Introducing the Chinese-made AI 'GLM-4.7-Flash,' which is more powerful than gpt-oss-20b
Z.ai, a China-based AI company, released a lightweight AI model called ' GLM-4.7-Flash ' that runs locally on January 19, 2026. GLM-4.7-Flash has outperformed OpenAI's '
Introducing GLM-4.7-Flash: Your local coding and agentic assistant.
— Z.ai (@Zai_org) January 19, 2026
Setting a new standard for the 30B class, GLM-4.7-Flash balances high performance with efficiency, making it the perfect lightweight deployment option. Beyond coding, it is also recommended for creative writing,… pic.twitter.com/gd7hWQathC
GLM-4.7-Flash is an AI model that uses MoE architecture , which combines multiple specialized models, with a total of 30 billion parameters and 3 billion active parameters.
GLM-4.7-Flash is a 30B-A3B MoE model.
— Z.ai (@Zai_org) January 19, 2026
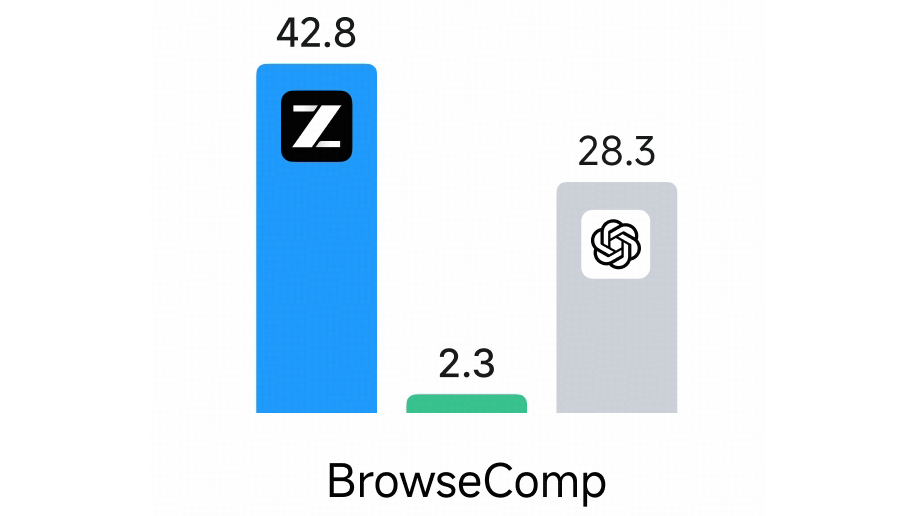
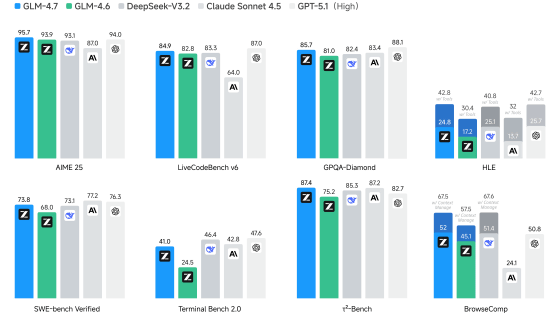
Below are the various benchmark results for 'GLM-4.7-Flash (total number of parameters: 30 billion, active number of parameters: 3 billion)', 'Qwen3-30B-A3B-Thinking-2507 (total number of parameters: 30 billion, active number of parameters: 3 billion)', and 'gpt-oss-20b (total number of parameters: 21 billion, active number of parameters: 3.6 billion)'. GLM-4.7-Flash recorded the highest score in most tests.
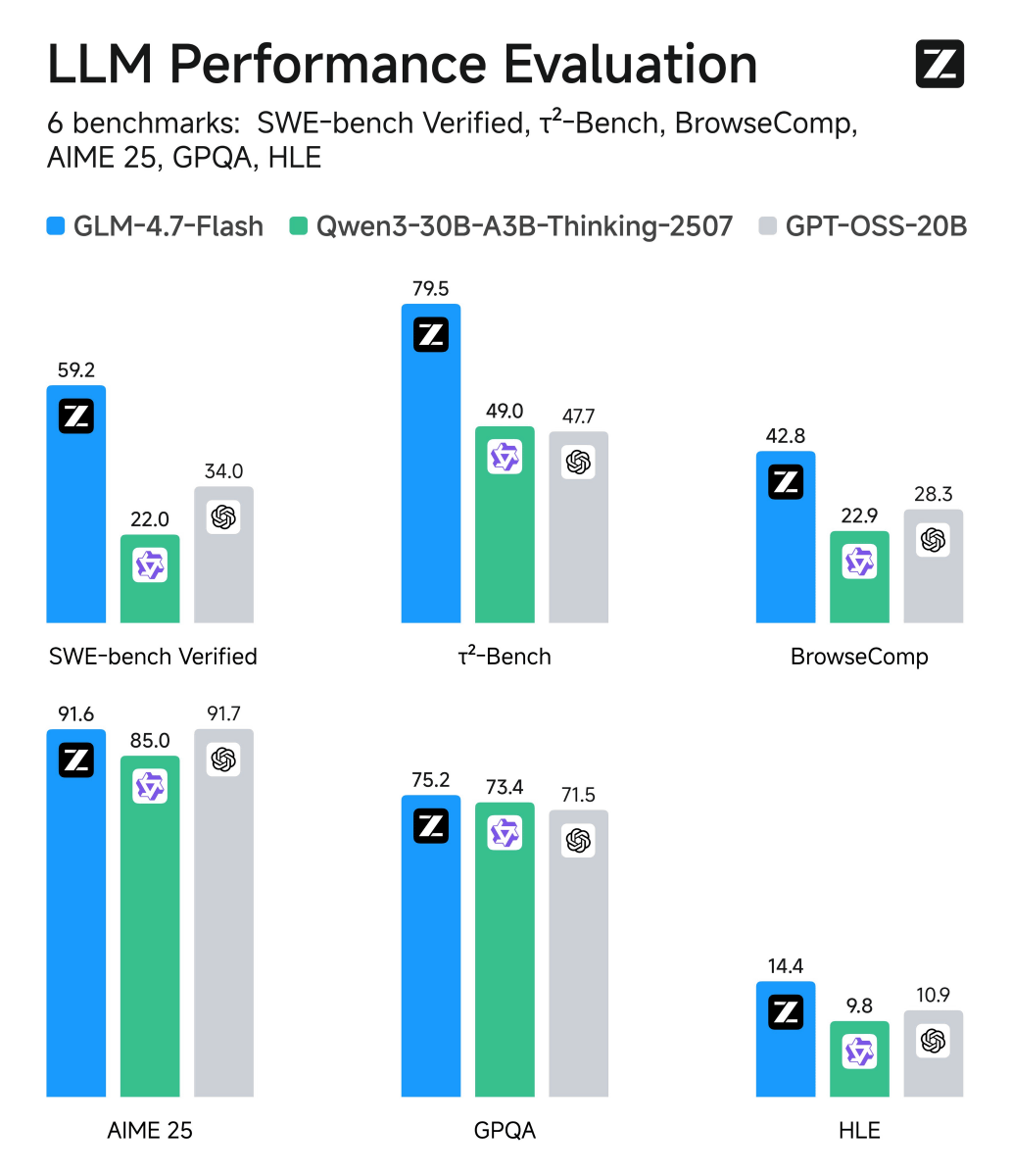
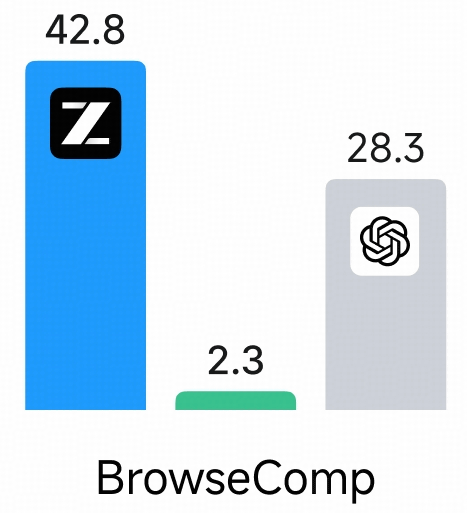
The graph above, which measures web search performance, had an error in the BrowseComp graph. The correct graph is below, showing GLM-4.7-Flash far ahead of Qwen3-30B-A3B-Thinking-2507 and gpt-oss-20b.
GLM-4.7-Flash is developed as an open model, and the model data can be downloaded from the following link. The license is the MIT License.
zai-org/GLM-4.7-Flash · Hugging Face
https://huggingface.co/zai-org/GLM-4.7-Flash
The BF16 version of GLM-4.7-Flash released by Z.ai requires 45GB or more of VRAM to run. In response to a question asking, 'Can it run on a GeForce RTX 4090?', Z.ai advises users to wait for the release of the quantized version.
You can wait for more quantizied versions. The official version is in BF16 and requires over 45GB
— Z.ai (@Zai_org) January 19, 2026
Related Posts:





in AI, Posted by log1o_hf