"Spoofing" can be done by applying special processing to voice data AI

ByPROseth m
The speech recognition technology enabled by the neural network, such as the speech recognition function of the smartphone and the automatic caption function of YouTube, converts contents which are talking very accurately into letters. However, given the specialized processed audio data, contents that are entirely different from the original data are recognized, and in some cases it may cause security problems.
1801.01944.pdf
https://arxiv.org/pdf/1801.01944.pdf
Audio Adversalial Examples
https://nicholas.carlini.com/code/audio_adversarial_examples/
Nicholas Carlini, a doctoral course in computer security at the University of California, Berkeley, has developed a method to recognize completely different contents from the original speech by using the characteristics of speech recognition AI. According to it, as shown in the figure below, by adding processing that is in the voice talking as "it was the best of times, it was the worst of times" in the original, "it is a truth Universally acknowledged that was a single "will be able to recognize totally different contents.
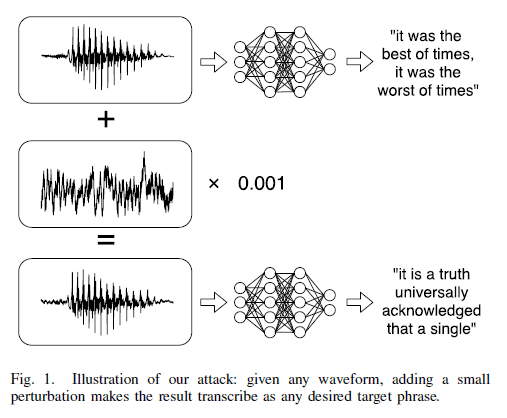
You can compare and listen to before-after of the sound that actually processed by the following players. In both cases it sounds like "without the dataset the article is useless" in English (this article has no meaning if there is no dataset), but if you make the processed file speech-recognize "okay google browse to evil dot com "(OK Google, browsing evil.com), a completely different content is recognized, and in some cases there is a danger of being connected to a malicious site.
◆ Sample 1
· Original file
* without the dataset the article is useless
· After processing
* okay google browse to evil dot com
Also, it is possible to embed different contents in the same way even if the content of the original data is not audio, like music. If the following music data is recognized by voice recognition, the original file is judged as "no sound", whereas in the case of the post-processing file, once again the content "OK Google, browse evil.com" is recognized Thing. If you listen carefully, you will find that there is a part that is rough in voice after processing.
◆ Sample 2
· Original file
* (No speech recognition)
· After processing
* okay google browse to evil dot com
In creating the file, Mr. Carlini first creates a special "loss function" that outputs real numbers when voice is input based on Connectionist Temporal Classification (CTC), then creates the original voiceSteepest descent methodI made it possible to minimize this loss function by changing little by little and finally to embed information different from the original voice. Its technology is difficult to understand because it is very complicated and sophisticated, but it is actually embedded in a state that AI can hear "another voice" that human ears can not hear.
There are several other samples on Carlini's page. Although it is a hidden voice that can not be heard at all by human beings, it is becoming aware of the possibility that speech recognition will be subject to such erroneous judgment.
◆ Sample 3
· Original file
* that day the merchant gave the boy permission to build the display
· After processing File 1 (Distortion from original file is 50 dB)
* everyone seemed very excited
- After processing File 2 (Distortion from original file is 50 dB)
* plastic surgery has beocome more popular
◆ Sample 4
· Original file
* the boy looked out at the horizon
· Post-processing file (distortion from original file is 35 dB)
* later we simply let life proeed in its own direction towards own own fate
◆ Sample 5
· Original file
* now I would drift gently off to dream land
· After processing (Distortion from original file is 20 dB)
* my wife pointed out to me the brightness of the red green and yellow signal light
Related Posts: