Robot arm 'Dactyl' showing a movement that is too dexterous like a human hand

OpenAI is developing a robot arm " Dactyl " that can handle objects with unprecedented level of dexterity. Dactyl uses the same general-purpose reinforcement learning algorithm and code that is used for the gaming AI " OpenAI Five " which can also win the human team with a 5 to 5 battle of Dota 2, You can learn how to handle it, slide objects on the palm of your hands and rotate with your fingers, you will be able to perform dexterous actions.
Learning Dexterity
https://blog.openai.com/learning-dexterity/
Dactyl is a system that manipulates objects placed on the palm of your hand using " Shadow Robot " robot arm "Dexterous Hand". Putting on the palm of the hand is a cube with letters written on each side. In the program, if you order "move the cube so that you can see this face", you roll the cube on the palm of your hand to the dexterity so that you can see the specified face. In addition, three RGB cameras are used to move the object, which seems to recognize the coordinates of the fingertip with the image taken.

You can check movement of the fingertip too deft by Dactyl by clicking on the image below.

Although it was ten years ago that a robot arm having the same shape as a human being was developed, the use of this robot arm for "effectively manipulating objects" is a long-standing task for the robot control field It was. Boston · Dynamics is developing a humanoid robot Atlas who walks in dexterity but traditionally the robot is said to be slower in progress than elaborate operations like fine movements of a finger than motion like walking It was the present condition.
Therefore, OpenAI, which has undertaken various efforts so that robots can independently learn how to solve various problems without inputting specific tasks to the program, will develop Dactyl. This Dactyl has independently developed a way to rotate a cube on the palm of your hand. Reinforcement learning has been used to develop Dactyl, which has been a great success in the game field, and we are learning robots "How to solve problems in the real world". Since the robot arm operates in the real world, friction, slip, etc. occurring between objects handled by the palm and arms can not be observed directly, so it seems that we had to infer.
The way the Dactyl actually moves can be seen in the following movie. I have cleared the test that rolls the cube with written letters so that the specified face faces the camera, 50 times in a row. It is easy to understand that we have moved the fingertips for insanely instruments and have dexterity to draw a line with the robot arm so far.
Learning Dexterity: Uncut - YouTube
How I learned Dactyl is to create a robot simulator using MuJoCo 's physical engine and reinforcement learning is done by moving the robot arm in the digital world before moving the robot arm in the real world It is.
It seems that we use technology called "Domain Randomization" which sets slightly different conditions every time when learning. This "slightly different condition" means not only that the color of the cube and the background are different, but also all factors such as the operation speed of the robot hand, the weight of the cube, and the friction coefficient occurring between the cube and the robot hand We randomized Dactyl and learned that. It seems that Dictyl's finger judgment has grown to be very stubborn because it will learn how to operate the robot hand under various conditions.

It is like this when showing the learning process with a simple diagram. First, "Rollout Workers" accumulated operating experience under various conditions, and then sent accumulated information to "Optimizer". "Optimizer" improves various parameters for controlling the robot based on this information. Then, the contents of the improved parameters are reflected in "Rollout Workers", and after that, by continuing this cycle, the accuracy of robot control will improve.

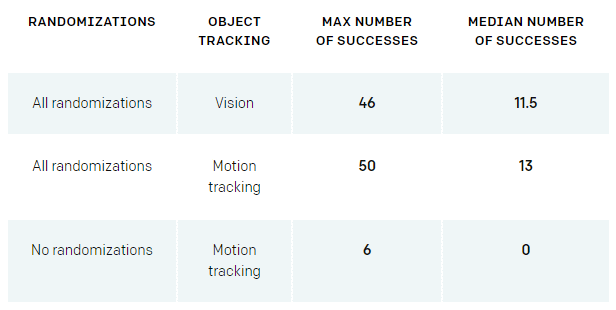
Whether or not randomization is used or not in the learning process, the number of successes of tasks that roll the cube in the real world and align the faces will change considerably. In the case of using motion tracking, the maximum number of times an arm that randomly learned every element and learned the task succeeded in successive tasks was 50, whereas the maximum number of times that other arm successfully made a task successively It is only six times. The median value of task success is also 13 times using randomization, whereas it is 0 times if randomization is not used.
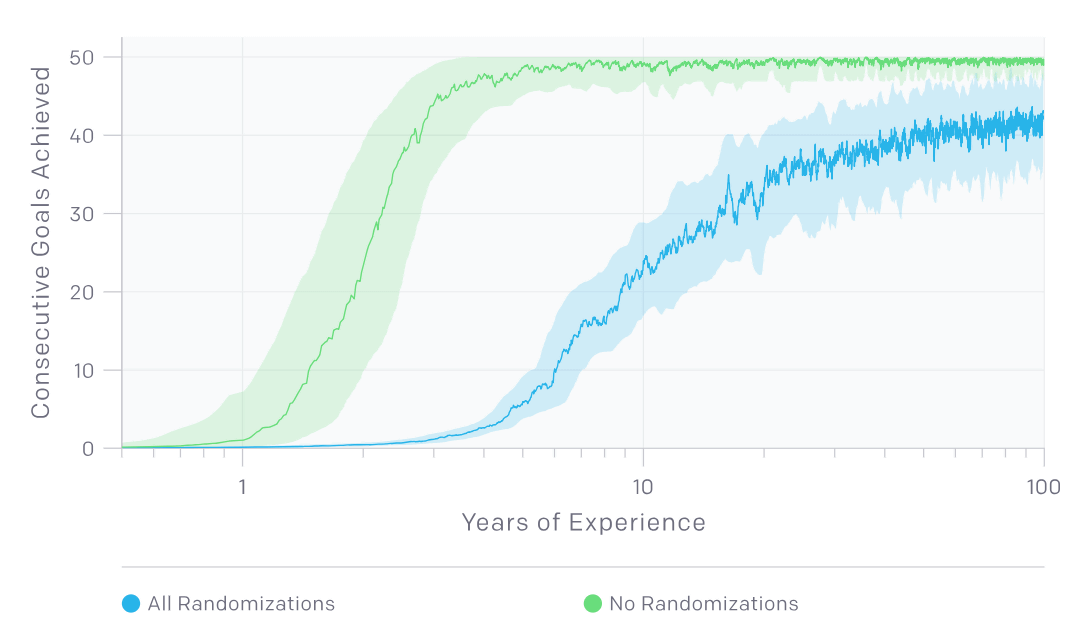
However, the time required for learning is overwhelmingly longer when all elements are randomized. In the graphs below, the vertical axis shows the number of times successive success of face matching, the horizontal axis shows learning time, when blue is used for learning at learning, green color is not used. When randomization is not used, the conditions are always the same, so it takes less than 3 years for the learning time to achieve face matching successively 40 times or more successively. However, when you always change the conditions randomly, it will be more than 100 years for the learning time to reach a level where constant performance can always be demonstrated.
When randomization is used, learning is performed under various conditions, so Dactyl can handle natural shapes other than cubes.

In addition, OpenAI's research team aims to let you learn more complicated tasks.
Related Posts: