Algorithm commentary on the original Google
Now Google has become a powerful search engine influencing the world of the net. It is still Yahoo! in Japan. It is not so much because there are a lot of users, but the basic idea of the algorithm is similar, so the same result comes out. In other words, if you understand the first Google search algorithm that was the foundation of existing search engines, it will also be useful for search engine countermeasures.
So I will explain the original Google algorithm as easily as possible. Unlike the commentary of other existing sites, it is based on the neat first Google formula.
Details are as below.The Anatomy of a Search Engine
http://www-db.stanford.edu/~backrub/google.html
I think I've heard that Google's breakthrough ranking method is fully automated page ranking by mathematical formulas, but what was it like at the beginning of the formula? Because probably you probably never saw or heard it, commentary.
First of all, the page rank calculation formulas of Google are as follows. It is all the root formula.
PR (A) = (1-d) + d (PR (T1) / C (T1) + ... + PR (Tn) / C (Tn)
PRThat is page rank. On the leftPR (A)However,AIt represents the page rank of the page. Google indexes, or organizes, all of the collected pages, rearranges the link relationships of each other, rearranges them, puts them in this formula, and decides which page ranks page. The higher this page rank is, the higher it is displayed.
Next,(1-d)It is inDIs a numerical value determined in some cases and is used to weaken or reduce the numerical value when calculating the final page rank. This number is a numerical value between 0 and 1, and this time for this number is set to "0.85". The basis of this numerical value will be over again later.
Next,T1as well asTnThis is the number of pages citing the contents of page A. That is, it is said to be the number of pages pointing to page A. It is a page quoted from page A and linked to page A.
last,C (A)This is the number of links leaving Page A. In the above equation, each page of T1 and Tn is entered in A.
In other words, if you link from page A to another page X and that page X quotes the contents of page A and links, the page rank will rise. If you are linking from page A to page X, but there is no link from page X, the page rank of page A will rise a little, but conversely page X will rise. Also, as the number linked to page A increases, the page rank rises. Conversely, the more the link is made unilaterally from page A, the slower the increase rate of page rank will be.
In short, page rank is not merely a mutual link, so it is designed not to count on just mechanical interaction links by considering the character string of quoted pages to some extent. So, touching the content of the quote like a blog, when returning the link with the trackback, the page rank will rise and it will appear at the top of the search results.
Then, decrease this page rank mentioned earlierDIf it says something, it applies to the case of a dead end page or a similar page group. When you follow the link, you should finally be able to go to Doko even to Doko, but as you go through the page randomly with the rule that it will not return to the page that passed once, it will eventually become a "dead end" A page will come out. That is, it is a page that does not link anywhere. Not being linked anywhere is a page that is "out of place" from the page rank system, and it is not worthwhile because it does not give anything any influence on another page, so it can not go anywhere I think. Therefore, the value of d increases and the page rank falls. For example, if it is an isolated page linked only from the main page, the answer derived from the above formula should be close to page rank zero. By doing so, we will remove unworthy pages from the page we collected from our crawler, Google Bot. This is called "intuitive adjustment".
In addition, Google's proprietary algorithm is the handling of link string of pages, that is, anchor text. Importance is attached to what is written in the link string when linking from page to page. The character string that links to page A probably seems to be precisely catching the characteristics of the pointed page, such as "link to page A" or page A about apple, such as "go to the page of apple" . For that reason, we pay particular attention to link strings that hold anchor texts among links, and place importance as a basis for calculating page rank.
There are three other independent Google-specific algorithm elements that are not related to page ranking as well.
1. Geographical information
Considering from the IP address of the server where the page resides, we will summarize the pages that are geographically close together. By doing this, it seems that the pages concerned must be geographically the same language area. When I search from Japan, I feel that I will raise the rank to the page within the IP address range assigned to Japan. The reason why it is not divided simply by Japanese or English is that even in the Japanese-speaking world, English is used, and even in the English-speaking world, since Japanese is written in Romanized notation, simply character codes It seems that it is because it does not give an accurate result when judging by just the type of letters.
2. Visual elements
Google puts emphasis on visual elements, whether humans look at the page and pay attention to it. For example, if it is a large character it is more conspicuous, so it is more important than other strings. In short it is font size. In the case of blogs, it is effective because it automatically increases the font size of the subject. Likewise, it seems that it also adds a positional interpretation so that it is as important as it is located at the top of the page.
3. Cash
The caching function which is the biggest feature of Google is used to calculate the page rank calculated in this way, and by providing it as it is, in order to display the content at the time of page ranking which appears in the search result It is. For example, in the content of the latest page, the page rank is 100, but if we previously traveled on Google it was 10,000 page ranks. In that case, the search result will be at the highest level based on the data for page rank 10,000, but since the latest is about page rank 100, the search result will not match the content. Therefore, you can see the contents of the page at the correct page ranking by looking at the cache .... It is not a function to make the deleted blogs exposed again by flames (bitter smile)
Other than that, you can correct the ranking from the searched phrase and clicked page, recalculate it recursively according to a new page collected in real time, how to update it, how to save the collected page Whether to reuse it, and so on, various factors are intertwined.
I think that you can easily guess what kind of reasoning is based on so-called search engine countermeasures if you understand only this. In short, you can trick Google's page rank if you create a page that pretends to be a popular page. Therefore, it is said that the latest Google algorithm is to prevent measures against search engines from being adjusted by adjusting the gravity of elements other than page rank according to time and case.
In short, it means that you can create valuable pages that will be linked by everyone else.
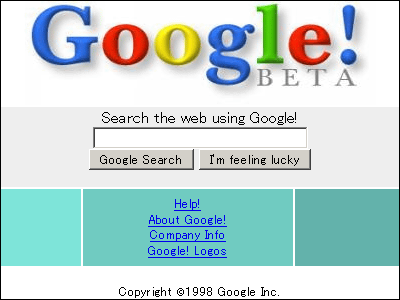
Finally, Omake, this is the first Google.
Google!
http://web.archive.org/web/19981202230410/http://www.google.com/
Related Posts:





in Note, Web Service, Posted by darkhorse_log