Google DeepMind releases a demo movie that performs tasks in the office, such as location guidance in natural language

By utilizing Gemini 1.5's long context window of up to 1 million tokens, Google DeepMind has summarized in a paper that it is now possible to solve office tasks in natural language, and has released a demo movie.
[2407.07775v1] Mobility VLA: Multimodal Instruction Navigation with Long-Context VLMs and Topological Graphs

AI models with a large context window can handle a lot of information at once. In this study, DeepMind filmed videos showing the office and home, and had the AI watch them to learn information about the environment, such as 'where is what.'
By instructing the AI in natural language, the AI was able to guide the user to the destination based on the movie information and the input from the camera. Below is a demo movie that actually performs the task of 'tell me where I can draw something.'
View this post on Instagram
When the AI-enabled robot is told by voice, 'Tell me where I can draw something,' the robot responds, 'Gemini will think about it. Please wait a moment.'

After a while the robot began to move slowly.

We successfully guided the user to the whiteboard.

The overview of the model looks like this. Other examples of tasks that can be completed include the question 'Where should I return this?' while holding an object, and the question 'Where can I charge it?' while showing a smartphone.
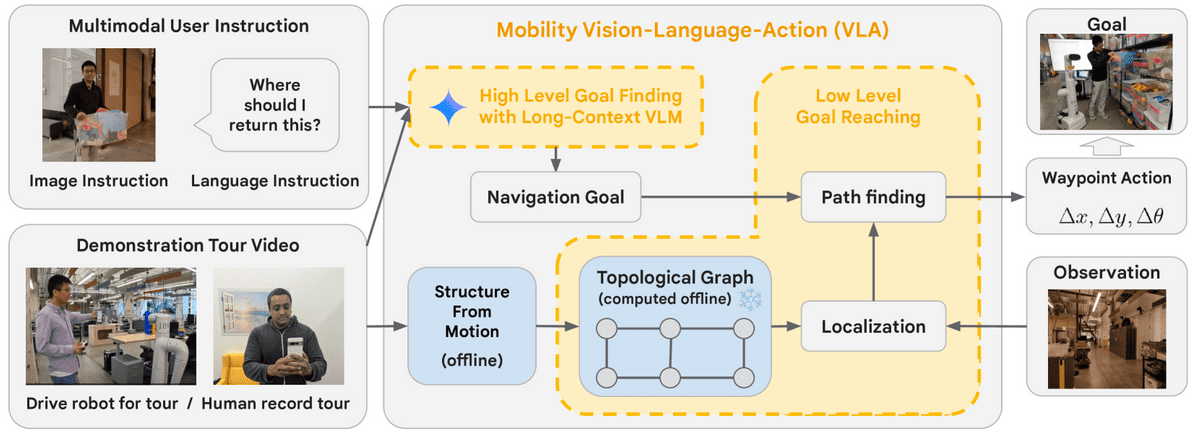
The research team called their results a great success, saying, 'We achieved end-to-end success rates of up to 90 percent on previously infeasible navigation tasks involving complex reasoning and multimodal user instruction in large-scale real-world environments.'