Deep Mind Develops 'PopArt' Technology for Filling Difference in Remuneration Generated in AI Multitasking Learning

Speaking of Google's affiliated artificial intelligence research company · DeepMind, he developed " AlphaGo " of Go AI who defeated China's strongest shogi player, and " AQ 's" DQN "who learned the game by himself and played more than humans. Such DeepMind has developed a technology " PopArt " which is useful when letting a single agent learn more than one thing, and reveals its effect.
Preserving Outputs Precisely while Adaptively Rescaling Targets | Deep Mind
https://deepmind.com/blog/preserving-outputs-precisely-while-adaptively-rescaling-targets/
"Multitasking learning" allows a single agent to learn how to solve many different tasks. This multitasking learning has been a long-term goal in artificial intelligence (AI) research. In recent years, an agent like " DQN " that can play games better than a person developed by Google, which appeared in recent years, this multitask learning algorithm is used to learn to play more than one game I will. As AI research becomes more complicated, establishing multiple specialized agents in AI research is mainstream. On the other hand, it is important that the algorithms used to make each agent learn can be able to build more than one task on a single general purpose agent, so it is important to become a multitask learning algorithm .
However, there is also a challenge in such multitask learning algorithms. One of them is that there are differences in the compensation measures that reinforcement learning agents use to judge success. For example, when letting DQN learn about game pongs , the agent receives one of "-1", "0", and "+1" for each learning step. However, when playing Pac-Man , it becomes possible to acquire hundreds or more points (rewards) for each learning step, and it is impossible to measure which task is important with the same reward scale That is why. Also, even if the scale of individual compensation is equal, various cases are considered, such as different frequency of remuneration. Since agents have the property of concentrating on tasks with large scores (rewards), if the reward scales and frequencies are different, there is a case that the performance improves only in a specific task and the performance declines in other tasks To do.
In order to solve these problems, regardless of the scale of the rewards gained in each game, we have developed a technology " PopArt " for standardizing the reward scale of each game so that the agent can judge the game with equal learning value Deep Mind has developed. According to DeepMind, applying PopArt to a state-of-the-art reinforcement learning agent succeeded in creating a single agent that can learn 57 different types of games at once.

Deep learning is to update the weight of the neural network so that the output approaches the target value. This is true even when a neural network is used for deep reinforcement learning. Therefore, PopArt makes it possible to standardize the score by estimating the average value and penetration rate from in-game score etc. of the learning object. Standardization of the score will enable more stable learning against changes in scale and shift.
In the past, AI researchers have tried to overcome the scaling fluctuation problem of rewards by using reward clipping in the reinforcement learning algorithm. This is a technique of standardizing reward by roughly classifying a big score as "+1" and a small score as "-1". The agent's learning is simple by using reward clipping, but there are cases where the agent does not perform a specific action, and the following movie is described in an easy-to-understand manner. It is easy to see that reward clipping, which is a conventional method, is not the optimal way in multitasking learning.
Unclipped rewards using PopArt - YouTube
Pacman's game purpose is to score as high a score as possible.

There are two ways to get points with Pac-Man, one is to eat the dots present in the stage. Another thing is to eat power escape and eat monsters.

10 points when eating dots

When you eat monsters you get 200-1600 points.

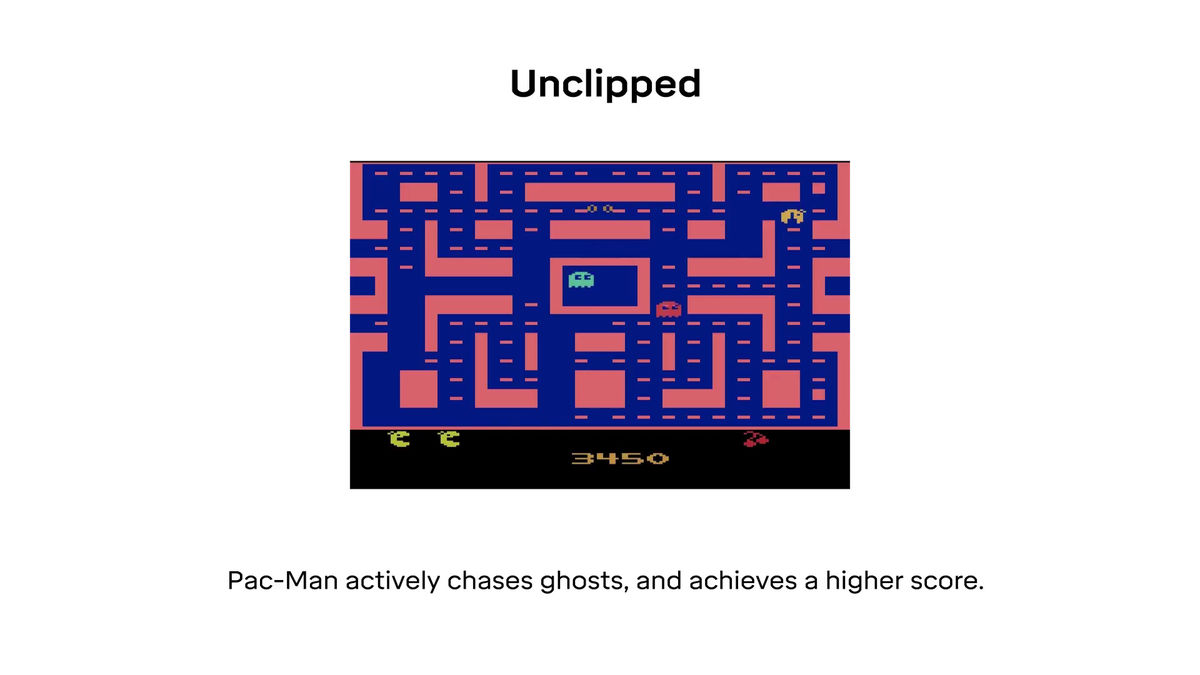
When using reward clipping, you will not be able to find a difference between the points you get with dots and the points you get by eating monsters ... ...

It seems that they will not try to eat monsters that can get higher points.

On the other hand, stopping reward clipping and applying PopArt makes it possible to recognize the importance of agents eating monsters by standardizing rewards ......

Even after chasing you will try to eat monsters and gain high points.
One of the most popular agents used in DeepMind is " IMPALA ". When I applied PopArt to IMPALA, I succeeded in greatly improving the performance of the agent and the result is obvious from the following graph.
The following graph shows the median score when each agent plays 57 kinds of games. The vertical axis shows the score, the horizontal axis shows the learning time, the green line shows the score of IMPALA applying the PopArt, the blue line shows the IMPALA score when not using the reward clipping, the blue dotted line shows the IMPALA It is a score.

DeepMind wrote, "This is the first time we have recorded high performance so far with a single agent in this type of multitasking environment", and if you want agents to learn about various objectives with various rewards It is said that PopArt will demonstrate great power.
Related Posts: