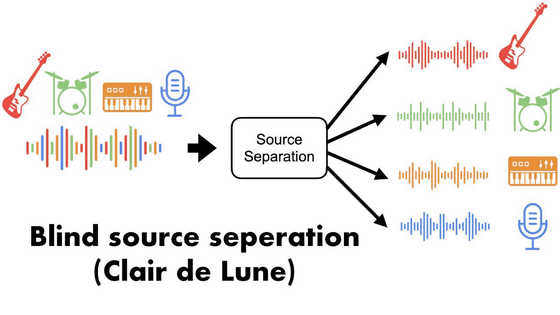
Technology to extract only vocals and musical instruments from songs using depth learning will be developed

A paper has been published that developed a new technology that can cleanly extract vocals and specific instruments from existing songs using a neural network based on "End-to-End learning".
[1810.12187] End-to-end music source separation: is it possible in the waveform domain?
https://arxiv.org/abs/1810.12187
A convolution neural network called " DeepConvSep " existed as a neural network that can separate and extract a specific part such as a vocal, a guitar, a drum from a song. This is a technique of extracting after analyzing "magnitude spectrogram" showing how strongly the sound is depending on the frequency of the song. However, in DeepConvSep, the accuracy of the extracted part was low, it was not sufficiently separated, and there was a lot of noise mixed up.
Therefore, the research team led by Xavier Serra uses the convolution neural network "Wavenet" which removes noise by " End-to-End learning " and "Wave-U-Net" which directly edits the audio waveform based on Wavenet We have newly developed a technology to separate and extract specific parts from songs. End-to-end learning is a method of passing only inputs and outputs to the network so that all processes performed during the learning are learned.
An example of actually using Wavenet and Wave-U-Net is published on the following website.
End-to-end Music Source Separation - Audio samples
http://jordipons.me/apps/end-to-end-music-source-separation/
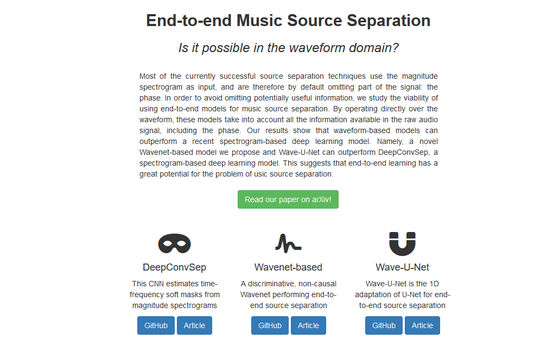
On this site, you can see an example of extracting vocals using Wavenet and Wave-U-Net, and an example of extraction of vocals, drums and bases by DeepConvSep · Wavenet by pushing the play button of the player embedded in the site can.

If you listen to vocals and compare them, compared to DeepConvSep there are still a lot of other part parts, whereas Wavenet is getting more noise, but the other part is removed. Also, in Wave-U-Net, noise is further reduced than Wavenet, so you can clearly see that part extraction is done more smoothly.
According to the research team, Wave-U-Net is too difficult to create silence at the part where there is no vocal, as Wave-U-Net is difficult to remove, It is said that less editing is possible.
Based on this result, the research team argues that deep learning based on End-to-End learning has great potential for part separation technology of music.
Related Posts:



in Software, Posted by log1i_yk