




TwitterやFacebookで使われている「Apache Hadoop」のメリットや歴史を作者自らが語る

大規模データの分散処理を支えるJavaソフトウェアフレームワークであり、フリーソフトウェアとして配布されている「Apache Hadoop」。その作者ダグ・カティング(Doug Cutting)さんが「Cloud Computing World Tokyo 2011」&「Next Generation Data Center 2011」において「Apache Hadoop: A New Paradigm for Data Processing」という講演をしていたので聞きに行ってきました。
満員の客席。

皆様を前にして講演できることを大変光栄に思っております。「Apache Hadoop」について皆様に伝えていきますが、これはまさにデータ処理の新たなるパラダイムを提供するものではないかと私は思っております。

まずは簡単に自己紹介をさせていただきましょう。私は25年に渡ってシリコンバレーで仕事を続けてまいりました。いくつかの会社に勤めましたが、元々はゼロックスパークで仕事を始め、その後はアップルでMac OSのSpotlightの中に搭載されているテキスト検索エンジンを作り、90年代に入るとExciteでウェブサーチを担当し、直近だとYahoo!に勤めていました。
実際にどういった研究をしてきたのかという話もしていきましょう。特にこの10年間は一連のオープンソースプロジェクトに関わって参りました。1997年の空いている時間にluceneという検索エンジンの開発に努め、2000年にはオープンソースプロジェクトとして開放したSourceForgeのもとにおり、そして2001年、Apache Software foundationから招致を受けました。それ以降、Apache Software foundationとはいくつかのプロジェクトで関わらせていただいております。luceneの後の2003年、Apache Nutchというプロジェクトを立ち上げました。「オープンソース機能」、「ウェブ検索エンジン開発」ということでかなり野心的なプロジェクトだったと思います。GoogleやMicrosoftがやってきたことに匹敵するものをオープンソースのプロジェクトでなんとかしようという目的でこのプロジェクトは今も継続中です。そして2006年、Nutchの一部を新たなプロジェクトとして展開させ、「Hadoop」というものが誕生しました。これの詳細は後ほど説明していきます。現在はクラウデラでアーキテクトとして勤務しております。また、同時にボランティアベースでチェアマンとしてエイセフにも在籍しております。

これから「Hadoop」の本題に移っていきますが、その前に簡単に「Hadoop」の可能性について語っていきたいと思います。データというものは、今まで以上にどんどん増えています。なぜ増えているのか?その一因は、どんどんデータを保存するコストが安くなってきたからです。ハードウェアコストもこの数十年間低下傾向にあり、今後もさらに安くなっていきます。CPUの値段も下がっています。コンシューマがどんどんPCを使うようになった結果、値段がどんどん下がってきました。しかしながら一方で、従来型のデータベースの技術はどうでしょうか?この勢いについていっていないんです。
従来型のデータベース用にハードウェアを購入するとしたらどうでしょうか?実はコモディティ化されたPCハードウェアよりも高くついてしまいます。演算能力も同じ、あるいはPCとしての能力も同じなのに高くなってしまう。また、エンタープライズのテクノロジーの拡張性が問題となっています。数千台のコンピューターへのスケーラビリティがなかなか厳しい。つまり、先見的で透過的なスケーラビリティが大型のデータセンターではなかなか難しいというのが現状です。まさに今は分岐点。本当は値段も安くすることが可能なはずなのに、実際のところ、従来型の提供しているものと乖離がある。そして、この乖離にこそチャンスがあると私は思っています。ただ、せっかくのチャンスですが、このチャンスを物にするのは中々難しいです。言うまでもなく、数千台ものコンピューターに信頼性を持ってスケーリングすることはなかなか大変なことですから。

ちょっとここで想像してみてください。ペタバイト相当のデータストレージを数千あまりのドライブでやっていかなければいけない。そのドライブは平均すると一年に一回くらい故障するかもしれない。数千のドライブが年に一回故障するとしたら、毎日のように何かしらが壊れているという計算になります。つまり、毎日何かしらが壊れる。しかし、皆様が開発しているシステムというものはこういう故障を見越した上で円滑に運用を続けなければいけないというのが現状です。ということはストレージシステムとしても効果的に耐えられるものが必要ということになります。迅速にFailureに対応し、プロセスを中断させることなく耐用できるもの、そしてもちろん高可用性が担保されていなければいけません。ハードウェアドライブが一部故障したとしてもHD(ハードディスク)は担保されなければなりません。また、同時にフォールトトレラント設計なコンピューティングのフレームワークが必要です。したがって、たとえどこかでハードウェアが故障したとしてもそういったFailureに影響を受けることなくフォールトトレラントの環境で十分円滑に業務を遂行していかなければなりません。

