'NeRF in the Wild' where you can create 3D images from still images and change the weather and shooting time

There are some people who have thought, 'If I can change the angle of this subject a little more...' when processing an image. The technology newly developed by Google's research team is 'technology that creates 3D images from still images that clearly show the subject from various angles' that fulfills such hope. 'Neural Radiance Fields' (neural Radiance field /
NeRF in the Wild
https://nerf-w.github.io/
[2008.02268] NeRF in the Wild: Neural Radiance Fields for Unconstrained Photo Collections
https://arxiv.org/abs/2008.02268
You can see what the technology called 'NeRF in the Wild' is like in the following movie.
NeRF in the Wild: Neural Radiance Fields for Unconstrained Photo Collections-YouTube
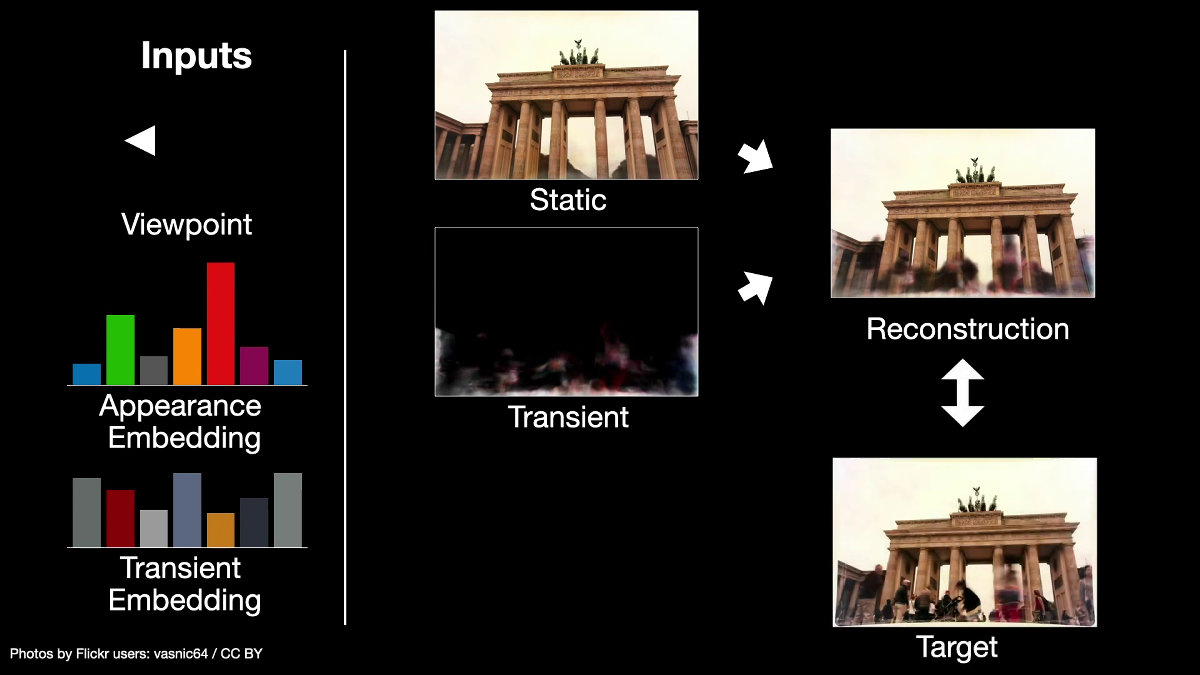
The technology developed by the research team is as follows. For example, suppose you combine photos taken of the Brandenburg Gate in Berlin from different angles and distances to create one image that you can see from different angles.

Usually, the photos found on the image-posting SNS, such as '

In addition, not only photos taken with the subject alone, but also many photos with people in their surroundings are a major obstacle in compositing.

With the newly developed system, first, from the viewpoint of the shooting location (shooting location) and the two still images, enter the 'embedded appearance' that is the core of the scene.

Next, enter 'temporary embedding' that includes the part that changes in the scene.

Combine these two...

