Stability AI releases open source large-scale language model 'FreeWilly' with performance equivalent to ChatGPT

Meet FreeWilly, Our Large And Mighty Instruction Fine-Tuned Models — Stability AI
https://stability.ai/blog/freewilly-large-instruction-fine-tuned-models

stabilityai/FreeWilly1-Delta-SafeTensor Hugging Face
stabilityai/FreeWilly2 · Hugging Face
https://huggingface.co/stabilityai/FreeWilly2
New FreeWilly LLM from Stability AI Tops Leaderboard for Open Access Language Models - WinBuzzer
https://winbuzzer.com/2023/07/22/new-freewilly-llm-from-stability-ai-tops-leaderboard-for-open-access-language-models-xcxwbn/
On July 21, 2023 local time, Stability AI announced the large-scale language model FreeWilly1 and its successor FreeWilly2 in collaboration with AI development company CarperAI .
FreeWilly1 is based on Meta's large-scale language model ' LLaMA-65B ' and fine-tuned on synthetically generated datasets using Supervised Fine-Tuning (SFT). On the other hand, FreeWilly2 is a large-scale language model developed using ' LLaMA 270B '.
Meta releases a commercially available large-scale language model 'Llama 2' for free, and cooperates with Microsoft and Qualcomm to optimize for smartphones and PCs-GIGAZINE

FreeWilly training uses the 'Orca Method' described in Microsoft's paper ' Orca: Progressive Learning from Complex Explanation Traces of GPT-4 '. Rather than mimic the output style of a large language model, the Orca Method teaches a small model the step-by-step reasoning process of a large language model.
According to Stability AI, about 600,000 datasets were created with the prompts and language models chosen by the development team, but this amount was only about 10% of the dataset used by Orca. This significantly reduced the amount of training required.
FreeWilly2's performance is said to match that of GPT-3.5 for some tasks. The results of a benchmark test independently conducted by Stability AI researchers are as follows. In `` HellaSwag '', a natural language inference task that requires common sense, FreeWilly2 is 86.4%, and ChatGPT with GPT-3.5 is 85.5%. In addition to exceeding the performance of `` MMLU '', which investigates multitasking performance, FreeWilly 2 leaves a performance of 68.8%, which is close to 70.0% of GPT-3.5.
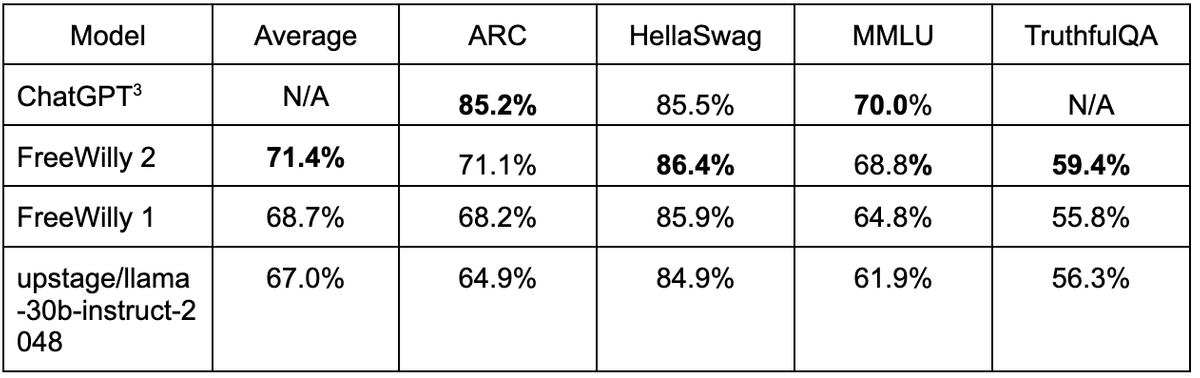
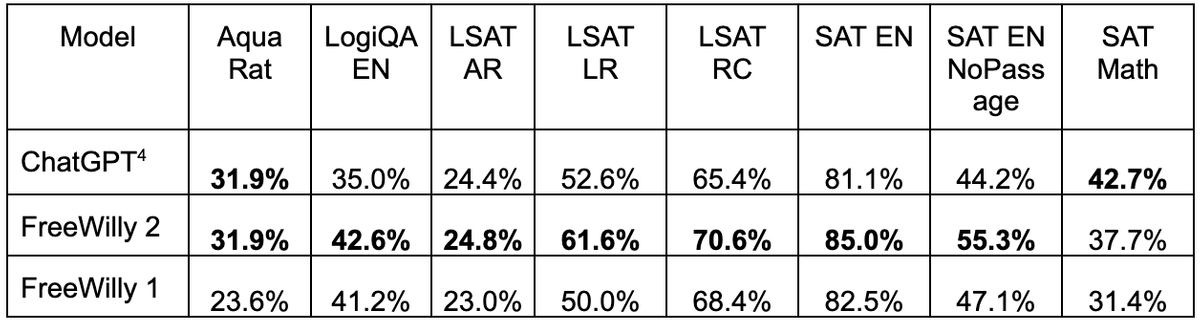
In addition, the results of comparing the performance with the large-scale language model benchmark software ``
“FreeWilly1 and FreeWilly2 set new standards in the field of open-access large-scale language models. It greatly advances research, enhances natural language understanding, and makes it possible to perform complex tasks.' We hope to inspire you.'
Stability AI emphasizes FreeWilly's focus on responsible release, and reports that these models have been tested for potential harm by an in-house dedicated team. In addition, Stability AI actively accepts external feedback to further strengthen its safety measures.
Related Posts:






in Software, Posted by darkhorse_log