DeepMind's AI ``DeepNash'' masters military shogi ``Stratego'' that hides the identity of the frame

by
Unlike chess and Go, where players can grasp the identity of the pieces from the beginning, AI has mastered the board game `` Stratego '' that fights while hiding the identity of each other's pieces. Learning by AI was very difficult because the information was hidden, but ' DeepNash ' developed by DeepMind cleared it and reigned in the top 3 online games of all time.
Mastering the game of Stratego with model-free multiagent reinforcement learning | Science
https://www.science.org/doi/10.1126/science.add4679
Stratego is a one-on-one turn-based board game. Like shogi and chess, it is a game in which pieces with different roles are placed on the board and moved, but the main feature is that ``the identity of the opponent's piece is not known until the pieces touch each other.'' Since the initial placement can be decided as you like, the strategy including psychological factors such as bluffing is important.

by
Generally speaking, the maximum number of game records for chess is 10 to the 120th power or more, and the maximum number of game records for shogi is 10 to the 220th power or more. It will be. In ``Complete Information Games'' such as chess, shogi, and Go, where all piece information is open to the public, a method called `` game tree search'' is used, which considers and analyzes the patterns of finger moves. It is difficult to use this technique in the 'imperfect information game' in which important information is hidden.
Therefore, DeepNash has adopted a new approach based on game theory and model-free deep reinforcement learning. Newly learned DeepNash adopts an algorithmic idea called 'Regularized Nash Dynamics (R-NaD)', and its play style is 'If each other always makes the most rational choice, each other will make a strategy. It is said that it will converge to the Nash equilibrium that it will be in a non-negotiable state. It seems that it is finished in a style that is very difficult for opponents to capture.
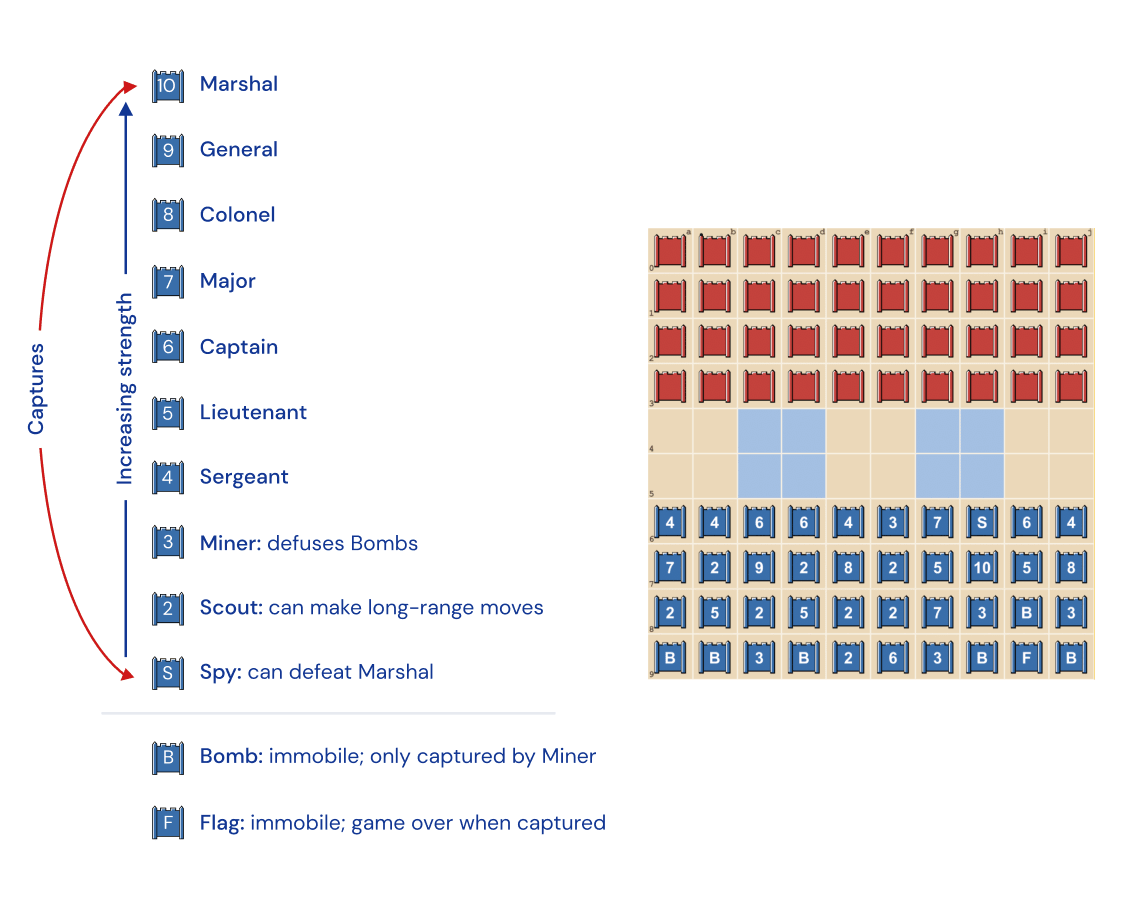
An example of a Stratego board looks like this. Each frame is assigned a symbol of S (1), 2 to 10, B, F, respectively Spy (S), Scout (2), Marshal (10), Bomb (B), Flag (F), etc. is named. 10 is strong against 9, 2 is strong against S, etc. Basically, the larger number can take the smaller piece, but the weakest S can win only against the strongest 10 and take 10 . Except for 2, you can move up, down, left and right by 1 square. B and F are immovable, only minor (3) can handle B. It is a rule that you win if you take all the opponent's moveable frames or take the opponent's F.
It is a game in which bluffing, meticulous information gathering, and bargaining with the opponent are important due to the rule that the identity of the opponent's piece is revealed only when it touches the opponent's piece. However, the basic idea of the Nash equilibrium where DeepNash converges is to ``do not change your strategy''. Don't let your opponent's strategy fool you.
In addition, DeepNash showed surprising behavior in the initial placement and movement of frames. In the initial placement, DeepNash tried all possible placements so that the opponent could not see through the pattern, and in moving pieces, he randomly repeated seemingly the same movements so as not to reveal his hand to the opponent. is.
DeepNash also made good use of bluffing, for example by chasing the opponent's 8 with a 2, he also made a strategy that made the opponent think 'this is a 10'. At this time, the opponent was waiting for S to get 10, but he
In matches involving World Championship winners, DeepNash's win rate was over 97%, often 100%. In addition, DeepNash recorded a winning rate of 84% against top human expert players on the world's largest online strategy site ' Gravon ', and it seems that DeepNash has won the top 3 positions of all time.
DeepNash was developed for Stratego, but the R-NaD method developed by DeepMind's Julian Perorat et al. can be directly applied to other imperfect information games such as Stratego. thing. Perorat et al., ``In addition to games, AI can bring out new possibilities in areas where the intentions of others are mixed and you don't know what's going on, such as scenes in large-scale traffic management. I look forward to it,' he said.
Paper co-author and former Stratego World Champion Vincent Bohr said, 'DeepNash's level of play surprised me because I had never heard of an AI approaching the level of an experienced human player. However, when I actually played DeepNash, I was convinced that Gravon finished in the top 3. If I let him participate in the human world tournament, I'm sure he will do well. '' he said.
In addition, the gameplay video when DeepNash fought with humans can be viewed from the following. This is the video of the first game released by DeepMind.
Deep Nash Stratego game 1-YouTube
2nd round
Deep Nash Stratego game 2-YouTube
3rd round
Deep Nash Stratego game 3-YouTube
It's the 4th race.
Deep Nash Stratego game 4-YouTube
In addition, the board version 'Stratego' is sold at Amazon.co.jp for 3954 yen including tax.
Amazon | Jumbo Stratego Stratego Original Strategy Battle Board Game 19816 Genuine | Board Game | Toy
Related Posts: