As Wikipedia celebrates its 25th anniversary, we spoke with the head of machine learning and data engineering at the Wikimedia Foundation about AI, donation banners, and data centers.

by
January 15, 2026 marks the 25th anniversary of Wikipedia, the world's largest online encyclopedia. We had the opportunity to interview Chris Albon, Head of Machine Learning and Data Engineering at the Wikimedia Foundation, via email, and asked him a variety of questions.
Chris Albon – Fondation Wikimedia
https://wikimediafoundation.org/fr/profile/chris-albon/
A data scientist, Albon has worked for technology companies and nonprofits for over 10 years. He has served as Head of Machine Learning at the Wikimedia Foundation since January 2020 and as Head of Machine Learning and Data Engineering since January 2025, leading the development and implementation of artificial intelligence across Wikipedia and other Wikimedia projects.
GIGAZINE (hereinafter referred to as G):
Albon had previously shared with us the theme of 'Is a human-written Wikipedia essential in the age of AI?' Could you please explain in more detail, including your intentions and reasons for choosing this theme?
Chris Albon (hereinafter referred to as CA):
Wikipedia forms the foundation of knowledge on the internet, powering generative AI tools, search engines, voice assistants, and more. No matter where people turn on the web for their answers, they still rely on Wikipedia as their source of truth.
AI acts as an intermediary in machine-curated knowledge. It gathers and presents information from a variety of sources that are usually hidden or opaque. This means people are at high risk of being exposed to unverified and misleading information resulting from AI hallucinations. In contrast, with human-created sources like Wikipedia, it is easy to verify the origin of information and the process by which it is presented.
Wikipedia is a vast repository of knowledge created collaboratively by volunteers from around the world, and we are constantly adding reliable content to reduce bias and make the internet more inclusive. Wikipedia is the only site on the internet that guarantees verifiability, neutrality, and transparency, and therefore must continue to provide information.
G:
The Wikimedia Foundation is known for its AI development and research. For example, in 2015, it reportedly developed ORES, an open-source tool that checks the quality of articles after they are edited or revised.

What specific machine learning models are currently being developed and maintained by the Wikimedia Foundation, and how do they benefit the public?
CA:
The Wikimedia Foundation recently announced a three-year strategy to define the future use of AI on Wikipedia and other Wikimedia projects. With this strategy, the Foundation aims to build capabilities that remove technical barriers, allowing the people at the core of Wikipedia to spend their valuable time on what they truly want to achieve, rather than getting bogged down in technical issues.
We also continually explore new tools, experiments, and projects with Wikimedia volunteers from the early stages, ensuring that development is driven by their input and meets their needs.
Since 2010, some volunteers have been using AI and machine learning (ML) tools to simplify particularly time-consuming and repetitive tasks. For example, many editors use specialized tools to patrol Wikipedia, including bots that help volunteers quickly identify and correct erroneous edits. Volunteers have developed and enforced Wikipedia-wide guidelines for the responsible use of AI/ML tools, working to ensure they are used to best support human contributors.
G:
In June 2025, Wikipedia announced a trial of an AI summarization feature, but the project was reportedly frozen due to opposition from the editor community. This was attributed to a lack of discussion involving the editor community. A Wikimedia Foundation project manager commented at the time, 'We should have presented this concept in a forum and discussed it repeatedly as early as March 2025.'
Wikipedia's test of displaying AI-generated summaries at the beginning of articles is halted due to editor backlash - GIGAZINE
Opinions are divided on the adoption of AI. How does the Wikimedia Foundation evaluate the advantages and disadvantages of each type of AI?
CA:
The Wikimedia Foundation has been exploring ways to make Wikipedia and other Wikimedia projects more accessible to readers around the world. This includes opt-in experiments, such as AI summarization, which aims to make complex Wikipedia articles more accessible to people with a range of reading levels. As part of the normal process for these experiments, we consult with volunteers to make decisions about how to build the feature.
The discussion around this feature is an example of this process, where we prototyped an idea and then asked Wikipedia's volunteer community for their input. We often get diverse feedback from volunteers, which we use to inform our decisions, and sometimes even change course. This is what keeps Wikipedia a truly collaborative platform for human knowledge.

