DeepMind under Google announces AI 'MuZero' that learns how to win without being taught the rules of the game

Artificial intelligence company ' DeepMind ' has announced a new 'AI that allows you to learn how to win Go, Shogi, Chess, and
Mastering Atari, Go, chess and shogi by planning with a learned model | Nature
https://www.nature.com/articles/s41586-020-03051-4
MuZero: Mastering Go, chess, shogi and Atari without rules | DeepMind
https://deepmind.com/blog/article/muzero-mastering-go-chess-shogi-and-atari-without-rules
DeepMind MuZero AI Learns The Rules As Its Plays To Master Atari Games, Chess, And More | HotHardware
https://hothardware.com/news/muzero-deepmind-ai
AlphaGo, an artificial intelligence developed by DeepMind, defeated the world's strongest Go player, and its strength was such that Lee Sedol, who was defeated in 2019, announced his retirement as 'I can not beat AI'.
World Champion defeated by Go AI 'AlphaGo' retires as a Go player saying 'I can't beat AI' --GIGAZINE

AlphaGo has shown overwhelming strength in the world of Go, but it has been said that it cannot deal with 'problems with high uncertainty' and is not suitable for dealing with real problems with unclear rules.
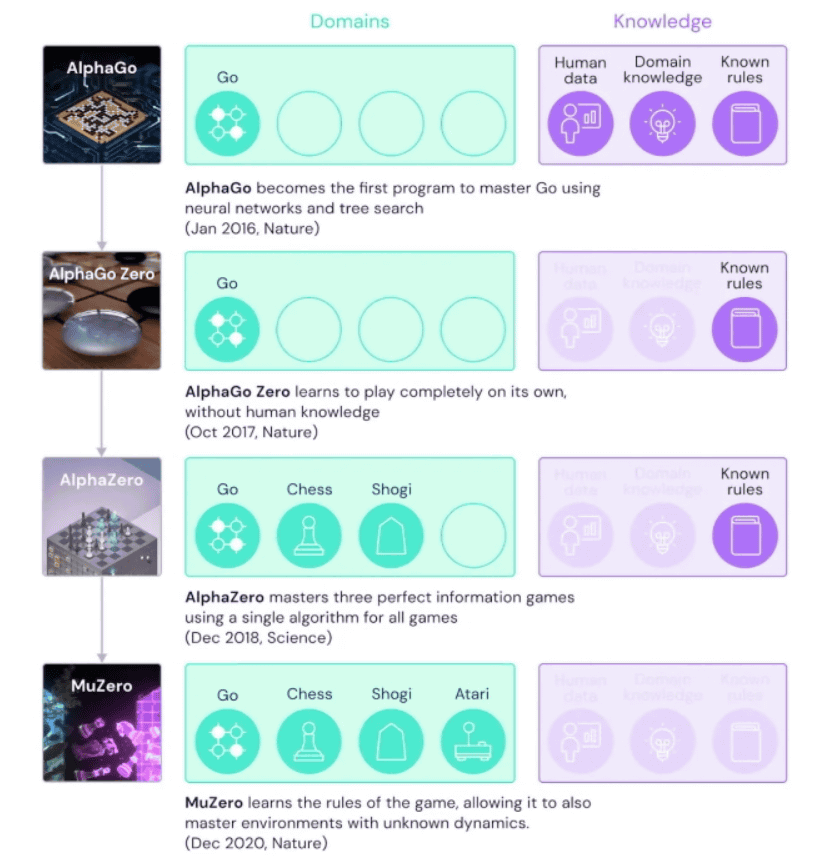
DeepMind's newly announced 'Mu Zero' is characterized by taking a new approach to solve these AlphaGo challenges. Below is a diagram showing the differences between AlphaGo and its newer versions, AlphaGo Zero , AlphaZero , and MuZero. The green part on the left shows the knowledge to be learned in advance for the game that can be played. While AlphaGo needs to play only 'Go' and be taught 'human data', 'knowledge of Go' and 'rules of Go' in advance, MuZero needs to learn about Go, chess, shogi and Atari without prior learning. It is possible to derive the optimum solution by self-learning.
The research team explains that Atari was used in the development of MuZero 'to provide a lot of tasks that players need to develop sophisticated strategies and to provide a simple progress indicator called a game score.' MuZero's goal is not only to be trained to solve specific problems, but to train AI to 'think' about problems.
Specifically, MuZero models the following three elements without using a trained model:
・ Value: How good is your current position?
· Policy: Which action is best
・ Reward: How good the last action is
MuZero uses these three elements to learn and understand 'what happens when a specific action is taken or planned' with a neural network. DeepMind has developed artificial intelligence to play Atari before MuZero , but MuZero has higher performance than any of them, and it is said that it is comparable to AlphaZero's performance in terms of Go, chess and shogi.
'After all, knowing'how to keep an umbrella dry'is more important than modeling the rainy water drop pattern in the air,' the research team said. It is expected to be a step toward developing AI with better problem-solving skills.
Related Posts:








in Science, Posted by darkhorse_log