Google explains ``mechanism of giving vision to large-scale language model'', demo created in cooperation with Mercari is also released
At the same time as Google released a demo of ``Large Scale Visual Model (LVM)'' that gave ``visibility'' to Large Language Model (LLM), it posted a commentary article on how LVM works.
Multimodal generative AI search | Google Cloud Blog
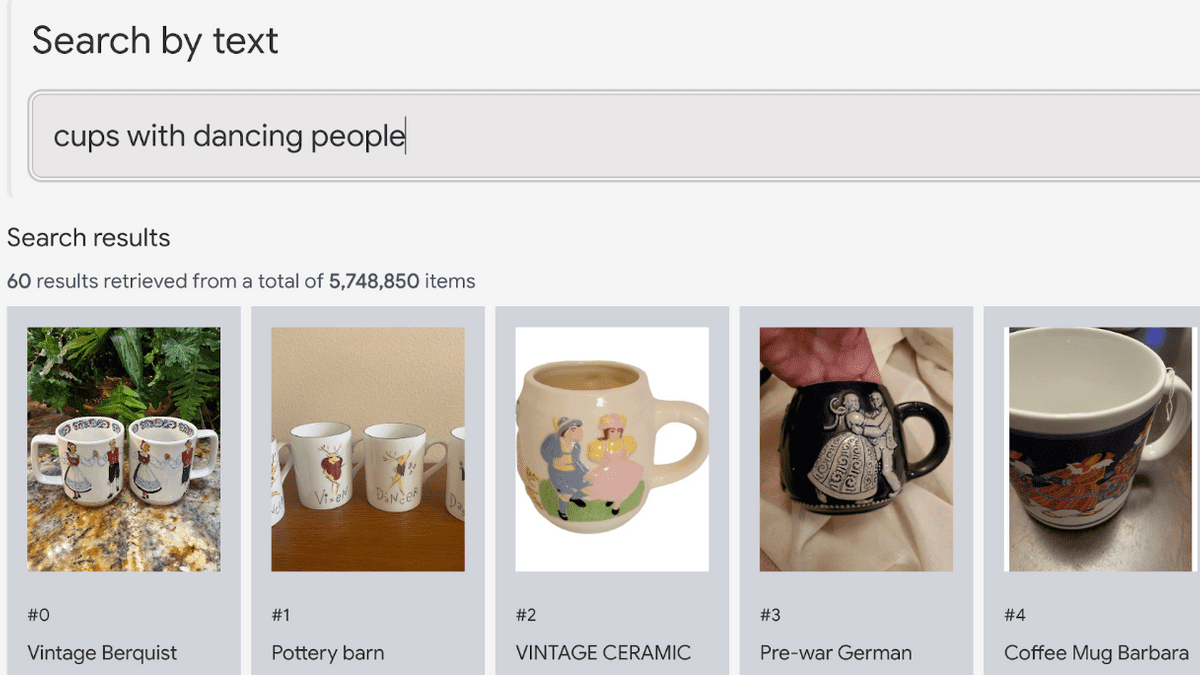
A demo of LVM is available at ' https://ai-demos.dev/ '. Since multiple demos are published collectively on this site, click 'MERCARI TEXT-TO-IMAGE' to display the LVM demo. As the name suggests, this demo is created using Mercari's product data.
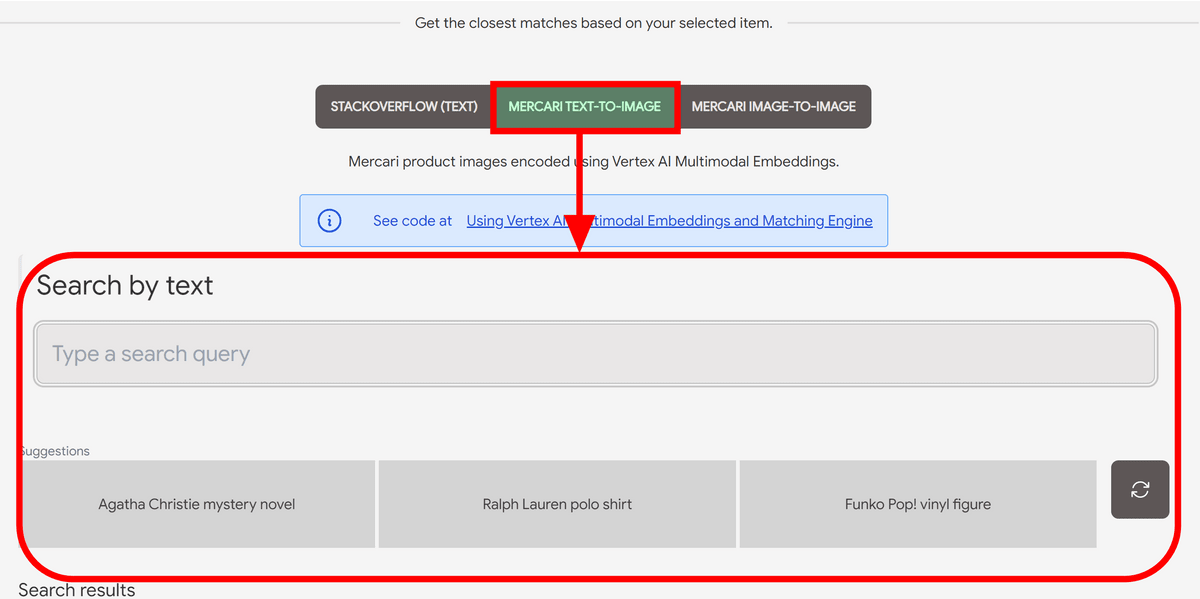
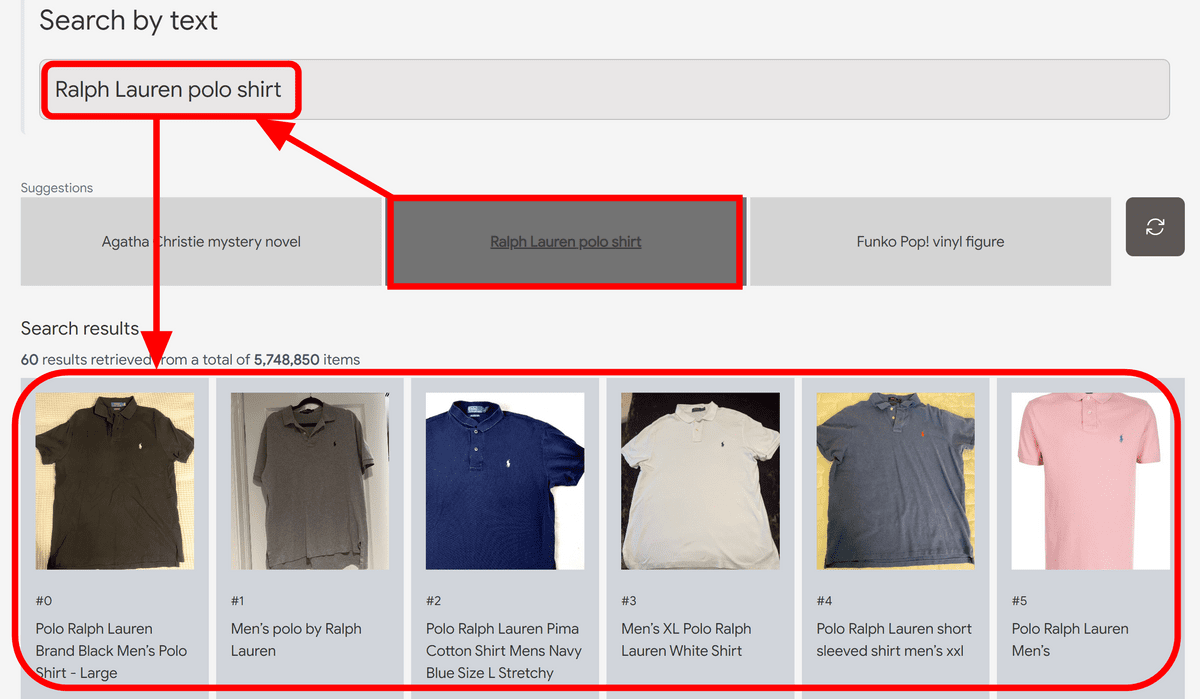
You can enter the text yourself, but first click on the 'Ralph Lauren polo shirt' suggested by the demo. Characters were automatically entered in the search field, and the search results appeared immediately. Up to this point, there is no particular difference from a normal search, but according to Google's post, this search does not use 'title', 'description', 'tags', etc., and is only based on AI analyzing the image. It is said that there is.
