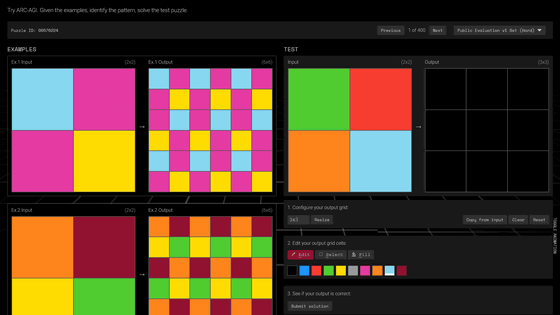
GPT-4o reaches 50% score on AI benchmark ARC-AGI, smashing the previous best score of 34%
AI researcher Ryan Greenblatt announced that by using GPT-4o in an innovative way, he was able to achieve a 50% accuracy rate on
Getting 50% (SoTA) on ARC-AGI with GPT-4o
https://redwoodresearch.substack.com/p/getting-50-sota-on-arc-agi-with-gpt

ARC-AGI is provided with several examples and problems, as shown in the figure below. It is OK if the system can infer the rules from the examples and correctly output the results that correspond to the problem diagram. When a human performs this task, even a child can achieve a score of 85% to 100%, but the highest score that ARC-AGI has achieved so far is 34%, which is a particularly noticeable difference from humans in numerous benchmarks.
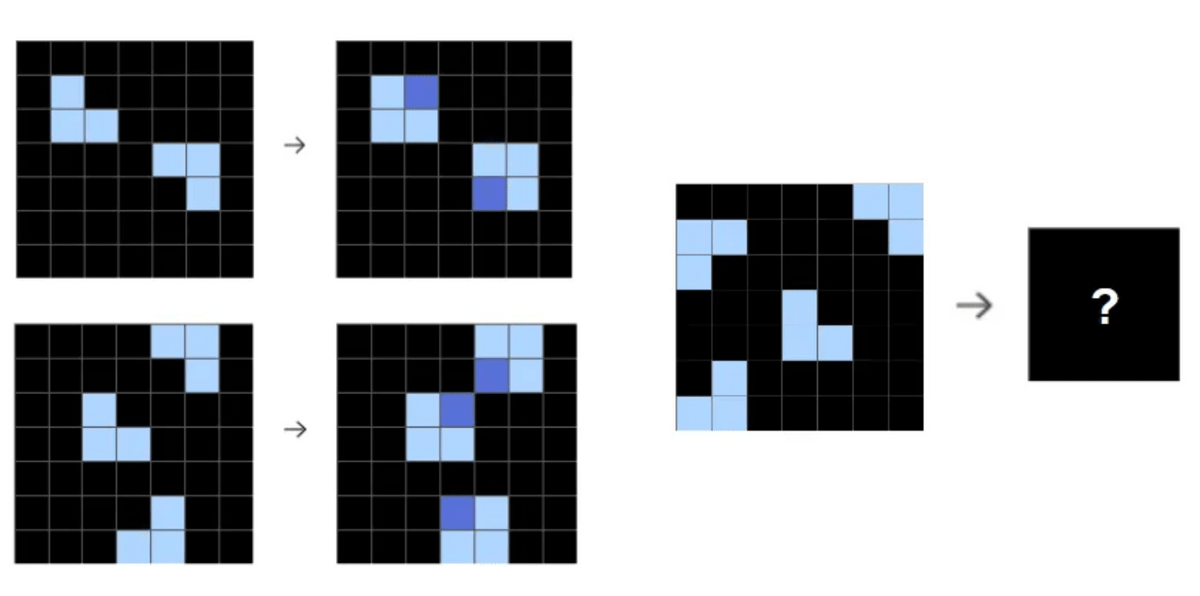
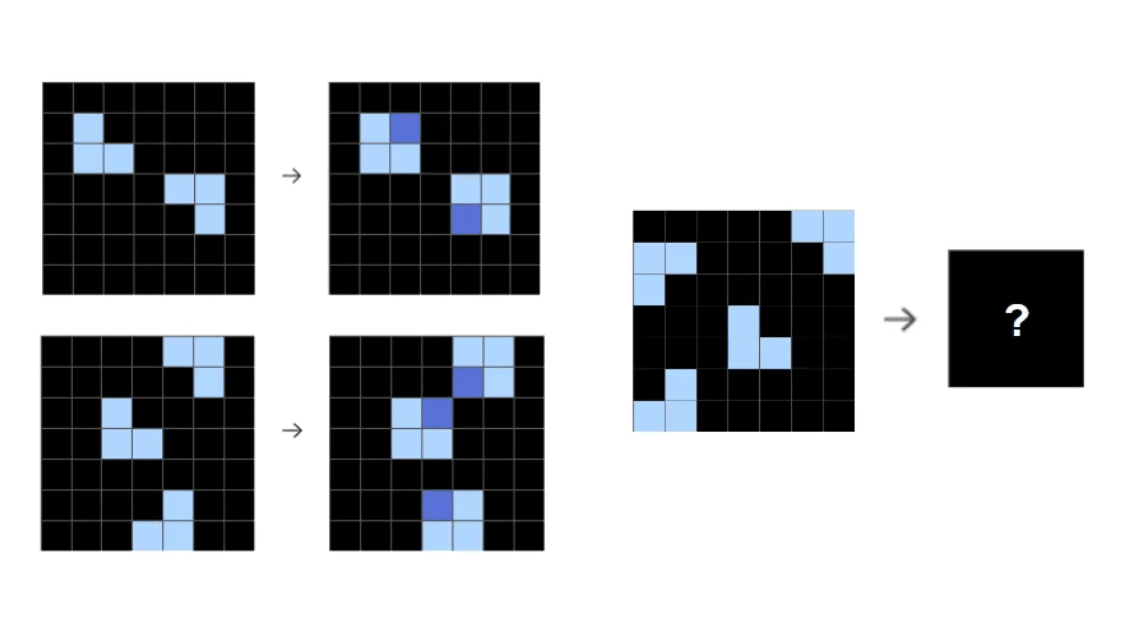
The above problem is simple, so GPT-4o can solve it correctly without any special ingenuity, but the actual problem is more complex, as shown in the figure below.

