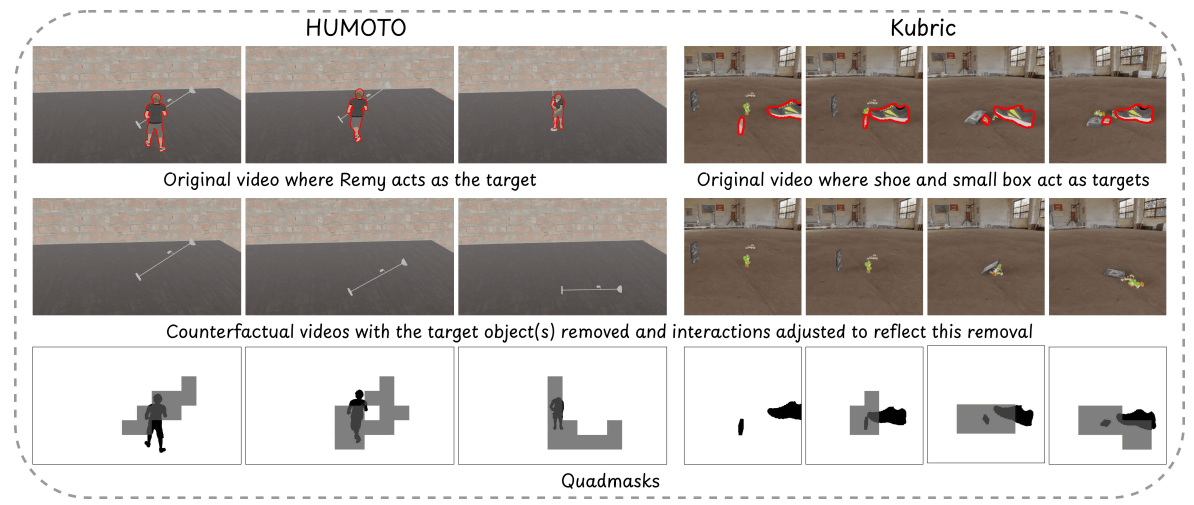
The model was trained using approximately 1900 sets of rigid body dynamics data generated by the Kubric physics simulation engine, and approximately 4500 sets of data utilizing HUMOTO, a human motion capture dataset. By using this data for training, VOID is said to exhibit high generalization performance even for unknown scenes. For example, physical phenomena not directly included in the training data, such as 'if you remove the person holding the balloon, the balloon will fly' or 'if you remove the person pressing the switch, the mixer will stop working,' can be appropriately processed and reflected in the video by combining them with VLM's knowledge.
At the time of writing, VOID is published as an academic preprint paper, and is in the stage of technical disclosure to the research community. A demo is available on Hugging Face.
VOID - a Hugging Face Space by sam-motamed
https://huggingface.co/spaces/sam-motamed/VOID
Furthermore, the source code for VOID is available on GitHub under the Apache 2.0 license .
Netflix/void-model
https://github.com/Netflix/void-model
Related Posts:







