Bluesky is developing a mechanism to allow users to explicitly indicate whether or not they want their data used to train generative AI

On March 10, 2025, Bluesky CEO Jay Graeber revealed that he is developing a system that would allow people to explicitly indicate whether or not they want their data used to train generative AI.
Bluesky is weighing a proposal that gives users consent over how their data is used for AI | TechCrunch
On November 16, 2024, Bluesky stated that 'Bluesky will not use content posted by users for AI training.' However, Bluesky has a mechanism for keeping all posts open, and technically anyone can retrieve all Bluesky posts and use them for AI training. This has created a situation where 'just because the Bluesky operator does not train the AI does not mean that the posts will not be used for AI training.'
Unlike X (formerly Twitter), Bluesky has stated that it will not use posts to train AI - GIGAZINE

Meanwhile, on November 26, 2024, an AI training dataset created by acquiring 1 million posts on Bluesky was published on the AI platform Hugging Face, proving that third parties can train AI systems using content from Bluesky users. The dataset is no longer available at the time of writing.
An example has emerged in which 'Bluesky operators do not use user posts for AI learning, but third parties can learn AI,' and a data set of 1 million posts is made public on Hugging Face via Bluesky's API - GIGAZINE
In response to this situation, CEO Graeber explained at the creative conference ' SXSW 2025 ' held in March 2025 that 'Bluesky is working with partners to develop a mechanism that allows users to express their opinions on how their data is used or not used to train generative AI.' CEO Graeber's remarks can be seen from around 33 minutes and 30 seconds.
Bluesky's CEO on the Future of Social Media | SXSW LIVE - YouTube
Graeber added, 'This framework will allow users to decide how much of their content they want to be used to train AI. We trust that choice.' 'The framework we're developing is similar to how websites can indicate to search engines whether they want to be scraped. Many websites are publicly available on the internet, but can prevent crawlers from scraping them by including a robots.txt file on their site.'
Bluesky also reported in November 2024 that it was developing a 'mechanism to explicitly state whether or not users agree to the use of content for AI learning,' and at that time said that it was considering introducing it in a form similar to 'robots.txt.'
Bluesky is developing a mechanism to allow users to indicate whether they agree or disagree with AI learning, but it is unclear whether AI developers will follow the user's wishes - GIGAZINE

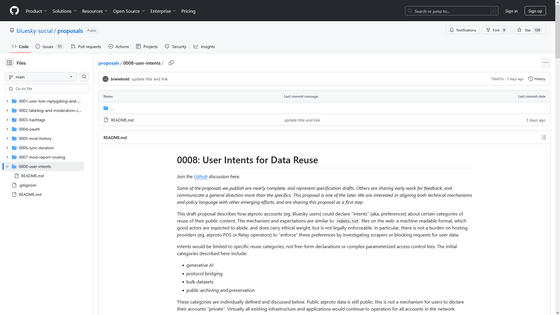
Bluesky has published details of the function that clearly indicates whether or not data can be learned at the following link.
proposals/0008-user-intents at main · bluesky-social/proposals · GitHub
https://github.com/bluesky-social/proposals/tree/main/0008-user-intents
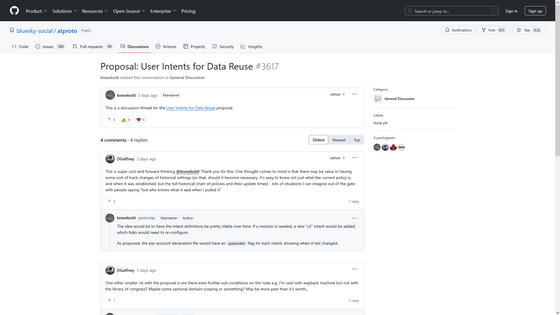
You can also join the feature discussion at the following links:
Proposal: User Intents for Data Reuse · bluesky-social/atproto · Discussion #3617 · GitHub
https://github.com/bluesky-social/atproto/discussions/3617
Related Posts:




in Software, Web Service, Video, Posted by log1r_ut