Greenblatt's idea is to have GPT-4o generate a large number of Python programs that generate answers from problems, and then apply them to all examples to use the programs that seem promising. In reality, it took six days to achieve a 50% score, including devising ways to express the problem so that GPT-4o could read it, providing a few shots of prompts with concrete examples to carefully advance reasoning step by step, and prompts to further correct promising candidates.
The code used to achieve a score of 50% is
Over the course of six days, Greenblatt repeatedly revised and updated the prompts for solving ARC-AGI. In the first version, V0, the team generated 1,024 Python programs and got 25% correct answers. In the final version, V2, the team generated 2,048 programs and got 34% correct answers.
By combining all the versions, the accuracy rate was improved to 37%, and by adding a step to correct promising candidates, it reached 50%. It has been confirmed that the accuracy rate improves by increasing the number of programs generated, and Greenblatt estimates that the accuracy rate will reach 70% if 2 million programs are created per problem.
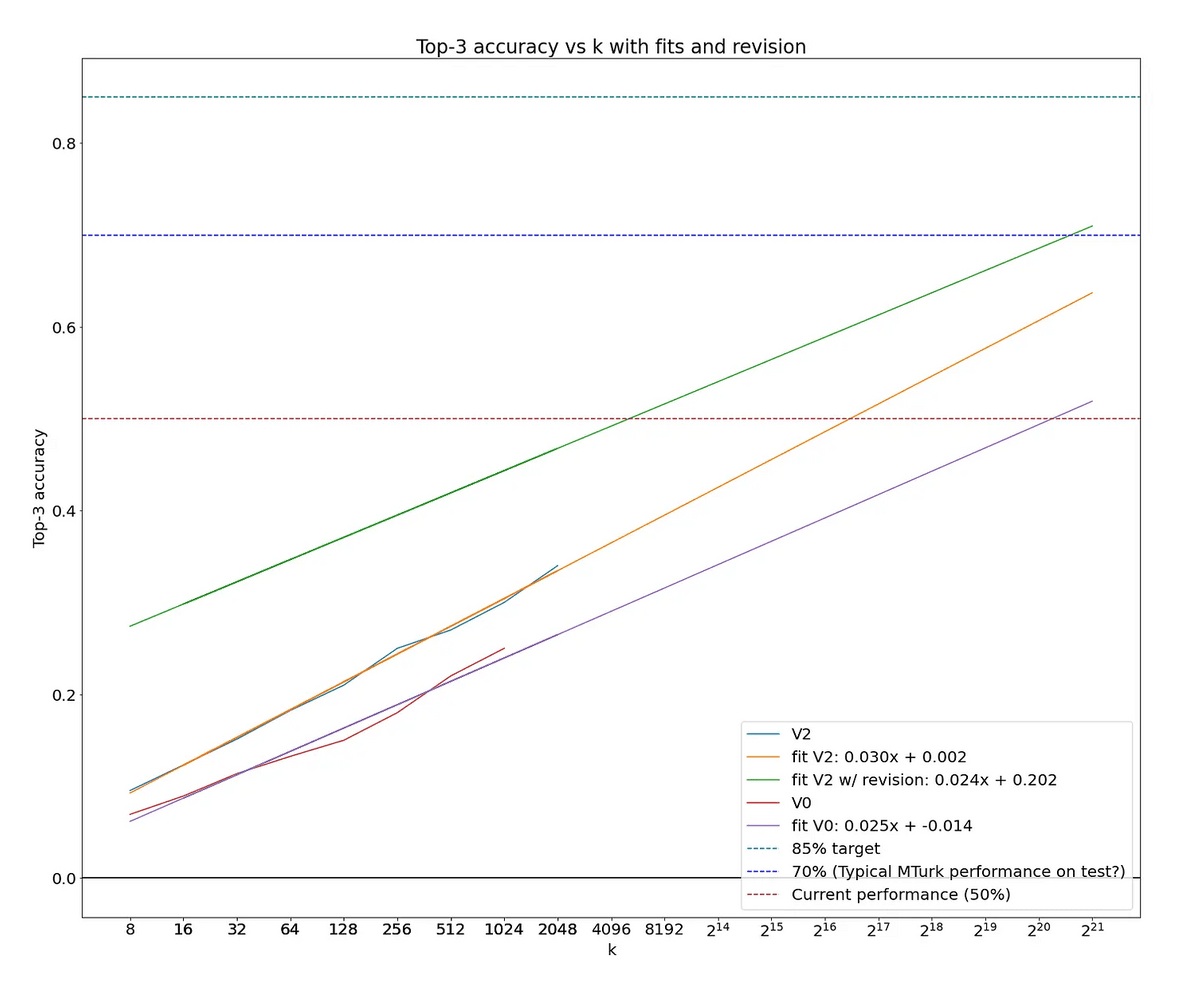
The ARC Prize is running until November 10, 2024, and offers a prize of up to $500,000 (approximately 78 million yen) to anyone who develops an open model AI that scores 85% or more on ARC-AGI. However, Greenblatt's current work is not eligible for the ARC Prize because he is using the closed GPT-4o and consumes excessive computing resources during inference.
Related Posts: