NVIDIA announces 'Nemotron 3 Super,' a 120 billion parameter hybrid MoE open weight AI model that supports Japanese.

NVIDIA has announced Nemotron 3 Super , a new open model specialized for agent-based AI inference. Nemotron 3 Super employs the MoE architecture, which has 120 billion (120B) total parameters and 12 billion (12B) effective parameters, achieving both high computational efficiency and accuracy.
Introducing Nemotron 3 Super: An Open Hybrid Mamba-Transformer MoE for Agentic Reasoning | NVIDIA Technical Blog
https://developer.nvidia.com/blog/introducing-nemotron-3-super-an-open-hybrid-mamba-transformer-moe-for-agentic-reasoning/
NVIDIA Nemotron 3 Super - NVIDIA Nemotron
https://research.nvidia.com/labs/nemotron/Nemotron-3-Super/
New NVIDIA Nemotron 3 Super Delivers 5x Higher Throughput for Agentic AI | NVIDIA Blog
https://blogs.nvidia.com/blog/nemotron-3-super-agentic-ai/
nvidia/NVIDIA-Nemotron-3-Super-120B-A12B-Base-BF16 · Hugging Face
https://huggingface.co/nvidia/NVIDIA-Nemotron-3-Super-120B-A12B-Base-BF16
Nemotron 3 Super was designed to solve the challenges of multi-agent systems, such as context explosion caused by retransmission of history and inference steps, and the increased computational cost associated with complex inference. It supports 20 languages, including English, Japanese, Spanish, French, German, Italian, Chinese, Arabic, Hebrew, Hindi, and Korean.
For example, it introduces Latent MoE , which can call four times as many experts with the same inference cost, and Multi-Token Prediction (MTP) , which simultaneously predicts multiple future tokens in a single pass, shortening generation time. Additionally, it is the first Nemotron 3 series model to adopt Latent MoE, MTP, and NVFP4 pre-training.
Furthermore, a hybrid backbone that combines a sequence-efficient Mamba layer with a precise Transformer layer has been used to achieve four times the memory and computational efficiency. Nemotron 3 Super is natively pre-trained in the NVFP4 format, optimized for the NVIDIA Blackwell platform, and achieves four times the inference speed while maintaining accuracy compared to FP8 on Hopper.
This latest addition to the Nemotron family isn't just a bigger Nano.
— NVIDIA AI Developer (@NVIDIAAIDev) March 11, 2026
✅ Up to 5x higher throughput and 2x accuracy than the previous version
✅ Latent MoE that calls 4x as many expert specialists for the same inference cost⁰
✅ Multi-token prediction that dramatically reduces… pic.twitter.com/18KgqdN0H4
The training process consists of three stages: pre-training, supervised fine-tuning (SFT), and multi-environment reinforcement learning. A total of 25 trillion tokens were used in pre-training, including 10 trillion unique tokens focused on inference and coding.
Furthermore, supervised fine-tuning was performed using approximately 7 million of the 40 million post-training examples, including inference, command-following, coding, safety, and multi-step agent tasks. Finally, reinforcement learning was performed across 21 different environment configurations and 37 datasets, with approximately 1.2 million environment rollouts generated during training. This resulted in a native context window of 1 million (1M) tokens, allowing the agent to maintain long-term memory and continue consistent reasoning without losing track of the goal.
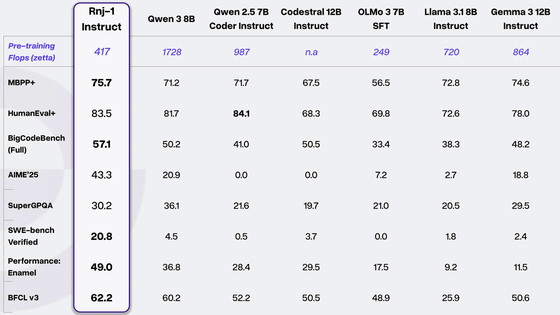
In terms of performance, it achieves up to 5x the throughput and up to 2x the accuracy compared to the previous Nemotron Super. Benchmarks show superior accuracy compared to similarly sized open models, and a configuration built with the NVIDIA AI-Q research agent achieved first place in DeepResearch Bench and DeepResearch Bench II. It also achieved 2.2x to 7.5x higher inference throughput under certain conditions compared to other models such as GPT-OSS-120B and Qwen3.5-122B.
Announcing NVIDIA Nemotron 3 Super!
— Bryan Catanzaro (@ctnzr) March 11, 2026
????120B-12A Hybrid SSM Latent MoE, designed for Blackwell
????36 on AAIndex v4
????up to 2.2X faster than GPT-OSS-120B in FP4
????Open data, open recipe, open weights
Models, Tech report, etc. here: https://t.co/CAYpP1iK3i
And yes, Ultra is coming! pic.twitter.com/QuguMQaC8S
Sam Hogan, CEO of Inference Research, an AI-native investment firm, tested Nemotron 3 Super for several weeks and called it 'the best open-source, American-made model, hands down. Super fast. Perfect for agent and tool invocation use cases.'
We've been testing Nemotron 3 Super for the last few weeks.
— Sam Hogan ??????? (@samhogan) March 11, 2026
TL;DR: it's easily the best Open Source American model for its size. Super fast. Great for agents and tool-calling use cases.
We'll be shipping a series of post-trained Nemtron models in the coming weeks. https://t.co/AwVi2ueQLZ
Nemotron 3 Super's base model, weights (parameters), dataset, and training recipes are all publicly available, allowing developers to freely customize and deploy it on their own infrastructure. Available checkpoints include NVFP4, FP8, and BF16 formats, and can be accessed through Hugging Face , NVIDIA NIM , and OpenRouter . The minimum GPU requirements are H100x1 for the NVFP4 version, H100x2 for the FP8 version, and H100x8 for the BF16 version.
A demo of the Nemotron 3 Super 120B (A12B) model is also available on build.nvidia.com.
nemotron-3-super-120b-a12b Model by NVIDIA | NVIDIA NIM
https://build.nvidia.com/nvidia/nemotron-3-super-120b-a12b

NVIDIA says that many companies, including Perplexity, Palantir, and Siemens, are already integrating and deploying Nemotron 3 Super, and it is expected to be used in a wide range of fields, including software development, cybersecurity triage, and financial analysis.
Related Posts:







in AI, Posted by log1i_yk