Can large-scale visual language models 'read a map and find the best route' like humans?

Many people have learned how to read maps since childhood, and can look at subway maps to find the exit they want to go to, look at amusement park maps to find the way to the attractions they want to ride, and look at road maps to find the entrance to a highway. To address the question of whether large-scale visual language models (LVLMs) can read maps and find the right route like humans, researchers have devised a new benchmark called 'MapBench.'
[2503.14607] Can Large Vision Language Models Read Maps Like a Human?
LVLM is a large-scale language model that generates sentences based on images and instructions input by a user, and is expected to be useful in fields such as medical image analysis, autonomous vehicle operation, and image recognition in robotics. If LVLM has performance comparable to humans, it should be able to read the map and navigate the route from the start point to the destination point, given the instructions of the start and destination points and the necessary map.
Therefore, in a paper published on arXiv, a preprint server for unpeer-reviewed papers, a research team from Texas A&M University and the University of California, Berkeley, etc., introduced a new benchmark called 'MapBench' to measure LVLM's map reading ability.
The research team explains that LVLM's ability to read and navigate maps requires 'the ability to recognize visual symbols such as colors, text, areas, and icons on maps', 'spatial understanding to adapt symbols to the physical environment and deal with orientation, perspective, handling dead ends, scaling, etc.', and 'the ability to plan routes between endpoints passing through landmarks and intersections.'

MapBench is designed to measure map reading and navigation tasks using LVLM, based on a representation called the Map Space Scene Graph (MSSG), which structures the visual symbolic and geometric space of a map.
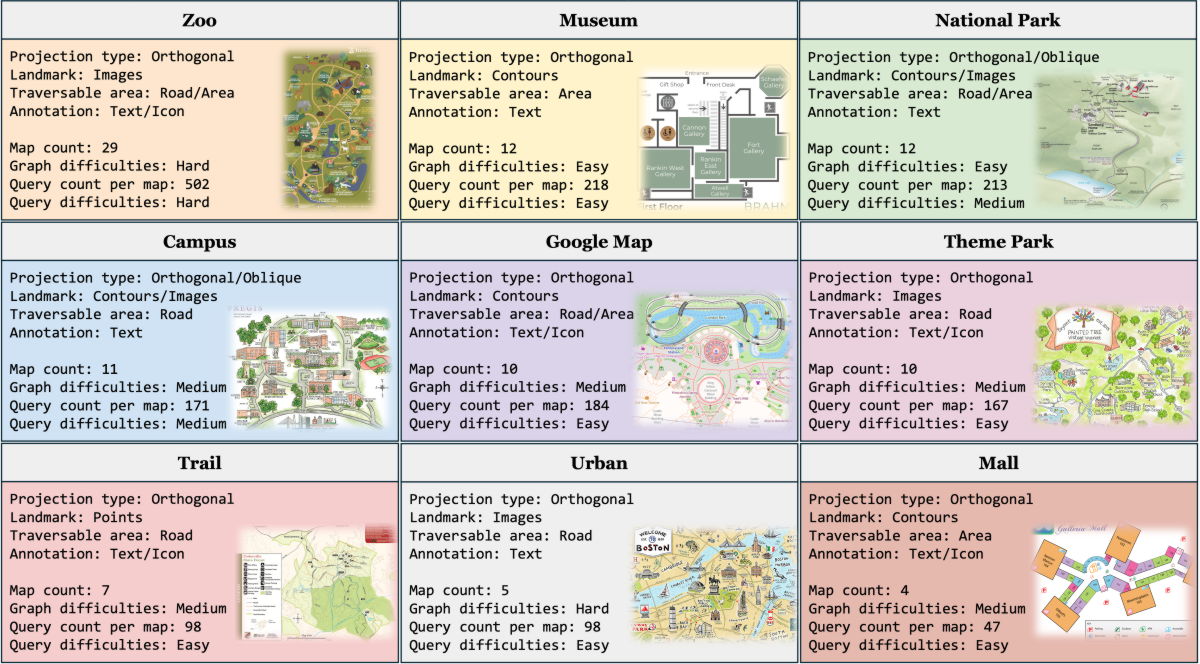
MapBench contains over 1,600 map reading and navigation tasks made from 100 different maps in nine scenarios: zoo, museum, national park, university, Google Maps, theme park, mountain trail, city, and shopping mall. Each map is manually annotated, and the task queries are instructed on the start and end points.
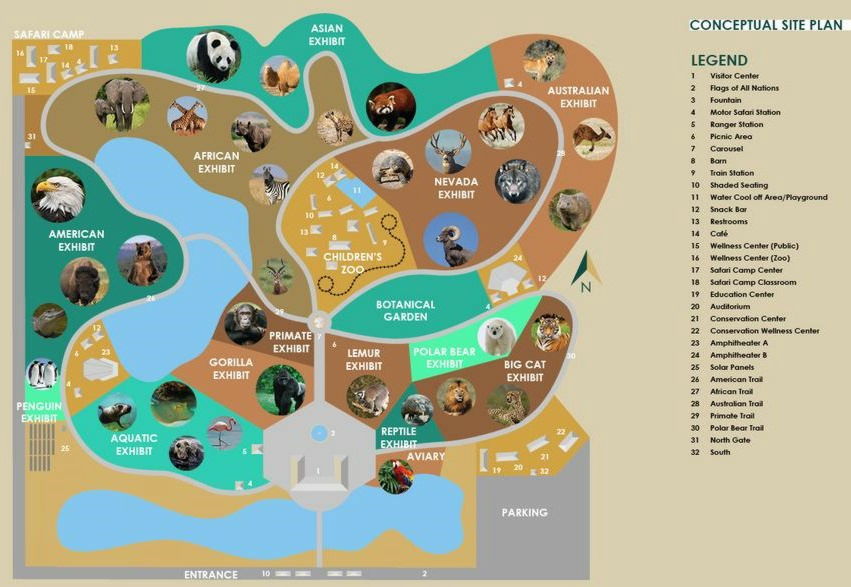
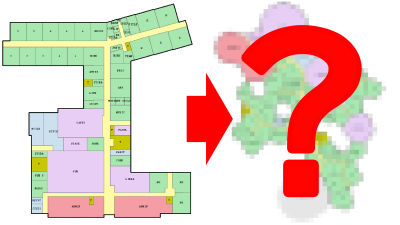
Below is an example of a map included in MapBench. It is a map of the zoo, and the query says 'Please provide me a navigation from Carousel to Safari Camp Classroom.' In this case, if you look at the annotation on the right, the merry-go-round is represented by the number '7' and the Safari Camp Classroom is represented by the number '18,' so you just need to specify the route from '7' in the center of the map to '18' in the upper left of the map.
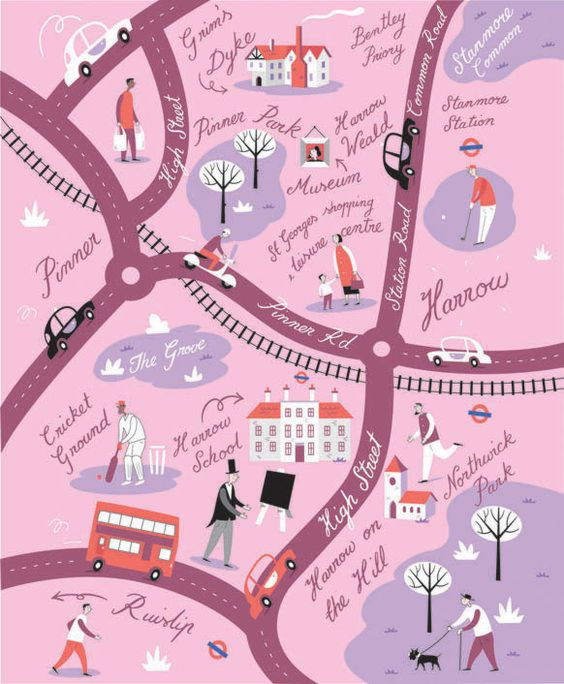
In addition, in the following example, which is a map of an urban area, a task such as 'Please provide me a navigation from Pinner Park to Harrow on the Hill' is given. The starting point, 'Pinner Park', is slightly above the center of the map, and the end point, 'Harrow on the Hill', is in the lower right. If you can navigate this route, it's OK.
The team used MapBench to test models including Meta's Llama-3.2, Alibaba's Qwen2-VL, and OpenAI's GPT-4o mini and GPT-4o, both with
Below is a table showing the test results for each map classification. If the actual shortest distance was correctly navigated, the score was '1', and the closer the score was to '1', the higher the accuracy of navigation.
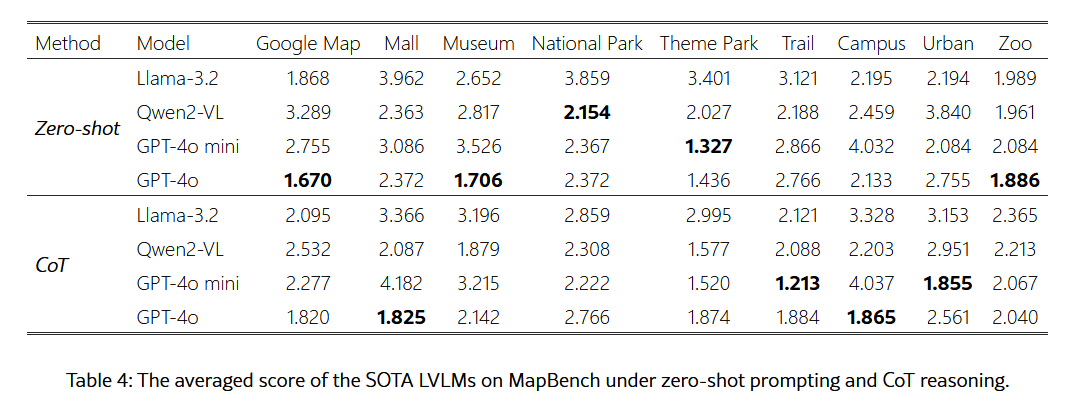
The research team noted that LVLM's performance is significantly below theoretically optimal navigation, revealing important limitations in multimodal information understanding, spatial reasoning, and decision-making under complex long-term planning. They also noted that LVLM's map-reading ability has not yet caught up with humans.
Related Posts:





in AI, Software, Web Service, Science, Posted by log1h_ik