In addition, we train the model to remove 'errors' from the reconstructed image to bring it closer to the target image.
According to the research team, this model may have been deleted excessively during reconstruction due to the 'uncertainty factor' of a specific image, and it was necessary to adjust that point. thing. This characteristic was also used for training to identify and ignore 'temporary elements'.
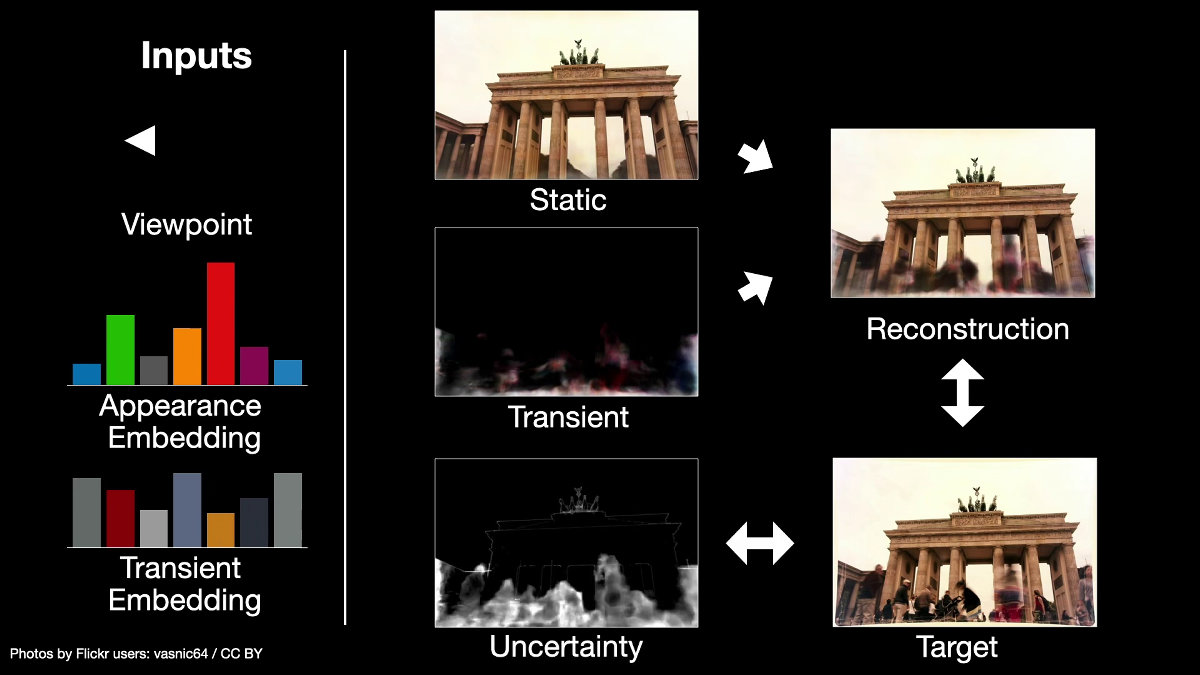
By carrying out such training, the 'image that allows you to see the subject from various viewpoints' is completed.

It is also possible to create images with the same viewpoint and different situations by changing the 'embedded appearance'.

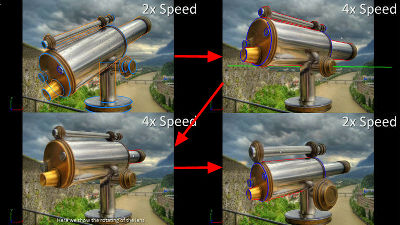
This is the completed image. It starts from the angle where you can see the Brandenburg Gate from the bottom right...

The angle you are seeing changes when it is slimy.

I wondered if I saw the top of the gate up from the left...

To the sight seen from the point where I drew a lot.

With the existing model, the shadow of the obstacle that was reflected in the input photograph was deeply reflected, but the new model has a much lighter shadow.




Like the original NeRF, the new model also extracts high quality depth maps.

In addition, it is also a point that the latest model can change the environment such as morning, daytime, night, cloudy, sunny by changing the appearance embedding.

The image output by the latest model is on the left, and the image output by the existing model is on the right. The latest model has better lighting, and the movement when changing the angle is smooth, resulting in high quality overall.

Related Posts: