Amazon's AWS "S3" has failed and the net is confused and restored, but the influence still remains

On March 1, 2017 in Japan time, a massive failure occurred at Amazon's cloud storage service "S3". Due to the large number of web services using this service, there was a great disruption on the Internet, but the situation was restored about 3 hours after the occurrence, the situation is converging.
The Amazon S3 Outage Is What Happens When One Site Hosts Too Much of the Internet | WIRED
https://www.wired.com/2017/02/happens-one-site-hosts-entire-internet/
The high error rate was confirmed at AWS S3 on the morning of February 28 in the Pacific time in the USA. When it is Japan, it is early March 1 - early in the morning. The AWS Official Twitter Account has been issued a high error rate at S3 on January 4, 17:00 on March 1st local time (11:17 on February 28, local time) immediately after the incident, working hard to recover Reported.
S3 is experiencing high error rates. We are working hard on recovering.
- Amazon Web Services (@awscloud)February 28, 2017
At 4:57 in the 40th minute, the AWS official said, "It seems that we have found out the root cause for S3, it is recovering hard now, updates for all services will be reflected on the dashboard in the future "Tweet.
For S3, we believe we understand root cause and are working hard at repairing. Future updates across all services will be on dashboard.
- Amazon Web Services (@awscloud)February 28, 2017
When checking the AWS Service Health Dashboard at the time of article creation, most of the services are in a state where recovery has been completed.
AWS Service Health Dashboard - Feb 28, 2017 PST

Service that is in normal state is indicated as "Service is operating normally", but for services that have recovered due to a failure, "[RESOLVED] Increased Error Rates"(Rising" resolved "error rate) is displayed.
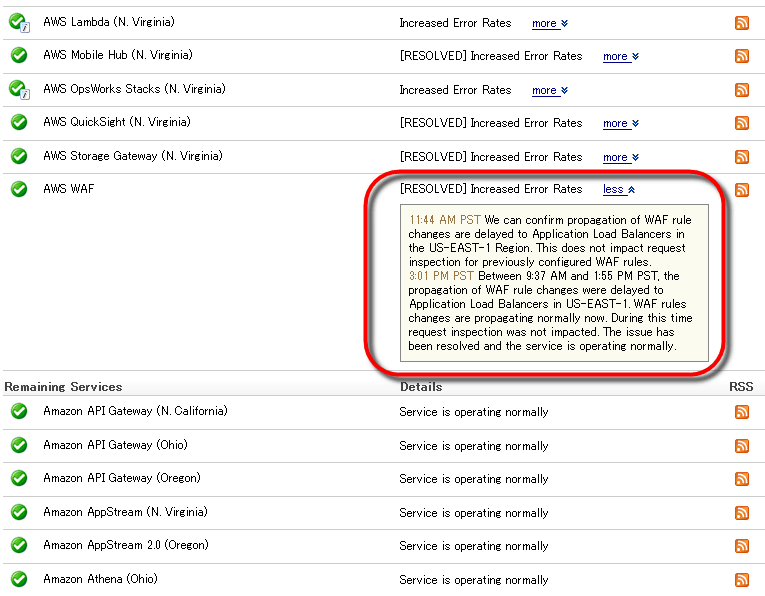
"Increased Error Rates" will be displayed for services that are still in trouble, and clicking "more" will display the details of the problems and remedies that are occurring.
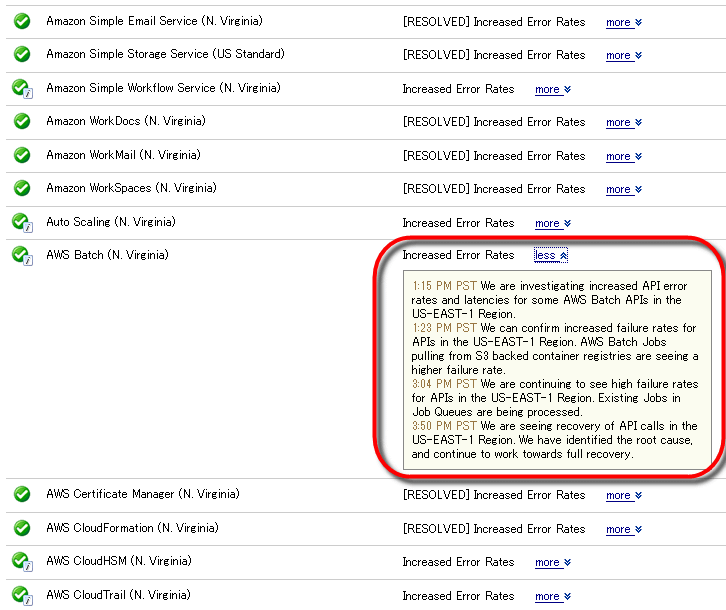
With this bug, it caused a situation in which many web services can not be connected, and we were able to catch a glimpse of the high dependency rate on AWS S3. As affected services, Q & amp; A siteQuora, Of a news siteBusiness InsiderEnable bulk postings and reserved postings to Twitter · Facebook · Instagram etc.Buffer, I can organize tasks by card sense within groupTrello, 60 or more web services can be linked to realize new functionsIFTTT, Activity logger such as jogging and cyclingStravaThere are a wide variety of them.
Which sites are down down of of S3 outage? | Hacker News
It is also said to be "more advanced than IFTTT"ZapierEven a failure occurred. On the site, the cause of the obstacle is clearly pointed out as "attributed to Amazon S3".
Zapier Status - Issues With our Upstream Provider Causing Availability Issues
The root cause was our upstream provider's (AWS) started popular file storage system (S3) started failing - which happ many issues for numerous websites across the internet - Zapier included.
In addition, Under the provisions of Amazon S3, "service credit" will be issued for such a situation, but it will not be refunded.
Service Level Agreement - Amazon S3 | AWS
https://aws.amazon.com/jp/s3/sla/
The service credit is only allocated to future Amazon S3 payments that the service user is supposed to pay. At Amazon's discretion, Amazon shall be able to issue service credits to the credit card used by the service user for payment of the billing period in which the error occurred. The service user does not acquire the right to receive refund or other payment from AWS by service credit.
And for this measure you have to charge it yourself.
In order to receive the service credit, the service user shall request by applying to the case to the AWS support center. Also, in order to be considered eligible, the request for credits must be received by Amazon by the end of the billing period, one after the occurrence of the event, including the following:
1. In the subject line, the word "request for SLA credit"
2. The date and time of each event for which the error rate requested by the service user is not zero, and
3. It shall include the request log of the service user (which deletes confidential information in the corresponding log or replaces it with "*"), which supports the downtime for the error user to record and record the error.
If Amazon confirms that the monthly usable time ratio pertaining to the request is less than the applicable service commitment, Amazon will inform the service user of the month in which the day the Amazon confirms the claim of the service user Issue a service credit during the next billing period. If the service user does not submit claims and other information that meets the above requirements, it shall lose entitlement to receive the service credit.
In addition, the following conditions are cited as "exceptional reasons".
Amazon S3 SLA Exception reason
Service commitment will not be applied if Amazon S3 is disabled, stopped or terminated, or any other Amazon S3 performance problem is due to: (Ii) if it is the result of a service outage specified in paragraph 6.1 of the AWS agreement, (ii) reasonable control of Amazon, including force majeure, Internet access outside the scope of Amazon S3's liability division point or related issues (Iii) if it is the result of an act or omission by a service user or a third party, (iv) the service user's equipment, software or other technology, and / or (Excluding third party equipment within the direct control of Amazon), or (v) a service user who uses Amazon S3 pursuant to the AWS agreement (Collectively, referred to as "Amazon S3 SLA exception event") as a result of the suspension or termination of the right of Amazon. In the event that availability is affected by factors other than those used by Amazon in calculating error rate, Amazon may consider this factor at Amazon's discretion and issue service credits.
The EC2 t2 family is fucking unstable, it tends to be placed on the same host when launching the instances together, "at the same time," EBS gacha ", 99% of the obstacles are in the console There is also a summary like "nothing is displayed". There are certainly some real feelings.
AWS bad know-how collection 2017/02 - Qiita
http://qiita.com/yayugu/items/de23747b39ed58aeee8a
Related Posts:







in Web Service, Posted by darkhorse_log