Meta updates the license of its high-performance video processing model 'DINOv2' to enable commercial use, and at the same time releases the dataset 'FACET' for evaluating the 'fairness' of the model

On August 31, 2023, Meta announced that it would change the license for the video processing model 'DINOv2' from
Announcing the commercial relicensing and expansion of DINOv2, plus the introduction of FACET
https://ai.meta.com/blog/dinov2-facet-computer-vision-fairness-evaluation/
DINOv2 is a model trained by self-supervised learning, and is characterized by the ability to perform various video-related tasks such as ``semantic image segmentation'' that separates each object from an image and ``monocular depth estimation'' that estimates depth without fine tuning. . As you can see from the movie below, it has the ability to cleanly separate segmentation for each part such as 'head', 'body' and 'legs' from the image of the dog running.
Segmentation ability of DINOv2 - YouTube
Other detailed information about DINOv2 is explained in the article below.
Meta announces video processing model 'DINOv2', possibility of creating immersive VR environment with AI in the future - GIGAZINE

When DINOv2 was announced in April 2023, it was provided under the CC BY-NC 4.0 license and could not be used commercially. It is now available for free use for both commercial and non-commercial purposes. At the same time, the code for ' semantic image segmentation ' and ' monocular depth estimation ' using DINOv2 was also released.
In addition, to ensure AI is fair and impartial, Meta has developed a new comprehensive benchmark to evaluate the fairness of computer vision models in classification, detection, segmentation, and image retrieval tasks, using the ' FACET ' data released the set.
FACET consists of 32,000 images, including 50,000 people, labeled by human annotators for age, gender, skin color, hairstyle, occupation, etc.

By using FACET, it is possible to test models such as `` how much the rate of recognition as a skateboarder differs between men and women '' and `` how much the recognition rate differs depending on the color of the skin ''.
The results of testing with three models: 'DINOv2', '
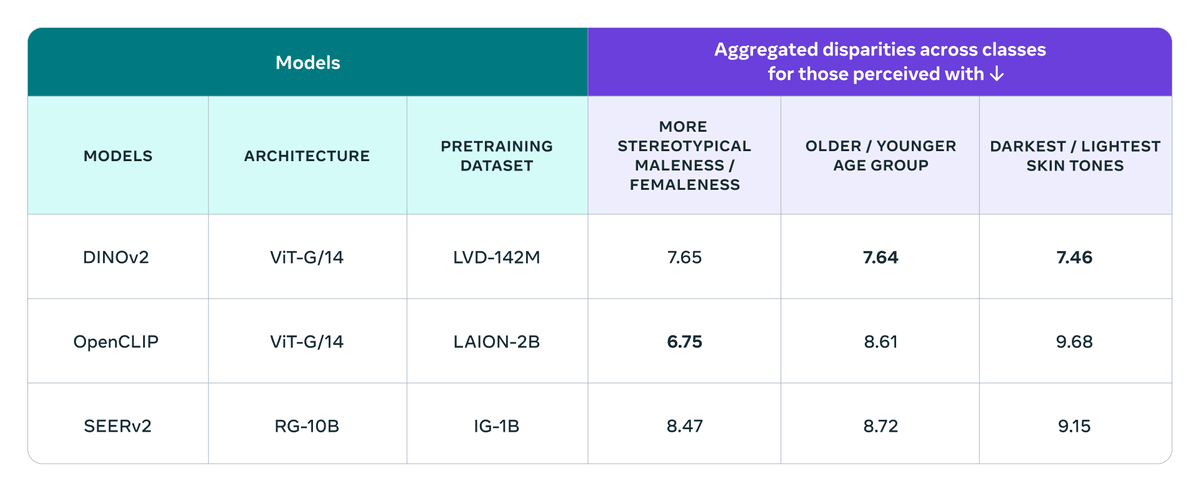
Please note that the FACET dataset is distributed only for research purposes, and you need to apply to Meta for permission to download it.
Related Posts:







