One of the great achievements of emoji is 'unifying the character code'

In order to handle characters on a computer that processes numbers, a byte representation called a
Emojis paved the way for UTF-8 everywhere
https://developers.ibexa.co/blog/emojis-paved-the-way-for-utf-8-everywhere
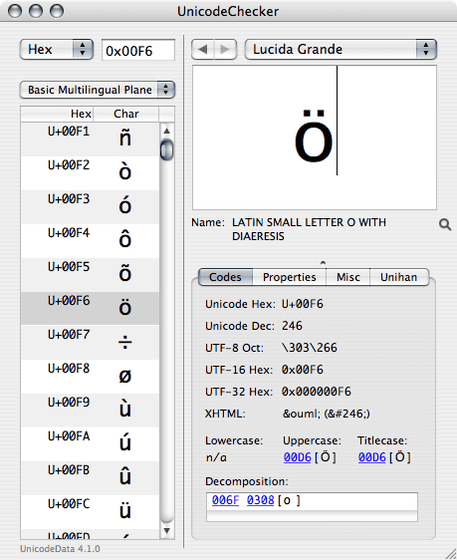
Finnish, Tarvainen's mother tongue, may have symbols in the alphabet, such as umlauts such as ' Ä ' and rings such as ' Å '. Since these symbols do not appear in American English, they used to have to write 'Ä' and 'Å' as 'A'.
With the advent of Unicode in 1991, it became possible to use various characters on the computer v, and it became possible to write umlauts and rings.
by
However, before the advent of Unicode, the character codes defined for each country and language were different, and it was often not possible to display special characters depending on the environment. This problem became more pronounced with the emergence of multiple environments accessing a single text over the Internet.
For example, in the early 2000s Tarvainen used a Windows NT workstation to type in HTML in a text editor, while his colleague Art Director uses a Power Macintosh G3 and Mac OS 9 in a Macintosh Latin environment, Travainen. Words using special characters such as 'lärvilautanen' and 'Rytsölä' that I typed in were garbled and could not be displayed normally.
In addition, Travainen, who was involved in the development project of a mobile phone maker in Scandinavia such as Nokia, said that the problem of character notation due to environmental differences became so large that it could not be ignored in handling Hebrew and Hungarian. I am. For Latin alphabets, it could be solved by using the meta tag 'charset = iso-8859-1 ', but for Arabic, Japanese, and Chinese, it was no longer possible.

by
In 1996, UTF-8, a Unicode encoding method compatible with ASCII, which was mainly used in English-speaking countries, was established. However, there were many environments that did not support Unicode by default. Although special characters such as Chinese characters are being added to Unicode little by little, new characters are not added to the English alphabet, so there are many software and environments in English-speaking countries that do not bother to support Unicode / UTF-8. It's because of it.
However, Tarvainen points out that the popularity of pictograms has contributed to the rapid progress in UTF-8 and UTF-16 support in English-speaking countries. With the spread of smartphones, English-speaking people have used Japanese-born pictograms in the same way as the alphabet, and the word 'Emoji' has become widespread.

by Forsaken Fotos
Emoji has become an essential tool for building communication with others in the age of social media. Google actively promoted the adoption of pictograms in Unicode, and adopted it as Unicode 6.0 in 2010. Software support for Unicode, which supports many pictograms, and its encoding formats, UTF-8 and UTF-16, has advanced.
'Thank you very much for using the emoji. You guys saved my ???? (peach ≒ pinch),' said Tarvainen.
Related Posts:


in Note, Posted by log1i_yk