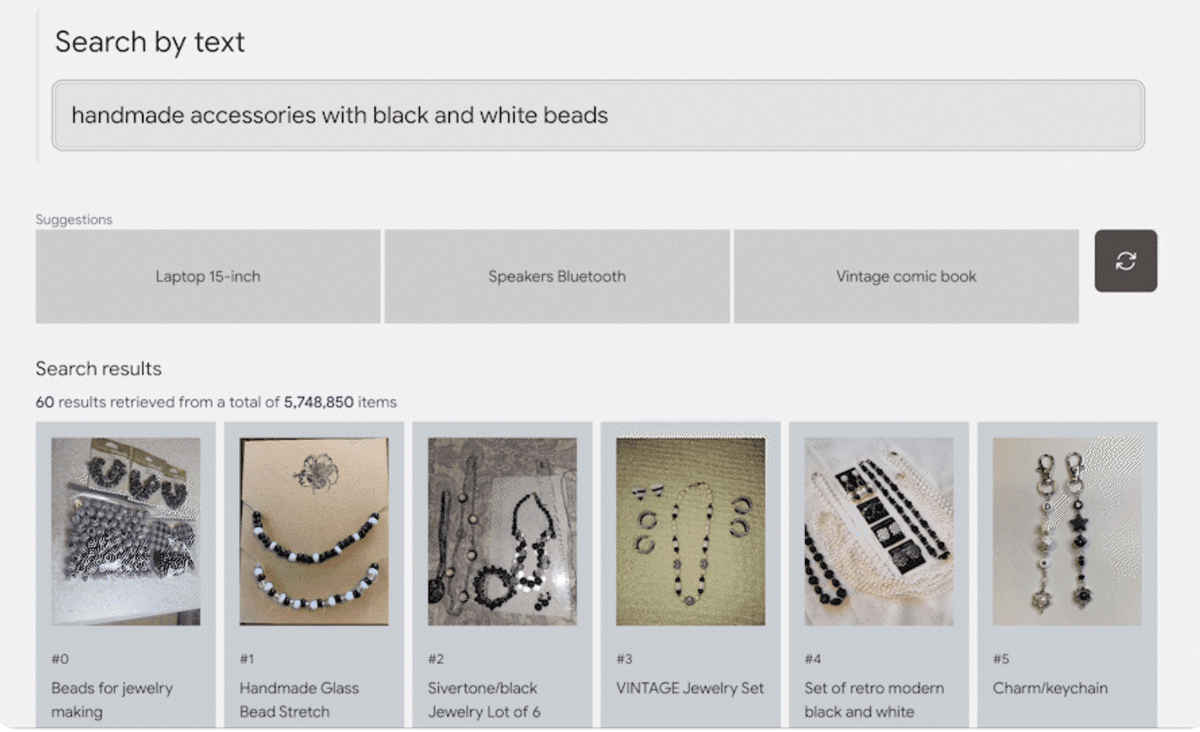
Therefore, even the low-searchability sentence “handmade accessories with black and white beads” can be found.
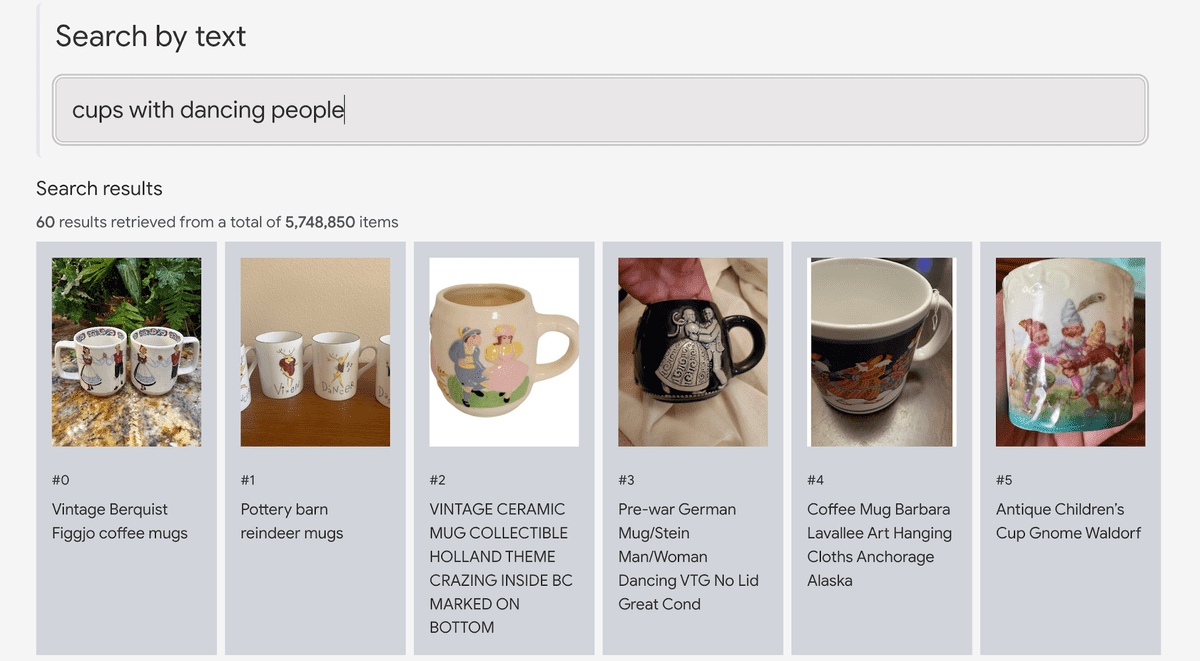
It is also possible to analyze the picture of the product, such as 'a cup with a picture of a dancing person'.
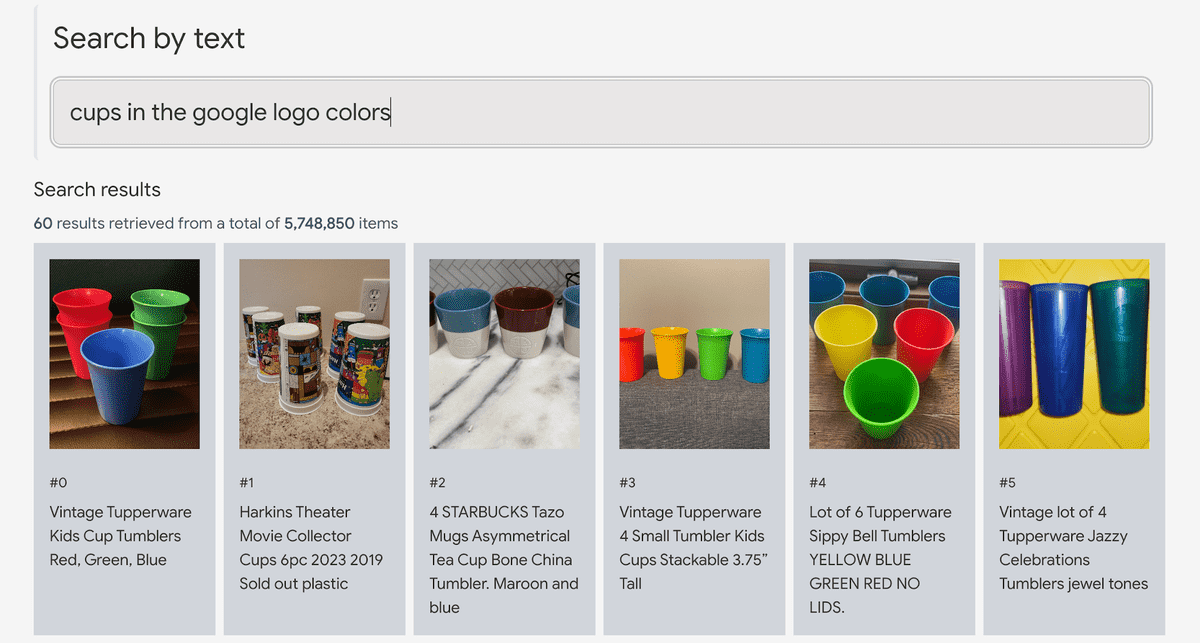
If it is 'Google logo color cup', a cup composed of blue, red, yellow and green colors will hit. As expected, I do not think that anyone will register the sentence 'Google logo color', so this is the ability of LVM.
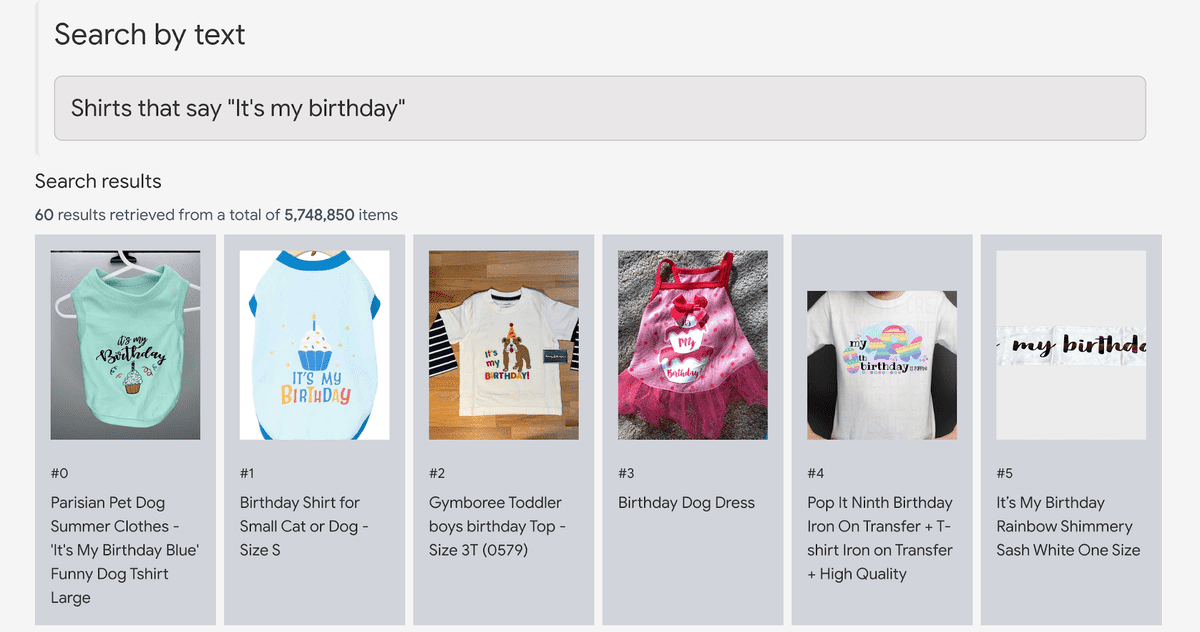
It seems to be able to recognize letters, so when you search for 'a shirt that says 'It's my birthday'', you will find a shirt that says so.
Deep learning models can create embedding spaces, which are 'maps of meaning' for text, images, sounds, etc. For example, in the case of images, each image is decomposed into components such as 'human', 'food', and 'toy' as shown in the figure below, and placed in the embedding space made up of these components.
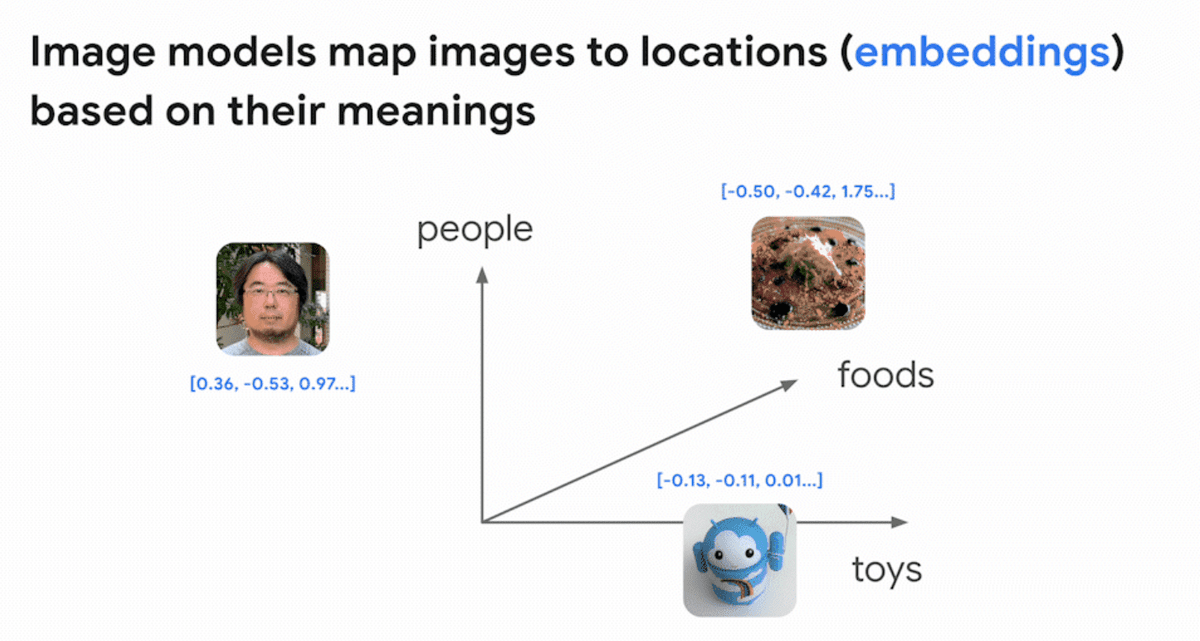
Images with similar components are placed close to each other in the embedding space. By using this mechanism, it is possible to build a system for searching images from images.
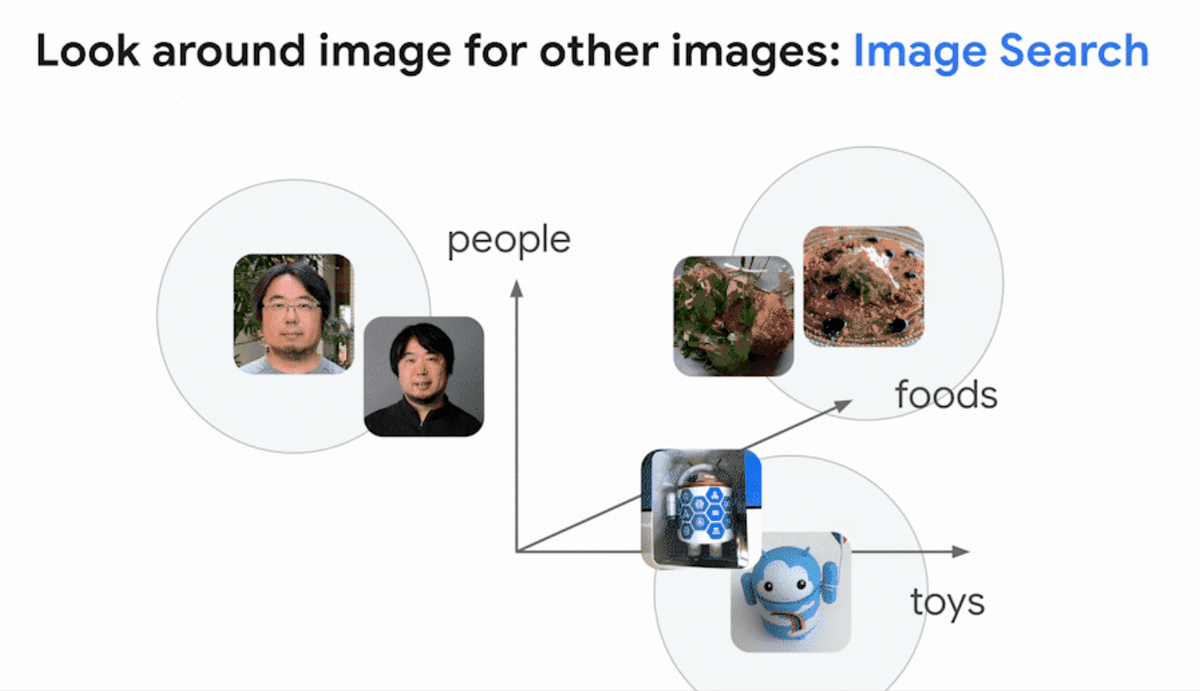
Deep learning models can also be trained using text-image pairs. Google said that it trained using three models: 'a model that places images in embedded space', 'a model that places text in embedded space', and 'a model that learns the relationship between the two spaces'. It has been described as 'something like giving vision to a large language model'. 
Thus, we were able to place images and text in a shared embedding space.
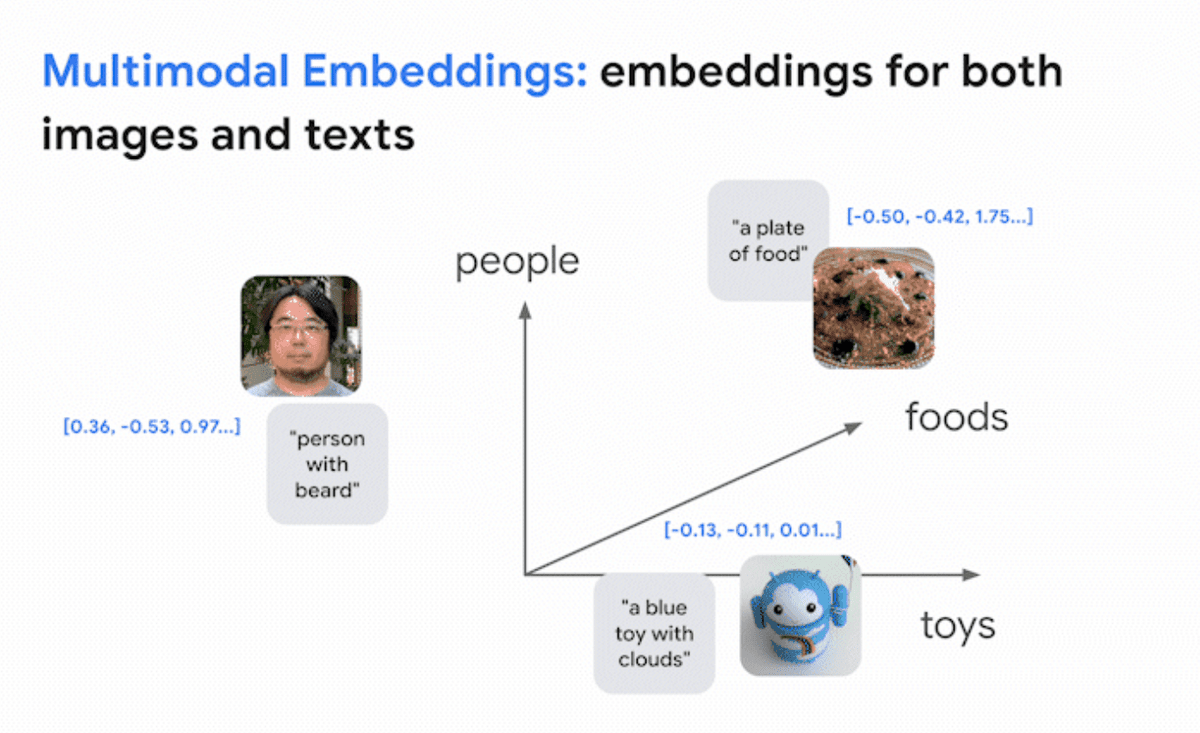
By using this space, it is possible to retrieve images from text, and vice versa. The same idea is used in Google search.
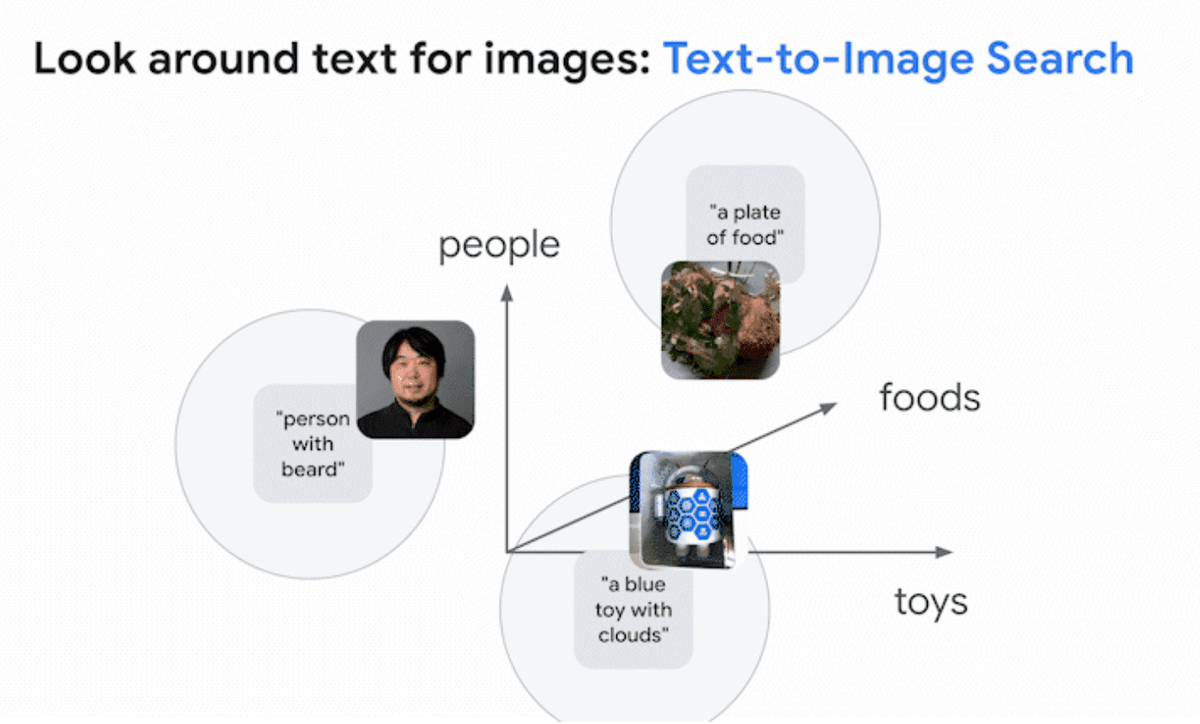
Additionally, Google worked with

In Google's commentary blog, as an application example of LVM, when listing an item at an Internet auction, simply by uploading an image of the product, the title and description are automatically entered, and 'a burning machine' and 'a person trying to open the door' are displayed. An example of efficiently managing a large number of security cameras using text such as 'waterlogging' is described. In addition, it is also possible to efficiently organize data when performing machine learning such as automatic driving.

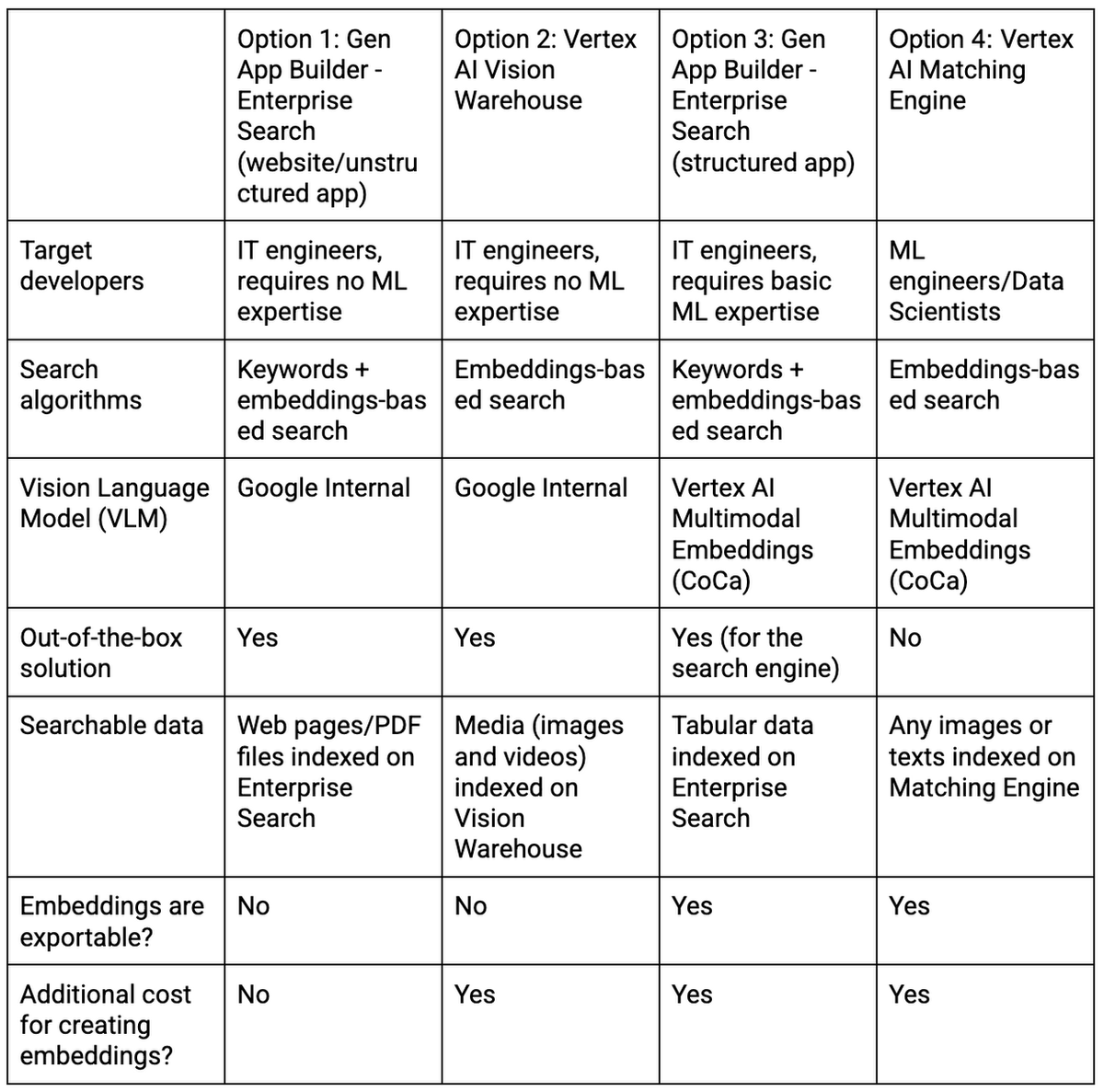
Google's service was also introduced for those who are considering using multimodal search that can search text and images at the same time. It is good to use '
Related Posts:



in AI, Software, Web Service, Web Application, Posted by log1d_ts