by CAlbon (WMF)
G:
Each AI model collects various information from the internet to use as data, but Wikipedia is by far the most important source of information. To celebrate Wikipedia's 25th anniversary, news broke that Microsoft, Meta, Amazon, Perplexity, and Mistral AI have been officially announced as paid program partners of Wikipedia.
Microsoft, Meta, Amazon, Perplexity, and Mistral AI officially announced as paid program partners of Wikipedia - GIGAZINE
I'm assuming that the Wikimedia Foundation received inquiries from these companies expressing interest in partnering, but when did these initial contacts occur, and how long did it take from the initial discussions to the actual partnership?
CA:
Please understand that, as with most sales and contracting processes, it is difficult to share an exact timeframe for these discussions.
As the largest resource for verified encyclopedic information, Wikipedia and other Wikimedia businesses are the driving force behind generative AI tools, search engines, voice assistants, and more. The Wikimedia Foundation has been in contact with several companies in the technology industry for many years. With the rise of generative AI over the past few years, we welcome ongoing dialogue with AI developers to understand the needs of their users and are currently exploring how to provide proper attribution when Wikimedia content appears on third-party platforms.
Prior to the current AI boom, the commercial paid product Wikimedia Enterprise was launched in 2021, and in 2022 some contractual partnerships were formalized, including early corporate customers Google and the Internet Archive.
G:
OpenAI and Anthropic were not included among the five program partners announced in the release. Their AI crawlers also appear to be a significant contributor to Wikipedia traffic. Were these companies invited to participate?
CA:
Again, we welcome collaboration from all companies, including AI companies, that commercially reuse Wikimedia content to ensure that it is used responsibly and contributes to our mission of spreading knowledge. We continue to engage with all potential partners to explore ways to support Wikipedia's long-term sustainability.
G:
On a lighter note, what is your favorite Wikipedia article or the one that made the biggest impression on you?
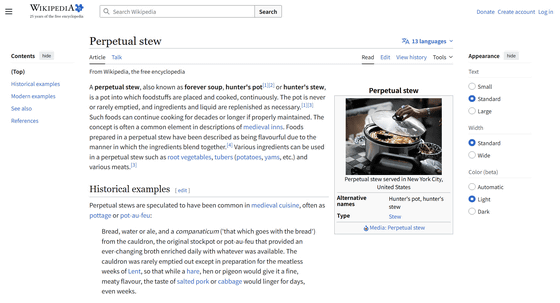
CA:
' Perpetual Stew '! The reason is that I have never tried it and it's something I've always wanted to try.
G:
Next, I'd like to talk about Wikipedia's structure, uniqueness, and volunteer model. GIGAZINE also sometimes displays donation banners to readers to cover part of the server operating costs. When designing these banners, we heavily referenced Wikipedia's methods, as we assumed that the design would have been established through various
Below is a donation banner actually displayed on Wikipedia, appealing to co-founder Jimmy Wales.

Is Wikipedia's donation banner really the result of repeated A/B testing? Or did it arrive at its current design for other reasons? For donation banner designers around the world, can you share the rationale behind Wikipedia's donation banner design and thank you page?
CA:
Wikipedia's banners, emails, thank you pages, and more are the result of years of refinement and a combination of techniques. Our content strategy aims to strike the right balance between raising awareness of Wikipedia's unique model, the importance of reader donations, the value of Wikipedia to readers, and thanking donors. The team continually improves and adapts its messaging in response to changing circumstances, success, and feedback.
A/B testing is one important method for understanding the effectiveness of different messaging, but it's not the only factor. Community discussions, reader feedback, the changing global context, editorial direction, localization, and qualitative judgment all play important roles. Our goal is to find messaging that is honest, easy to understand, and appropriate for different regions and readerships.
For example, in Japan, we work with multiple Japanese translators and proofreaders, and starting this year, we've partnered directly with Japanese copywriters to create original fundraising copy in Japanese. This is a deliberate choice, as we believe that culturally sensitive localization is extremely important to ensure clarity and as a sign of respect for our readers.
G:
Please tell us about the technical aspects of Wikipedia, particularly its servers, including the 'technical and organizational background that has allowed it to maintain neutrality for 25 years without relying on an advertising model' and 'your roadmap as technology and product manager for sustaining human wisdom in the digital space.' In 2010, GIGAZINE published an article titled
CA:
As of the time of writing, we operate a total of 2,478 servers, of which 316 are virtual machines. This number fluctuates slightly due to hardware refreshes (typically every 5 years) and the downtime of some hosts for maintenance. These servers run our content delivery network (CDN), databases, object storage, application servers, cluster analytics, and many other services.

by
Victor GrigasSoftware configuration varies depending on the type and purpose of the server, but we operate only open source software on all of our servers, using Debian GNU/Linux as our single platform.
(Editor's note: This response was written between January 20th and 22nd, 2025.)
G:
Because Wikipedia is run by a non-profit organization and volunteers, I imagine it has faced great challenges in managing and operating its servers throughout its history. Looking back over its 25-year history, when do you think Wikipedia's survival was most threatened? And how were you able to overcome that?
CA:
As an organization (and a non-profit at that) that runs one of the most visited websites in the world, we face technical challenges from time to time, but we cannot think of any that are significant enough to threaten Wikipedia's survival.
As part of its annual planning, the Wikimedia Foundation continually evaluates global trends that may affect the operation of Wikimedia projects and works with the global community to respond effectively to external challenges.
As a recent example of this on the technical side, we have been investigating the impact of AI scrapers crawling Wikimedia content to train LLMs (large-scale language models) and for other purposes, which place a significant load on our servers. In response, the Foundation continues to invest in infrastructure protection capabilities, and is prepared to block excessive requests that strain the underlying systems that keep the project available to everyone.

by
G:
In 2025, AWS and Cloudflare went down, making most of the internet inaccessible, but Wikipedia remained unscathed. Could you please explain how you ensure redundancy without relying on CDNs, and in particular the operational structure of your data centers around the world, as outlined in the article by the Wikimedia Foundation?
CA:
The Wikimedia Foundation currently serves all project user traffic from seven data centers (colocation spaces) around the world: three in the United States (San Francisco, Texas, and Virginia), two in Europe (Marseille, France, and Amsterdam, the Netherlands), one in South America (São Paulo, Brazil), and one in Asia (Singapore).
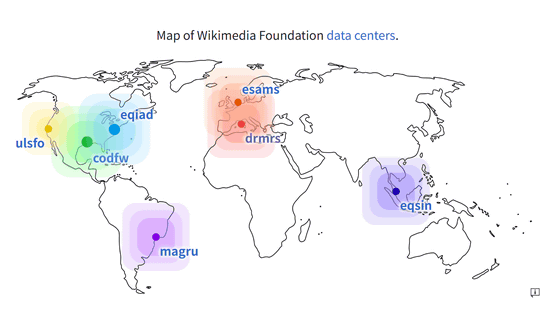
The presence of multiple data centers (Points of Presence, PoPs) contributes to the reliability, redundancy, and performance of the Foundation's websites. The Foundation runs its own CDN on its own hardware in co-location space rented from data center providers.
Typically, users are connected to the nearest PoP via geographic DNS, so users in Japan will be connected to the eqsin PoP in Singapore. If that PoP goes down for maintenance or for any other reason, we redirect users to the next closest PoP, which almost always increases latency. So if there is an issue with the eqsin PoP in Singapore, users in Japan will be connected to the ulsfo PoP in San Francisco, USA.
G:
Finally, if you have any messages for Japanese Wikipedia users, please let us know.
CA:
Keep contributing and keep sharing your free knowledge.

G:
thank you very much.
Related Posts:




in AI, Web Service, Interview, Posted by log1i_yk