Concepts to keep in mind when constructing a large-scale distributed system

Bytec_estromberg
Gergely Orosz of Uber's engineering manager has blogged the concepts and experiences that Uber needed in building a backend so that others can be helpful in constructing a distributed system.
Distributed architecture concepts I learned while building a large payments system
http://blog.pragmaticengineer.com/distributed-architecture-concepts-i-have-learned-while-building-payments-systems/

Various things need to be considered when constructing a large-scale and highly utilized distributed system. Orosz's blog contains "SLA," "Scaling," "Consistency," "Data Sustainability" "Message Persistence and Sustainability" "Equality" "Sharding and Quorum" "Actor Model" "Reactive Architecture "concepts are summarized briefly.
· SLA
What is SLAService Level AgreementIt is about what kind of quality service should be provided. "Availability" "Accuracy" "Capacity" "Latency" is used as an indicator.
Availability is the percentage of time the service is running, for example 99.99% means that the annual downtime was about 50 minutes.
Accuracy is how much proportion of the data in the system needs to be guaranteed to be accurate. For example, the payment system needs to have 100% accuracy.
Capacity is an indication of the load that the system can support and is usually represented by the number of how many requests the system per second per second.
Response time is an index of how much time it can return a response, and it is often used such as time to respond to 95% of requests and time to respond to 99%.

ByZ Jason
Because Orosz's job was to develop a new system to replace the existing payment system, we targeted "SLA better than the previous SLA" as a goal and considered the architecture etc.
·scaling
When business grows, load will also increase in many cases. At some point in time, existing systems will not be able to handle the increased load and you will need to expand the scale of the system. As a general scaling strategy, "horizontal scaling" and "vertical scaling" can be cited.
Horizontal scaling is to add a new machine (node) to the system and perform scaling. Horizontal scaling is commonly used for extending distributed systems, as it is easy to execute buttons when using the cloud, for example.
Vertical scaling is to "buy more powerful machines" to replace computers. In the case of distributed systems, vertical scaling is usually less expensive as it costs more than horizontal scaling,Several sites such as Stack Overflow are scaled verticallyIt is.
·Consistency(Consistency)
Distributed systems are often built with less-available machines (nodes). Even if the availability of each node is 99.9%, if you can provide the service even when one of them is dropped by combining multiple nodes, the availability of the whole system increases.
Consistency is important in these high availability systems. Consistency is that all nodes return the same response for the same request. If more than one node is added for high availability, it is not easy to maintain consistency, and it is necessary to deal with various situations such as when communication between nodes fails.
WikipediaAlthough you can check various models as you look at, etc., what is often used in distributed systems is(pdf) "strong consistency" "weak consistency""eventual consistency (result consistency model)"There are three. Hackernoon's article "eventual vs strong consistency"Describes the advantages and disadvantages of the result consistency model and the strong consistency model, respectively. In principle, lowering the level of consistency will make the system faster, but the possibility that it will not return the latest data increases.
· Data persistence(Data Durability)
Sustainability means "data once added correctly to the database is available in the future". This means that you can retrieve data from the database even if some nodes crash or communication breaks down.
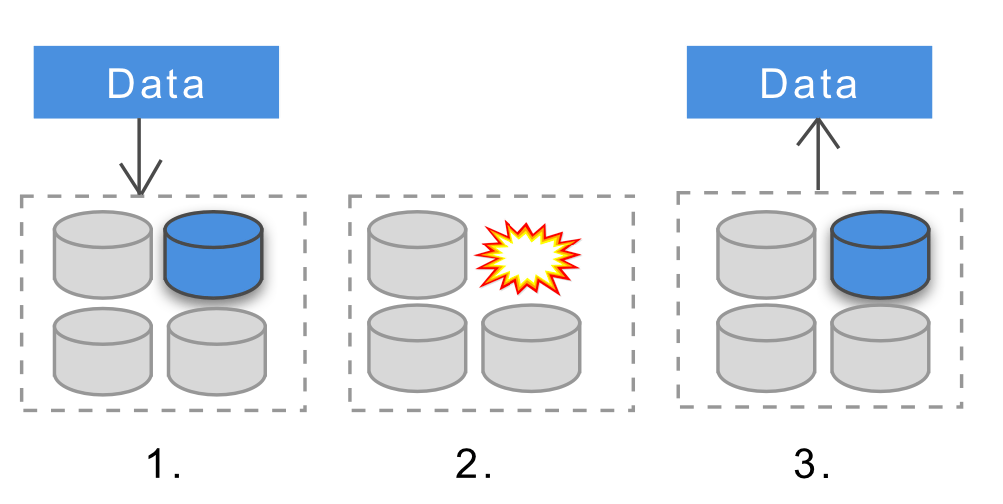
Message persistence and persistence(Message Persistence and Durability)
In a distributed system, nodes send messages to each other. The important thing here is that the message may not arrive correctly.Mission CriticalIn a system you must not lose any messages. In a distributed systemRabbit MQMessage service such as Kafka are often used. These message services can maintain reliability at multiple levels in sending messages.
Message persistence means that even if a node processing a message should fail, the message will be processed correctly after the failure is resolved. Message persistence is mainlyMessage queueThis means that when a message is sent, even if the destination node is offline, it will arrive properly when the node comes back online.
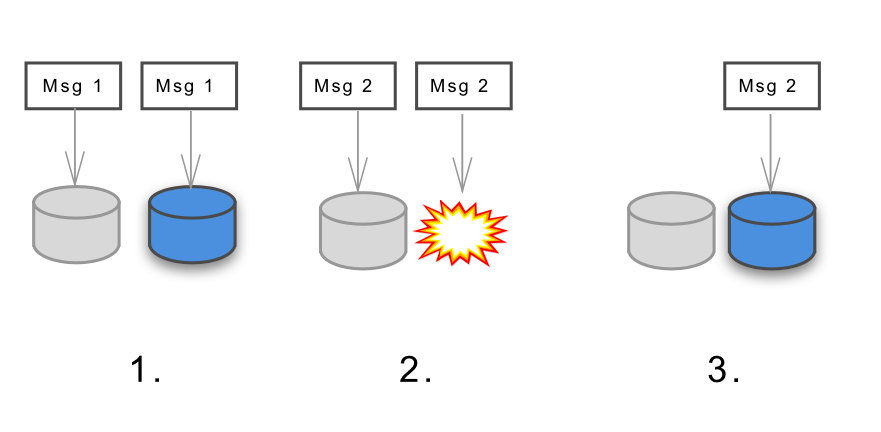
· Equality(Idempotency)
Positive equality means "to return the same result no matter how many times the same operation is executed". For example, in a settlement system, even if the client has been disconnected while paying and the payment is requested many times while repeating the reconnection, actual payment must be made only once. In order to construct a distributed system with equal equality, some kind of distributed locking system is necessary, wellOptimistic lockAnd so on are used. Engineer Ben Nadel wroteArticles on various strategies used to achieve equalityThat will be helpful.
· Sharding and quorum(Sharding and Quorum)
In a distributed system, it is necessary to store more data than one node can hold. The technique used there is sharding, which divides data horizontally with some kind of hash and allocates it to partitions.
In many distributed systems, multiple nodes have copies of the data. A voting-based approach is designed in which a certain number of nodes return the same result so that operations are performed in a consistent manner. This is called quorum.
· Actor model(Actor model)
The usual words that come up in programming, such as variables, interfaces, method calls, etc., are intended for systems that run on one machine, and when talking about distributed systems you need to use a different approach. Commonly used isActor modelSo this is what we can see from the viewpoint of communication. Other than thatCommunicating Sequential Processes (CSP)There is also a popular way.
The actor model is based on "actor" sending messages to each other. Each actor has only limited functions, such as creating other actors, sending messages to other actors, deciding what to do with the next message, but with some simple rules complicated It is also possible to express a distributed system well and to repair when another actor crashes. For the actor model, "The actor model in 10 minutes"It is recommended that the article say. Also,An actor model library exists in various programming languagesTo do.
· Reactive architecture(Reactive Architecture)
When building a large-scale distributed system, it is usually targeted that it is elastic, has a quick recovery from failure, and is a scaleable system. Reactive architecture is a pattern that is widely used in building such systems. For the reactive architecture, see "Reactive Manifesto"Article or"Reactive Application DevelopmentBook ofInterview with the authorThat will be helpful.
Orosz concludes the blog that he hopes to help people learning about distributed systems.
Related Posts:







in Software, Web Service, Posted by log1d_ts