




コンピューターが人間を超える「AI」「ディープラーニング」「機械学習」とは何かについて解説する「Machine Learning 101」

By Not4rthur
自動運転車を操縦するAI(人工知能)や、ディープラーニングによって「世界最強」の名をほしいままにする「囲碁AI」など、近年のコンピューター技術は「AI」「ディープラーニング」「機械学習」というキーワード抜きには語れない状況となっています。Googleでシニア・クリエイティブ・エンジニアをつとめるジェイソン・メイズ氏が公開しているGoogleスライド「Machine Learning 101」では、それらの言葉の関わりがわかりやすく解説されています。
Jason's Machine Learning 101 - Google スライド

このスライドでメイズ氏が解説するのは、「機械学習とは何で、どんな種類があるのか?」「その仕組みは?」「どのように使われる?」「どこに向かっている?」という点。およそ2年にわたる作業の集大成としてまとめられたのが、この100ページにも及ぶスライドです。

なお、このスライドを読むにあたり、メイズ氏は「2時間これだけに使うこと」と、全てのスライドや動画を一気に読破することを強く勧めています。ただしそうすることで、読破後にはここに書かれている内容を全て理解することができるようになるとのこと。

なお、このスライドには緑のページと青のページが含まれています。緑は全員が必ず目を通すべきページで、青は関心を持った人が深く掘り下げるために読めば良いページとのことです。

◆「AI、機械学習、ディープラーニングとは何か?」

「AI」とは、「機械によって再現されるヒトの知性」と定義され、つまりヒトが行っているタスクをコンピューターに担わせるためのものです。AIにまつわる議論の焦点は時代によって変化します。

現在主流のAIは「ナローAI」と呼ばれるもので、「ヒトよりも巧みに行える物事が、あらかじめ定義された一個だけ、あるいは数個に限られる」というもの。これには、言語を理解して言葉を操る「自然言語プロセッシング」や、ゲームを練習して上達するAIなどが含まれ、「機械学習」はナローAIの一つに数えられるものです。

AIが使われるのは、物体認識、会話認識、音声検知、自然言語解析、絵画作成などのクリエイティブ分野、翻訳、欠落する部位を全体の中から推測して復元または変形する技術などの分野です。

次に、「機械学習」とは、「経験をもとにデータの中からパターンを発見して学習することができるAIを実現するためのアプローチ」と定義されます。機械学習は、人間がプログラミングすることでコンピューターに能力を身に付けさせるのではなく、データを与えるだけで自らアルゴリズムを作り、パターンを認識して学習することが可能です。

機械学習は、「物事を本質的に予測する」ためのもの。自らデータを取得し、パターンを学習することで、未知のデータに遭遇した時でも学習したパターンをもとに分類することが可能です。機械学習の優れている点は、一度学習したデータから再び学習することができるという点。しかもそこには人の手が介在する必要がないという、非常に大きな利点が存在します。

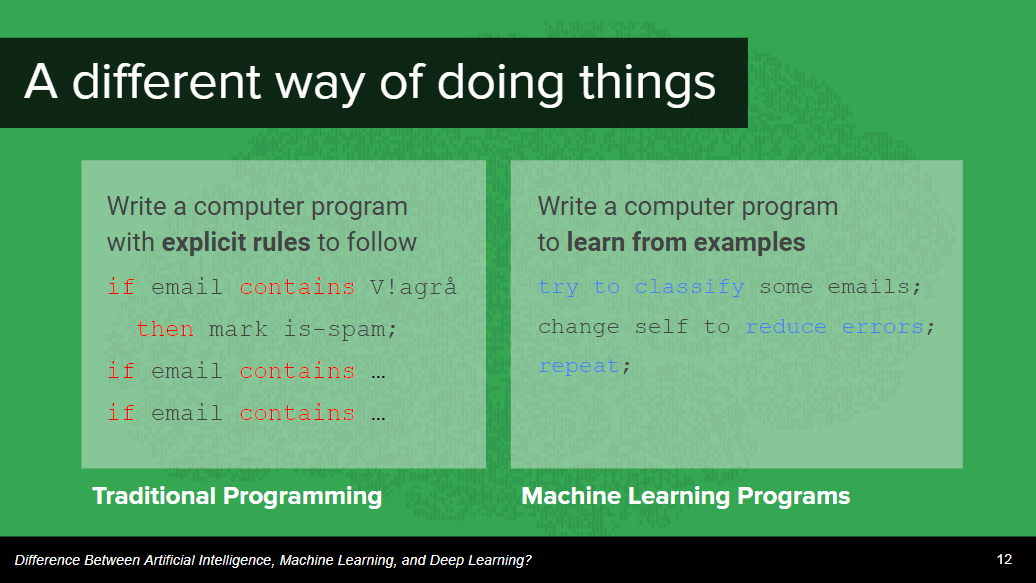
従来のプログラミング(下図左)だと、コンピューターには厳格なルールを与えなければなりませんでしたが、機械学習プログラミング(下図右)では、「メールを分類し、エラーを減らすために自己変化し、繰り返せ」という指令を与えるだけで、あとは勝手に機械が学習を続けてくれます。
そして最後に「ディープラーニング」とは。これは「機械学習を実行するための技法」と定義されるもので、この中には人間の脳の仕組みを再現する「ディープ・ニューラル・ネットワーク」という概念が含まれます。

これら3つをまとめたのが次の図。最も古いのが「AI」で、その概念は1950年代にすでに提唱されていました。その後、1980年代に「機械学習」が普及しはじめ、2000年ごろからは「ディープラーニング」が実用化されたことによってナローAIが実現されるようになってきたというわけです。

◆機械学習システムをトレーニングするためのデータの選び方

機械学習システムをトレーニングする際には、「特徴」または「属性」が与えられます。これは、学習しようとするものが備えているプロパティを意味しています。

果物を例にとると、たとえば「色」と「重さ」という属性が挙げられます。そして「2つの属性」は「2つの次元」を意味します。2次元は次の図のような2次元グラフで表現することができます。リンゴ(赤・緑の点)とオレンジ(橙色の点)をプロットした以下のグラフが存在する場合、機械学習はデータのパターンを認識することでリンゴとオレンジを区別することが可能になります。

しかし、この属性データの与え方を誤ると、満足のいく結果を得ることができなくなります。リンゴとオレンジについて、今度は「種の数」と「熟れ具合」の属性でデータを与えた場合だと、その結果は次のとおり。全ての点が同じ領域に固まってしまい、データを区別して2つの果物の違いが認識できない状態となってしまいます。つまり、どのようなデータをもとに学習を行うのか、という点が機械学習にとっては重要な要素となってきます。

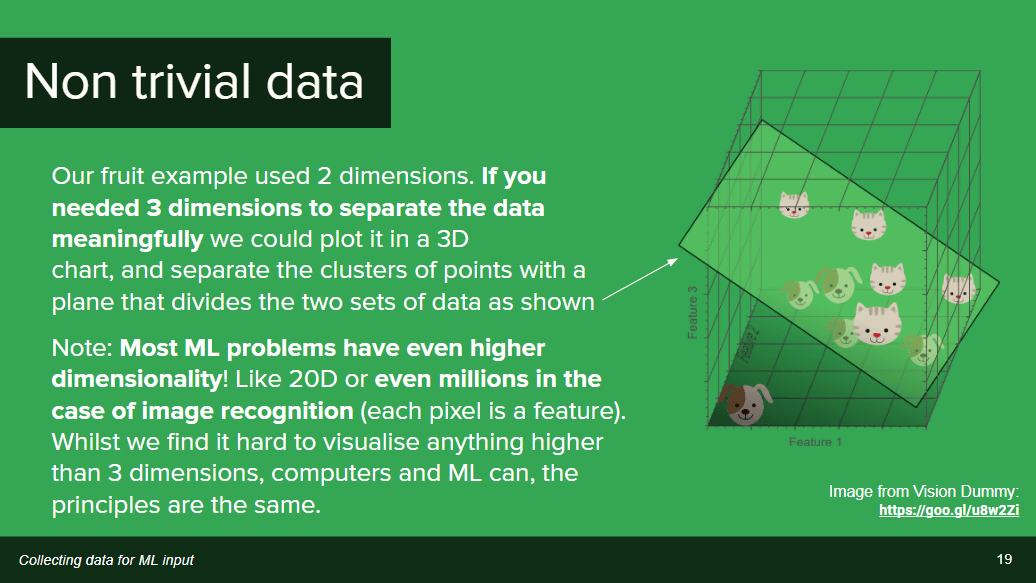
果物の例では2つの次元で判断が行われましたが、この次元はいくつにでも増やすことが可能。次の図のような3次元での判断は序の口で、学習する対象によっては「20次元」などに高次化する場合があるほか、個別のドットが1つの次元を構成する画像認識の場合に至っては「数百万次元」というレベルに達する場合も。次元が上がるにつれて処理も複雑化しますが、基本的な仕組みは2次元の例で挙げたようなものがベースになっています。
次に重要になってくるのが、「いかにバイアスがかかっていないデータをトレーニング用に用意するか」ということです。たとえば「ネコ」について学習させたい場合、妥当な結果を得るためには1万件程度のデータを与える必要がでてきます。与えられるデータは「画像」だけでなく、「複数の要素を含む表」や「テキスト」「計測機器によって得られた値」「音サンプル」など、対象となるものに応じて変化します。

一方、機械学習は「知らないこと」については予測を行うことができません。もしあらかじめ動物というものについて「足の数・色・重さ・種類」の要素をもとに「4・黒・10kg・犬」「2・オレンジ・5kg・ニワトリ」と学習させていた時に、新たに「牛」情報として「4・黒・200kg」という情報だけを与えると、コンピューターはこのデータをもとに「犬」と判断します。なぜなら、コンピューターはまだ「犬」と「ニワトリ」についてしか学習しておらず、より近い方を予測するためです。

これらの内容については、以下のYouTubeムービーを見るとより良く把握することができます。
The 7 Steps of Machine Learning - YouTube

◆機械学習システムが学習する仕組み

「教師あり学習」(Supervised Training)は、ラベリング済みのデータを与えることで学習を行わせる方法。たとえば、「果物」について「色・重さ・種類」という要素を教え込ませておくことで、新しい情報が入力された際に予測させるもので、現在はこの分野の開発が最も発達しているとのこと。

一方、「教師なし学習」(Unsupervised Training)は、ラベリングされていないデータセットをもとに機械が自ら学習を行うという仕組みです。以下の図のように、3つの塊を構成する要素があるような場合に、教師なし学習ではコンピューターがまず「3つのクラスタがある」ということを認識し、次にそれぞれをカテゴリ化します。ここで重要なのは、コンピューターにはカテゴリがいくつあるのかは事前に知らされていない、ということです。また、それぞれのカテゴリは例示されているような明確さで塊を構成しているとは限りません。

「強化学習」は、実行と失敗(トライ・アンド・エラー)を繰り返す中で、徐々に正しい方向を見いだすという学習方法です。たとえば、コンピューターに三目並べやブロック崩しのようなゲームをルールを教えずに実行させ、偶然に良い結果を出した時には報酬を与え、悪い結果の時には報酬なし、あるいは罰を与えます。報酬を最大限にすることを目標をするよう設定されたコンピューターは、このトライ・アンド・エラーを膨大な回数にわたって繰り返すことで、最終的には最も効率よく正答にたどり着く方法にたどり着きます。

◆実際にはどのようにして動いているのか

機械学習が動作する方法はいくつも存在します。以下のスライドでは、2次元のデータ例をもとにその仕組みが解説されています。

・例1:
グラフ上にいくつかの点が示されている時に、その近似曲線を求めるというのが機械学習の最もシンプルな例です。このようにして求められた近似曲線をもとに、「X」の値にある数値が入力された際に、「Y」の値が予測されます。これは、統計学の分野で回帰分析と呼ばれる手法で、機械学習はその本質として、このような近似曲線を求めるようになっています。

・例2
以下のグラフのように、2つのクラスタがあってその中間を分ける直線が引かれている場合、それぞれのクラスタは「赤クラスタ」と「青クラスタ」に分類されます。しかし、現実にはいずれかのクラスタに属していながらも、何らかの理由で異常値を示す個体(Outlier)が存在します。しかし、このような場合でも機械学習はさまざまな要素から正しくクラスタを分類することが可能です。また、例では単純な直線が示されていますが、実際には二次関数レベルの複雑な線でクラスタが分類されることがほとんどです。

・例3
上記のような「線」でクラスタを分類するのではなく、入力された値とすでに存在するクラスタとの近さ(距離)をもとに、属するクラスタを予測する方法があります。以下のグラフがある時に、新しい点がグラフの右下に入力されたとします。すると、機械学習アルゴリズムは「最も近い3点が青クラスタに存在する」という理由で、新しい点を青クラスタと予測します。これはk近傍法と呼ばれる手法です。

◆ニューラルネットワーク
人間の脳には、1000億個ともいわれる神経細胞のつながり「ニューロン」が存在しているといわれています。それらのニューロンは、互いに刺激を交換し、相手に対して出力を与えます。機械学習では、学習した内容から予測を行うために人工のニューラルネットワークが用いられます。

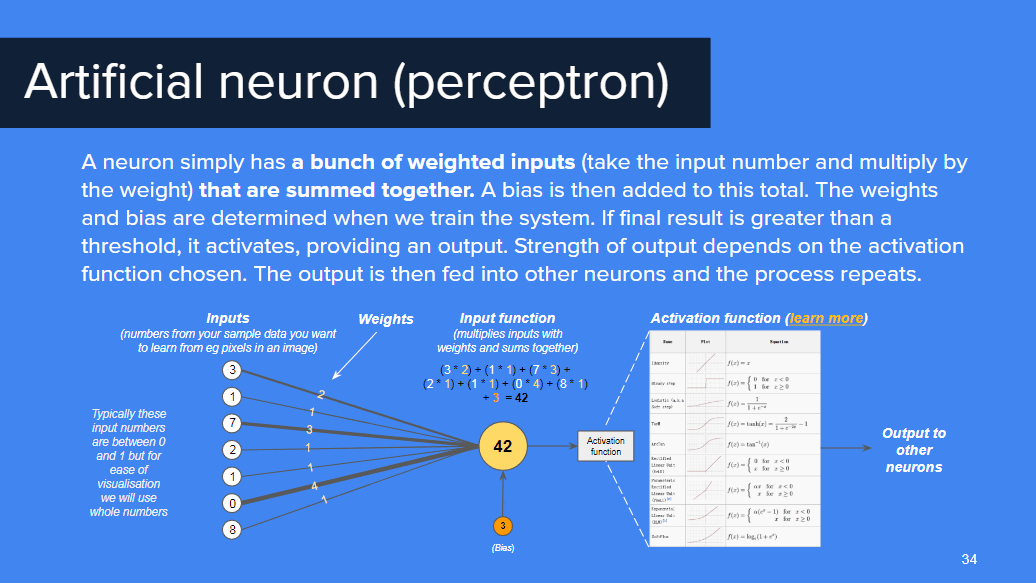
人工ニューロンは、生き物の神経を参考にしたニューラルネットワークを構成する基本単位で、複数の入力を受け取ります。。各入力には「重み」が加えられ、入力の値との積を合計した数値にバイアスが負荷されます。その結果が一定の閾(しきい)を超えた場合、出力として「シナプス」を生成され、また次のニューロンへと入力され、プロセスが連鎖的に続きます。
多層パーセプトロンは1960年代から概念が存在した「ニューラルネットワーク」の古い形で、全てのレイヤーが次のレイヤーにつながり、さらにその方向は一方向に限定されているもの。
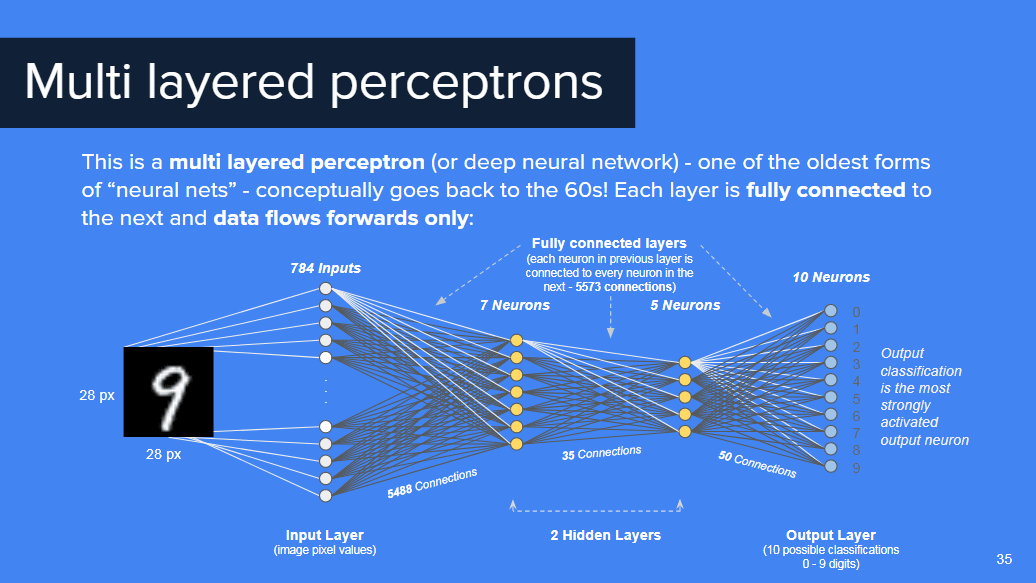
ディープ・ニューラル・ネットワークは文字どおり、いくつもの隠されたレイヤーからなる深いニューラルネットワークのことを指します。それぞれのレイヤーはその前から受け取った情報から学習を行うことで、よりレベルの高い学習を行うことができます。これらの隠されたレイヤーは普通、次元数が少ないためにデータをより良く一般化でき、同時にオーバーフィットすることもないという利点があります。これらの中間レイヤーは、「特徴の特徴」を学習することが可能。たとえば画像に含まれる「境界(エッジ)」が「顔のパーツ」につながり、さらにそれが「顔全体」につながることで、システムは顔を認識できるようになります。

このあたりの詳細は、以下のムービーで詳しく解説されています。
But what *is* a Neural Network? | Chapter 1, deep learning - YouTube
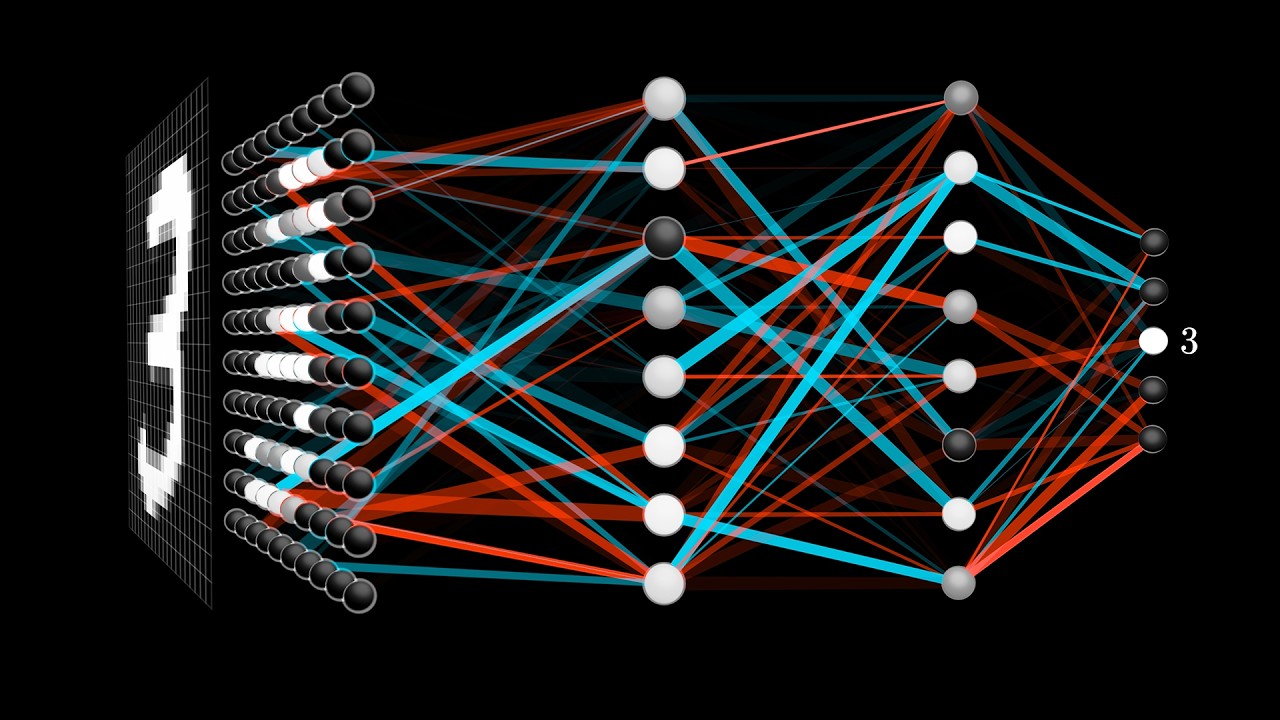
また、このムービーでは「畳み込みニューラルネットワーク」が画像認識を行う時の様子について詳しく説明しています。
How Convolutional Neural Networks work - YouTube

◆機械学習アルゴリズムの種類 (ここからしばらく続く青色のスライドは詳細について触れているので読み飛ばしてもOK)

・回帰
回帰とは、複数の変数の関係を予測し、モデルをあてはめるもの。回帰は統計学で用いられる手法であり、統計的機械学習に組み込まれています。

・インスタンスベース学習
インスタンスベースの学習モデルは、モデルにとって重要であるかまたは必要とされるトレーニングデータのインスタンスまたは例による決定問題です。このような方法は、典型的には、最良の一致を見出して予測を行うために、類似データを用いて例示データのデータベースを構築し、新しいデータをデータベースと比較します。この理由から、インスタンスベースの方法では、トレーニングの必要はなく、例のデータだけを必要とします。保存されたインスタンスの表現とインスタンス間で使用される類似性の測定に焦点を当てます。

・決定木
ディシジョンツリー(決定木)手法は、データの属性の実際の値に基づいて行われた決定のモデルを構築します。意思決定は、与えられたレコードに対して予測の決定が下されるまで、ツリー構造内で分岐します。決定木は、分類と回帰の問題のためのデータで訓練されます。決定木はほとんどの場合で高速で正確であり、機械学習では良く好まれるものです。

・ベイズ法
ベイズ法とは、分類や回帰などの問題に対してベイズの定理を明確に適用する方法です。その良い例は、ある電子メールがスパムであるかどうかを判断するために「使用されている言葉」などの可能性のあるさまざまな特徴を使用するような場合です。

・クラスター分析
回帰と同様に、クラスター分析は問題のクラスとメソッドのクラスを記述します。 クラスター分析法は、セントロイド法および階層型などのモデリングアプローチによって典型的に編成されます。すべての方法は、データ内の固有の構造を使用してデータを最高の共通性のグループに分類し、分類することに最も適しています。

・相関ルール
相関ルール学習方法は、データ内の変数間の観察された関係を最もよく説明するルールを抽出します。これらのルールは、大規模な多次元データセットにおける、重要かつ商業的に有用な関連を発見することができます。

・人工ニューラルネットワーク
人工ニューラルネットワークは、脳内の生物学的ニューラルネットワークの構造および、または機能にインスパイアを受けたモデルです。これらは、回帰と分類の問題によく使用されるパターンマッチングのクラスですが、実際には、あらゆる種類の問題タイプに対して数百のアルゴリズムとパターンからなる巨大なサブフィールドです。

・ディープラーニング
ディープラーニング法は、豊富で安価なコンピューター技術を利用する人工ニューラルネットワークへの最新の形態です。大きく複雑なニューラルネットワークを構築することが念頭に置かれており、大規模なデータセットにはラベル付きデータがほとんど含まれていない「半教師付き学習問題」に関連します。

・次元削減
クラスター分析と同様に、次元削減はデータ内の固有の構造を見つけ出して活用します。この場合、これはより少ない情報を使用してデータを要約または記述するために管理されていない方法または命令です。これは、次元データを視覚化したり、教師あり学習法で使用できるデータを単純化するのに役立ちます。 これらの方法の多くは、分類および回帰における使用に適合させることができます。

・アンサンブル学習
アンサンブル学習法は、独立して訓練された複数の弱いモデルを組み合わせることで全体的な予測を行うためのモデルです。どの弱いモデルのタイプを選んで、全てを組み合わせる方法を決定するかに労力が費やされます。 これは非常に強力な技術であり、非常に人気があります。
◆機械学習の出力の種類

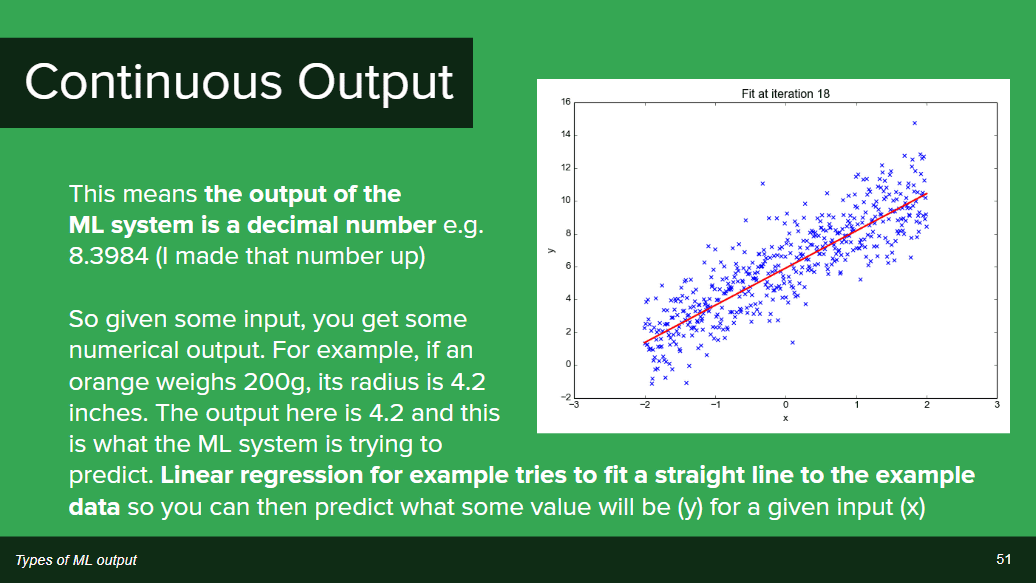
・連続値
出力される値が「8.3984」のように小数点を取るパターン。入力値が「200グラム」のオレンジだった場合に、出力値は「4.2インチ」の直径、というふうに数値を予測して出力します。直線回帰ではこの予測を直線にあてはめることで、X軸の入力に対してY軸の数値を出力します。
・確率推定
文字どおり確率を推定するというもので、数値は0から1までの範囲の小数点を取ります。数値が「0.751」の時は、その確率は「75.1%」であることを意味します。たとえば、以下のガラス容器の中に入っているブロックの数を推定するときに、出力が「9」と「54.3%」であるような場合。

・分類
これは、入力されたもののクラスを分類するというもので、出力される値は「連続値」や「確率推定」とは異なりラベル化するものとなります。例:入力「毛・前脚・ひげ」→出力「猫」

・出力を得たら活用する
上記のいずれかの出力を得ることができたら、今度はそれをプログラムを用いて活用する段階です。もし目にしたものが80%の確率で猫だとしたら、エサをあげたくなるでしょう。一方、その予測が75%だった場合は、もう少し確実な答えが出るまで待つかもしれません。

◆Googleはどのように機械学習を用いているのか?

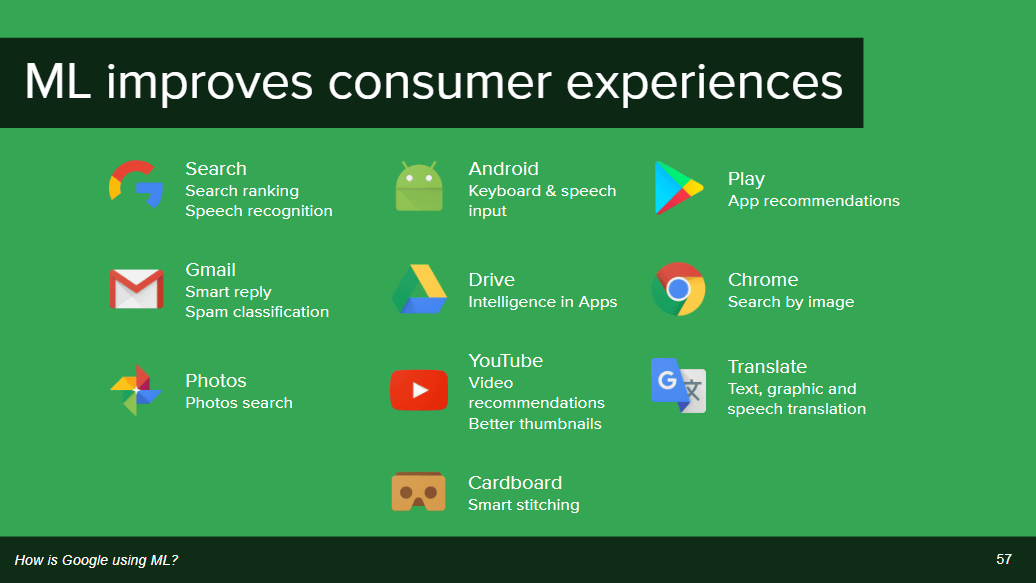
Googleが機械学習を用いているのは、「Googleフォト」のスマートサーチ機能や、「Gmail」および「Inbox」で自動的に返信を作成する「スマートリプライ」、そして目(=カメラ)で見た物と手の動きをロボットに連携させる学習を行わせる時など。
また、機械学習によって以下のようなサービスで利用者のエクスペリエンスが向上しているとのこと。
「Autodraw」では、何百万人という人に落書きをしてもらい、そこから学習したAIが自分で落書きできるようにすることが可能。

「Soli」は、デバイスに組み込むことでレーダーのように動作し、ジェスチャーを検知してデバイスのコントロールを可能にする技術。以下のように指をこすりあわせることでボリューム操作やマップの拡大・縮小が可能になります。

「Pixel Buds」はGoogleアシスタントと組み合わせることでジェスチャーコントロールに対応しており、さらにはリアルタイム翻訳にも対応しています。

「Google Lens」は、スマートフォンのカメラを対象物に向けるだけでいま写っている物を認識し、その店のメニューや口コミ、写真などを表示。

◆その他の機械学習の使われかた

ここから挙げられているケースは最先端研究の一部であり、すぐには世の中に出てこないものもありますが、そう遠くない未来に実現しそうなものも含まれます。

・ロボティクス
二本脚で歩行したり、バック宙することもできるボストン・ダイナミクスのロボットは、機械学習によってさまざまな機能を学習しています。

・スタイル変換
2枚の写真を与えると、一方の写真に存在するスタイルをもう一方に適用するというもの。これは単なる画像処理ではなく、実際に絵を描くように新しい「絵」が生成されるとのこと。

・動画生成
それぞれのテーマに沿った大量の動画を学習させることで、AIが架空の動画を自ら生成するというもの。現実にはない風景を作り出すことができます。

文をベクトル化する「Skip Thought Vectors」では、与えられた画像から文章を生成することが可能。モデルを「ロマンチックな小説」にすると、この相撲の取り組みが「彼は、心の中ではシャツを着ていない裸の男で、私にキスしようと肩に寄りかかってきたのでののしってやった。彼は、私が彼のボクサーパンツを着けると美しい少年になるだろうと考え、私を絞め殺そうとした」というものになるとのこと。

・画像を理解する
「カメラは世界を理解するための入り口点である」

「Thing Translator」(物体翻訳者)を使えば、カメラに映った物体を単語に置き換えることが可能。
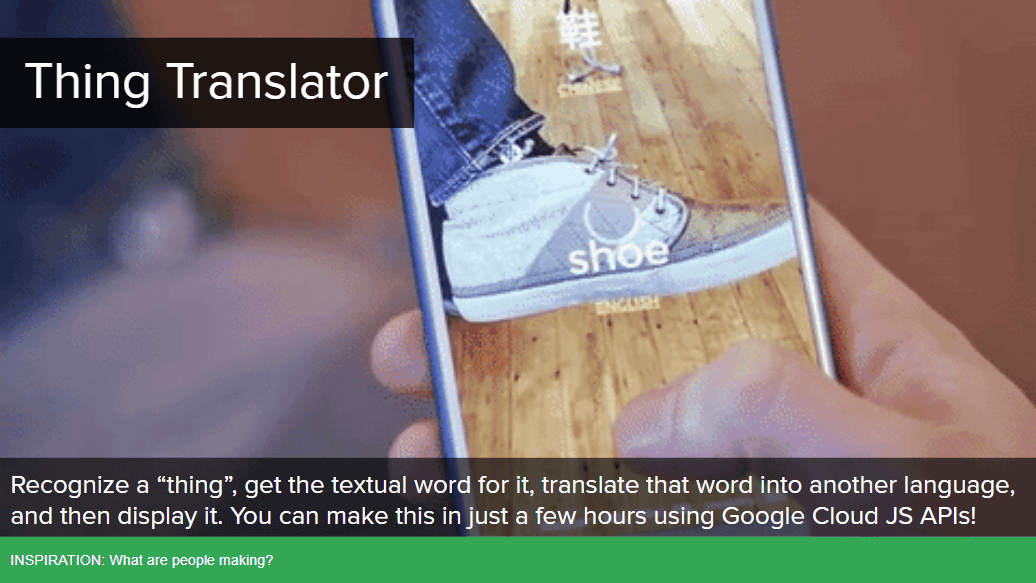
「Treasure Hunt」(宝探し)はカメラで撮影した画像を使う機能で、制限時間以内に「コーヒー」や「傘」、「グラス」など決められた物体を撮影するとAIがそれを認識して点数をもらえるというもの。
「Dragon Spotting」は、映画「ピートと秘密の友達」からスピンオフしたARアプリで、ソファーやテレビなど指定された物体にスマートフォンのカメラを向けると、画面上にドラゴンが現れるというもの。これも、画像から物体を認識する技術が使われている一例。

・複雑性を予測する
「大規模なパターンや行動を割り出す」

AlphaGoは、複雑な碁の勝負を機械学習を使うことで学習して強くなれるAI。以前は「碁は複雑すぎて人間には勝てない」といわれていましたが、AlphaGoは人類最強棋士を破ったばかりか、もはや人の手を借りなくともゼロから囲碁を覚えて強くなれるレベルに到達。

◆ユーザーエクスペリエンスの最適化
「コンテキストとパーソナライゼーションのための設計」

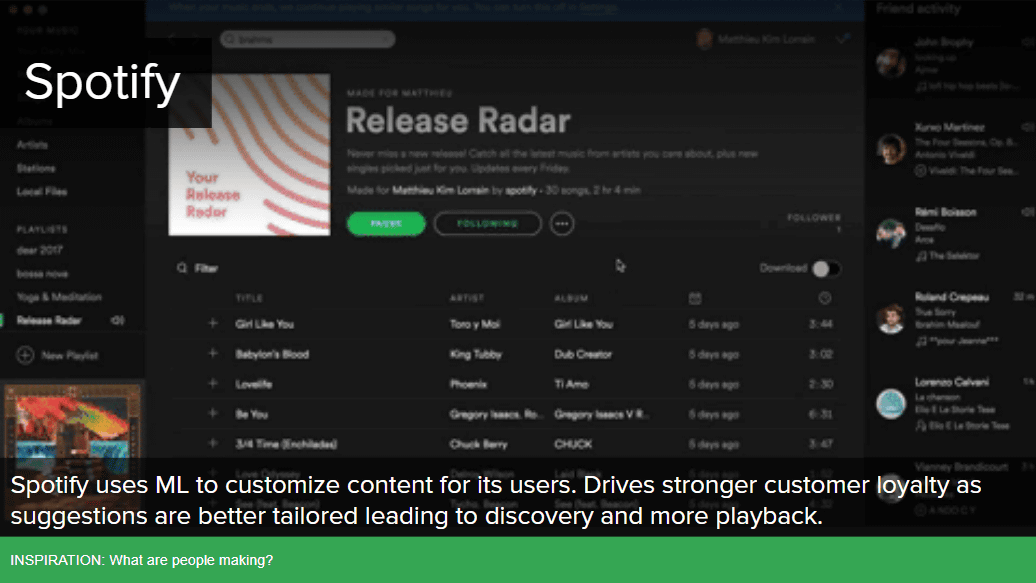
Spotifyは機械学習によってユーザーごとのコンテンツを生成。ユーザーの好みに合致したコンテンツを提供することで、より高いカスタマーロイヤルティを獲得。
アパレルブランドのZalandoはGoogleと共同で顧客に合ったファッションをデザインするProject Muzeをローンチ。個人の好みを分析し、最適と思われるデザインを提案します。

◆ユーザーと対話する
「日常生活の中における自然な意思疎通」

ディスニー・オーストラリアが提供している「Book Ears」は、絵本を読み聞かせる時に特定の単語を検知することで、シーンにあった効果音などを再生する機能。これにはGoogle Speech APIが用いられています。

アメリカのSFスリラーテレビドラマ「ウエストワールド」に登場するキャラクター「Aeden」がGoogleのAi技術によってデジタル擬人化され、自然言語で人間と会話できるようになっています。同作はこの技術によってもエミー賞を受賞しています。

◆機械学習を使えるGoogleの製品やAPI

Googleのサービス全体の中で機械学習に関連するものは以下のとおり。利用者が自由にカスタマイズできる「TensorFlow」や「Cloud Machine Learning Engine」、そしてあらかじめ用途が設定された「Cloud Vision API」「Cloud Speech API」「Translate API」「Natural Language API」などがあります。
Cloud Vision APIを使うと、コンピューターが物体や建物、ロゴ、顔や感情までをも理解することが可能になります。

画像から場所を割り出したり、写真に写っている物を認識したり、顔の表情から感情を推測したりすることが可能。

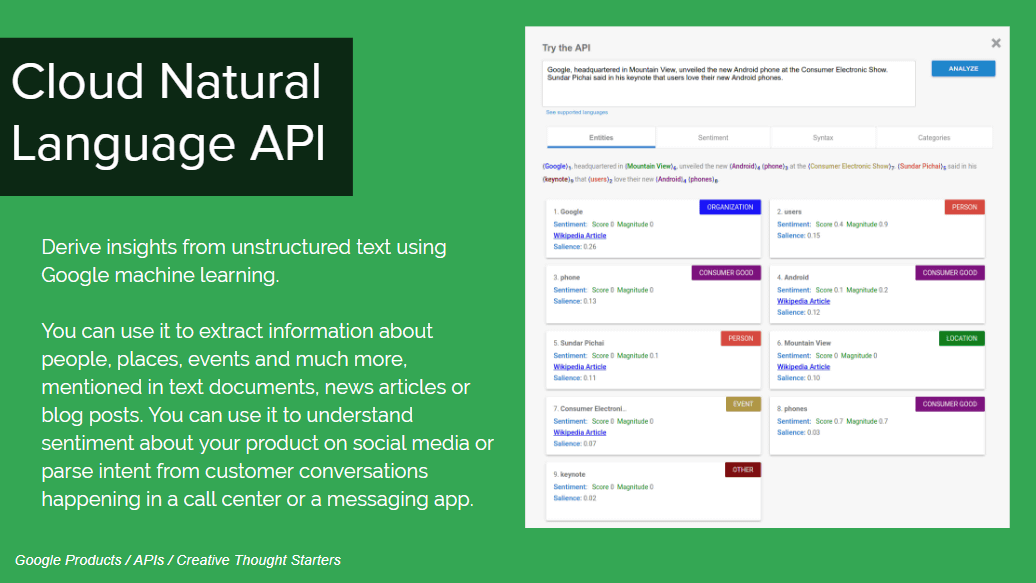
Cloud Natural Language APIは、構造化されていないテキストから機械学習でインサイトを見つけ出すことが可能なもの。これを使うことで、文書やニュース記事、ブログ投稿などの中から人物や場所、イベントについての情報を引き出すことが可能になります。またこれにより、自社の商品がSNSでどのように評価されているのかを分析したり、カスタマーサービスに寄せられているメッセージを総合して全体的な傾向をつかんだりすることが可能になります。
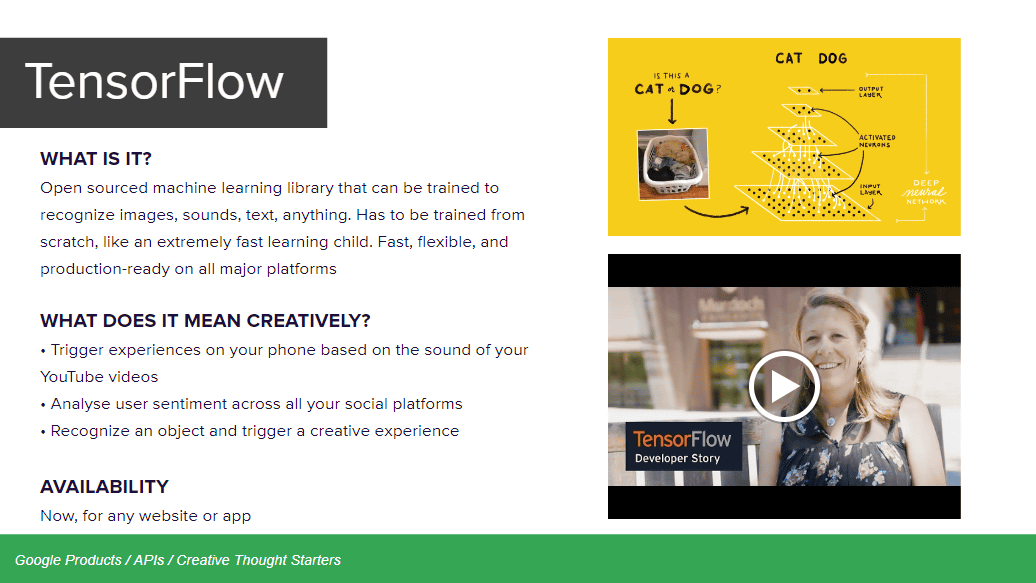
TensorFlowは、より幅広い用途が可能になる機械学習システムで、画家が描いた絵画のパターンを高度に認識してオリジナル作品の外側に絵画を拡張したり、囲碁で人間を破るなどの能力を獲得することができます。

TensorFlowはオープンソース化された機械学習ライブラリで、画像や音声、テキストなどあらゆるものを認識することが可能。YouTubeムービーに含まれる音声でスマートフォンの機能を呼び出したり、ユーザーの複数のSNSアカウントを見て感情を分析するなどの使い道があります。
Googleアシスタントでは、アプリに相当する機能「アクション」が用意されており、ホームオートメーションなどの機器を操作する「ダイレクトアクション」と、双方向の対話が必要な場合に用いることができる「カンバセーションアクション」の2種類が提供されています。Googleアシスタントはさまざまな危機に対応しており、小型マイコンのRaspberry Piから一般消費者向けの製品などに搭載することが可能。

Googleアシスタントのアクション開発やIoTデバイスなどで会話によるエクスペリエンスを可能にするプラットフォームがDialogflowです。これを使うことで、既存のサービスに会話型エクスペリエンスを追加したり、チャットボットやアシスタントをGoogleアシスタントに接続することが可能。

◆まとめ
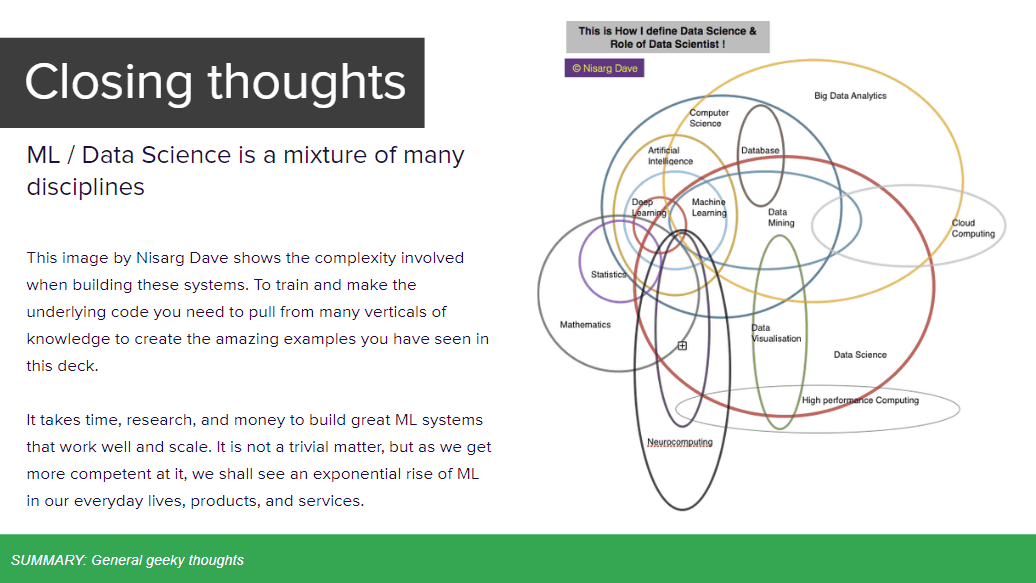
機械学習またはデータサイエンスは、複数の領域からなる集合体のようなもの。以下の図は、各分野のサービスを開発する際に必要な分野をまとめたもので、ある1つの固まりが別の分野のサービスの一部の様相になっているなど複雑に絡み合っている様子を垣間見ることができます。優れた機械学習システムを構築するためには多くの時間やリサーチ、お金などが必要になりますが、各分野の研究が進むことでさらに優れた機械学習が実現されるようになります。
・関連記事
「ディープラーニングとは何か?」を初心者でも分かりやすく実例を含めて解説するムービー「Introduction to Deep Learning: What Is Deep Learning?」 - GIGAZINE
初心者向け「機械学習とディープラーニングの違い」をシンプルに解説 - GIGAZINE
Googleが自社で使っている「クラウド機械学習」を一般に開放、こんなスゴイことが簡単にできる - GIGAZINE
さまざまな分野で大活躍の「人工知能」で注目すべき5つのポイント - GIGAZINE
Google翻訳のAIは独自の「中間言語」を習得して「学習してない言語間の翻訳」すら可能な段階に突入 - GIGAZINE
・関連コンテンツ






in ソフトウェア, Posted by darkhorse_log
You can read the machine translated English article "Machine Learning 101" which explains wh….