実はもう一つ課題があります。クラスタが大きくなると転送のコストがかかってしまう。確かにネットワークはスピーディになってきました。しかし、ネットワークで敢えてデータ検査をやらない方がスピードは担保できるわけです。例えばですが、100テラバイトのデータセットのプロセスが必要だったと想定します。1000ノードのクラスタがある。そしてネットワークを介してデータセットの読み込みを各ノードから別のノードへやっていると想像してみてください。そして各ノードが同時進行で他のノードと100メガビットのスピードで通信できるとしましょう。そうするとどうでしょうか?165分間かけて全てのデータセットをネットワーク上で処理するということになります。一方で、データがローカルドライブに乗っかっていた場合はどうでしょうか?するとデータの読み込みがより迅速にできるわけです。現在のドライブであれば秒間200メガバイトぐらいのスピードが出ます。換算すると、全部のデータの読み込みに8分しかかからない、ということになります。したがって、ここでの理屈は、データを動かすよりも実はこの処理能力を逆に利用して同一のハードウェア上で処理を行った方がより担保できるということです。

今日は「Hadoop」に焦点を絞っていくわけですが、こういった課題やチャンスがある中で、私は「Apache Hadoop」こそがまさにデータ解析における回答ではないかと思っております。何千ものコモディティ化されたコンピューターにスケールできますし、全部のハードウェアをきちんと制御できます。全てのコア、CPU、さらにはハードドライブ、スピンドルなどがきちんと稼動する。Read/Writeもきちんとやりながら、効果的に処理できることが保障されていきます。ですから他のコンポーネントを待つことなく、絶えず継続的かつ効果的にコンピューティング能力を使うことができるわけです。
こちらは、新しいソフトウェアスタックになります。しかも、いくつかの異なる原理原則に基づいて開発されました。実は多くの企業によって既に採択されており、アメリカのWeb2.0系の大手企業、たとえばFacebookやTwitter、AmazonやeBayといったところは既に「Hadoop」を採用しております。そして、こういったweb系の企業以外でも「Hadoop」を採用する割合はどんどん増えております。
では、新しいプラットフォームだと申し上げましたので、敢えて5つに絞り込んで皆様にご紹介していきたいと思います。これこそが新しいパラダイムの特徴だと思っておりますから。まずは「コモディティ化されたハードウェア」。これは後半で触れていきます。2つ目は「シーケンシャルファイルアクセス」、従来のランダムアクセスではなくシーケンシャルファイルアクセスです。そして「シャーディング(パートシニング)」、データコンピティションを大型のマシンに関わらず、自動的にパートシニングしていくということです。さらに「信頼性を保証しながら自動化を推奨していく」ということ。ハードウェアは時として壊れるんだという前提で、ハードウェアの上のソフトウェアに信頼性を組み込んでいくということです。そして5つ目は「オープンソースである」ということ。これは新たなパラダイムの現象における共通ブームなのではないかと。そしてオープンソースこそがいろいろな事象を誘発していると思っています。

では、最初の「コモディティ化されたハードウェア」からいきます。この場合の「コモディティ」とは何なのか。CPUやハードドライブ、メモリなど、PCの中に搭載されているものは劇的にコストダウンし、性能はこの10年間で大幅にアップしました。コモディティハードウェアを使って「Hadoop」の環境で使う、あるいはデータセンターの中で使う時にはある特定の使い方をしています。簡単な図が出ていますが、大型のラックやノードを使いながら活用するというやり方もあります。
例えば1ノード、単位で1から4くらいのCPUがあって、メモリがある程度割り当てられていて、2、4、8ハードドライブが搭載されており、各ノード単位で2、4、8くらい割り当てられている。そしてこれをラックに搭載し、ラック単位で20とか40ノードくらいが収まるでしょうか。そしてラックごとにネットワークスイッチが搭載されていて、このラック上のノードがここで繋がっている。そしてスイッチごとにそれぞれ、より高次のスイッチと繋がっている。これがさらにラック全部を繋げていく。まあ、非常に典型的なコンフィグだといっているわけです。従ってデータをあちらこちらに動かすこととなった場合にはノード上のローカルディスクからいとも簡単に、効果的に同じラック上のデータを移動することができ、読み込むことができる。しかし、他のラックからのデータの読み込みとなると若干遅延が発生するという構成です。
さて、このコストなんですけれど、これも重要なポイントです。非常に合理的な価格になっています。このストレージと処理能力に対してです。拡張性は何万のマシンまでにも対応できますし、性能も線型に上がっていきます。例えば10ノード、100ノード、1000ノード以上という使い方もされるということです。

もう一つの原則について話をしたいと思います。この新しいパラダイムでの次の要素は「シーケンシャルファイルアクセス」です。全文インデックスは80年代に取りかかった内容なんですが、教科書やテキスト文庫を見ながらインデックスの作り方を学び、ビーツリーについてもその時覚えました。これはイギリスのデータベースの基本的なテクノロジーになります。そしてログエンのアクセスをハードドライブに対し、「全てのアップデートについてする」、「ビーツリーに対してする」という原則に基づいています。でもこれ、ディスクシークなんです。ランダムアクセスはハードドライブのシークになりますから。この2、30年の間、シークの時間は短縮していません。コンピューターのパフォーマンスの要素として、他には追進できていないのがこのシークタイムで、むしろこれは例外的に増えていると思ってください。そしてこの「シークタイム=無駄な時間」なんです。ですからアップデートやアクセスが頻繁にあるという時は、このビーツリーが非常に時間がかかって遅いということです。

これは1980年代、1990年代に私自身が気付いたことです。Exciteでweb検索の仕事をしていましたけれど、効果的にインデックスを構築する唯一の方法が、これではなくてパッチシステムを使うことでした。大規模なデータベースをソートし、そこに対してアップデートし、アップデートをソートして、さらにそのアップデートとデータベースをマージさせて新しいバージョンを作るというアプローチを取りました。このような形でソートしたマージをバッチプロセスとして扱っておりました。そうしますと、全てシーケンシャルになるんです。シーケンシャルアイオペレーションになっていきます。そうすると、この大型のインデックスオペレーションの場合は10倍、100倍と速くすることができるんです。luceneにも同じ原則を用いました。そうすると伝送の時間、データをRead/Writeしている時間が大部分を占めるようになります。そしてシークタイムという無駄な時間を減らすことができました。それによって、現在用いることのできるハードウェアの恩恵を十分に受けることができるようになったということです。

次の要素の話をしたいと思います。「オープンソース」という側面です。オープンソースは、この何十年かの間に多く見かけるようになりました。多くの企業がその仕組みについて理解してきています。最大のアドバンテージはコスト削減ではないでしょうか。ソフトウェアが無償であるということ、無償で提供されるということがまず一つのポイントです。それから開発コストも大幅に下げることができます。つまり、そのコストをコラボレーションしている複数の企業で負担することができるからです。テストやQEについても同様です。後は文書化してドキュメンテーションする際にも他の企業と一緒にコラボレーションしてやりますので負担を分割することができます。それから、オープンソースのほうがよりよいソフトができるということも言えるかもしれません。例えば開発者が何かを書いている際に「他の多くの人が見るんだ」と意識することによって、より質の高い仕事をするということも往々にしてあります。また、自分自身、あるいは自分の会社だけが使うんじゃない、他の会社も使うんだと意識することによって、より一般性の高いものを作るようになります。短期的に、自分のニーズを満たすためだけでは十分ではないからです。そんなものは他が関心を寄せてくれません。

例えばソフトウェアを変えるためのコンセンサスを得ることにしても、一般的に使えるようなものでなければそれはコンセンサスを得ることができません。だからこそソフトウェアはより質の高いものになっていくのではないでしょうか。それからもう一つのオープンソースのアドバンテージとして、社員の満足度が上がるという点ではないかと思います。つまりモチベーションです。自分の同胞や同僚から敬意を表してもらえるのでモチベーションを感じるわけです。それがとても重要なんです。2名とか5名のデベロッパーが集まったチームで仕事をするのではなく、100人単位のデベロッパーと仕事をすることによってモチベーションを感じる。もし転職して次の職場に行ってもその人達との繋がりは消えない。生涯を通してその人達と仕事をするようになっていくかもしれません。そういう人達から敬意を表してもらえ、一目置いてもらえるということがモチベーションとなり、仕事を楽しいと感じるようになります。私自身もそれを目の当たりにしてきました。いろいろな人がこういった理由からオープンソースプロジェクトで仕事をすることを好むのです。

Apache Software Foundationで10年以上仕事をしてきましたけれど、最後のポイントとしてここで言っておきたいのは、オープンソースというのは「ただ無償のソフトウェアを提供する、そしてソースコードも開示する」ということではないのです。コラボレーションのコミュニティを構築するという意味も持つんです。そしてこれらのコミュニティがきちんと回っていくように担保していかなければなりません。Apacheはそれを見届けています。コミュニティというものは多様性が必要であると思っているからです。1社が支配するようなプロジェクトでは困るのです。どんな開発者でも均等な機会を与えられ、政治的な側面がなくなってきて、純粋に技術的なプロジェクトになっていきます。Apacheという場は、デベロッパーがコントロールする任意の団体であって、決して一企業が組織を支配しているわけではありません。

それでは、これ以外の要素についても申し上げていきます。「Hadoop」の歴史に関連する様々なものです。2002年に始まったのがNutchです。このNutchはwebページにおけるデータベースの構築に必要なものでしたので、URLでデータベースをシャーディングしています。つまりパートシーニングしている、データベースを複数に分けていくということです。URLのハッシュコードに基づいてこれをやっていきます。そしてデータベースの一つ一つのセグメントをネットワークの異なるノードに乗せていくんです。それからバッチベースの処理をしていきます。これは、さきほどちらっと話したことです。例えば新しいページがクロールされたとします。そして、そのデータベースを新しいページのリンクをもってアップデートしたい、どのページに対するリンクなのかということも含めてアップデートしたいということであれば、その新しいURL、アップデートをURLのハッシュコードに基づいて切り分けて、このシャードあたりの一つのファイルに対して入れ、ノードをコピーして、そのシャードを持っているノードに対し、既存のデータベースとそれを統合していくということをするわけなんです。

非常に拡張性のあるもので、大方のデータベースには対応できますし、効率もいいです。こういったステップを踏む必要があるんですけれど、今までマニュアルでやってきました。拡張性のあるアルゴリズムはあったものの、かなり大変でした。ある担当者がそれを4つ、5つのノードで走らせるということはできても、それ以上にはなかなか対応できなかったんです。例えば様々な故障がある、ハードドライブがいっぱいになってしまうといった課題も出ましたし、このデータをコピーするというマニュアルの作業がとにかく大変でした。

という中で2004年になり、Googleが何枚かペーパーを出しました。Googleが同じ問題に直面していて、どう解決しているのかということを書いたペーパーです。実はGoogleも似たようなアルゴリズムを使っていました。Googleは自動化していたんです。そういうシステムを持っていました。Google File System、そしてMapReduceのコンピューティングフレームワーク、こうしたことについて書いたさまざまなペーパーが出ましたけれど、この中で分散型のソートマージに関する自動化について書いたわけです。それからGoogleは信頼性のハンドリングについても自動化をしていきました。何か障害があったとき、自動的にそれに対応することができるというものです。「ディスクがいっぱいになってしまったら何か他のものに振り返る」というようなことを自動でやるようになりました。やはりオープンソースもこうでなければいけないと考えたんです。当時はGoogleしかこういうツールをもっていませんでした。ですからオープンソースでもこれが必要ではないかと考えまして、それを提供していこうという取り組みが始まったわけです。

そこで私とマイク・カフェデラーという2名の人物が数年間に渡ってこういった作業を続けて参りました。これも我々の空いている時間で開発を続けてきたわけですけれども、恐らくこれが具現化する、つまりは何千台というコンピューターで信頼性を持って実施するには相当の時間がかかるだろうと予想しました。20台まではいきました。そこそこの信頼性は担保できたわけです。でも、冒頭でも申し上げたように信頼性の高い分散ソフトウェアを開発するというのはなかなか大変です。

そこで2006年、私はYahoo!と対話を始め、Yahoo!は興味を示してくれました。そういった課題があるよね、と。そして彼らは、我々がNutchで開発したソフトウェアをプラットフォームとして採択するということに興味を示してくれました。かなり大掛かりなエンジニアチームをYahoo!は抱えていましたし、多くのエンジニアも興味を持ってくれましたので、2006年に私はYahoo!に入社しました。そして「Hadoop」というプロジェクトが誕生しました。Distributed Map System、それからMapReduceだけを引っ張ってきて、こういった新たなプロジェクトが誕生した次第です。

ではここで、HDFSとMapReduceについても簡単に紹介しておきましょう。HDFSは「Hadoop Distributed File System」の略称ですが、非常に拡張性はいいです。ファイルはコモディティハードウェアできちんと共有化、パーティシニングできますし、非常に効率も高い。Read/Writeも効果的で値段も安いです。ハードウェアコストもクラスタの運用も比較的低コストでできてしまいます。信頼性はどうでしょうか?信頼性に関してもほぼ全部自動化できている。各ブロック単位で3つのデータノードにそれぞれデュプリケーションされていますので、データを失ってしまうという確立も少ないわけです。クラスターも何年もの間、Yahoo!内でほとんどデータを失うことなく実装が続いています。自動的にデータのリバランスも行われます。1ドライブがいっぱいになってしまったり、ハードウェアが故障してしまうと、デュプリケーションが他のノードへ自動的に行われる。全て自動的に行うだけでなく、監視も自動的に行われています。ファイルシステム、シングルマスターがあります。ネームノード。しかしこのシングルマスターにはホットスペアがありますので、万が一これが故障、Failureした場合でも、可用性が影響を受けるということはほとんどないと言ってもいいかと思います。

MapReduceについて簡単に説明しておきたいと思います。プログラムモデルとしては至ってシンプルで単純な内容になっていますけれども、コモンパターンのプログラムの汎用性ということで、大方のクラスターでも並列環境が組みやすいという特徴を持っております。左側から行きます。まずインプットデータを取り込み、そしてこれを塊ごとに切り分けていく。
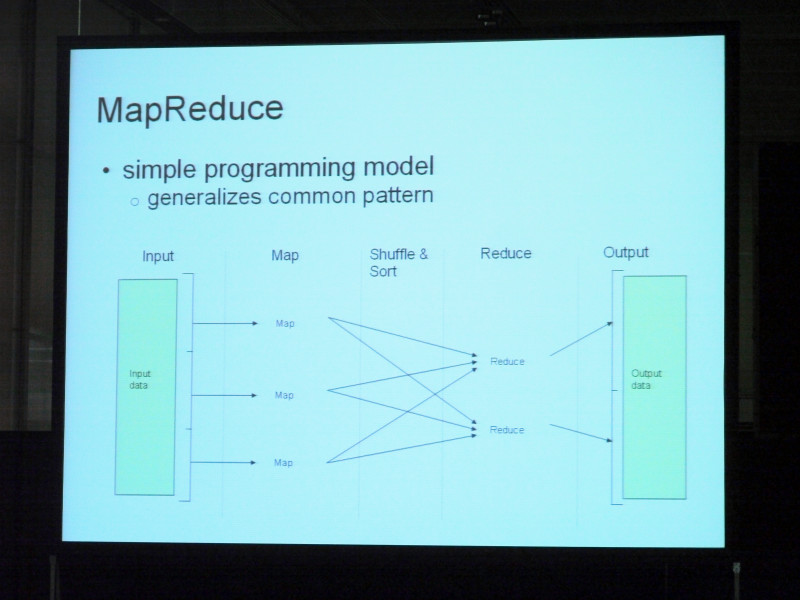
ここでは参考までに3つに分けていますけれど、塊ごとにユーザ定義のマップ関数に引き継がれていきます。そしてこのマップ関数を使いながら各データ、アイテムごとに処理を行って、キー、バリューペアを生成していきます。マップ関数のアウトプットがソートされていきます。マップ関数のアウトプット単位でユーザ定義のレデュース関数の方にどんどん引き継がれていきます。ですから、マップ関数からA、B、Cというキーが生成された場合にはAに相当するものがこちら、Bに相当するものがこちらのレデュース関数の方に引き継がれていく。そしてAペアのものが全てここ、レデュース関数へいっぺんに引き継がれていく。そしてこれを反復的に引き継いで採取的なアウトプットへと到達していきます。プログラミングモデルとしては至って単純で、2名のユーザがアプリケーションコードをマップ関数、レデュース関数に挿入しておいて使うということもできます。実はこういうやり方を使えばありとあらゆる種類ができるということも証明済みです。

大型のクラスタであったとしてもハードウェアを十分にきちんと活用するということが担保される。そしてソート、マージもできますし、これ以外のメタフォに変換された他のアルゴリズムについても対応できます。このMapReduceについてもう2、3点だけ触れておきたいと思います。MapReduceのコンピュートノードというのはHTFSストレージと同じです。同じクラスタ上で実装されていきます。従って、ローカルハードドライブから読み込んでローカルハードドライブに書き込んでいくということができます。そしてそこからクラスタを通してデュプリケーションが可能です。IOはほとんどの場合ローカルで処理できてしまいます。CPUやハードドライブも稼働率を上げながらハードウェアに相当する分だけのスループットが保証されるわけです。ですから数百のハードドライブがあれば、データのプロセス能力も、4000あれば4000分に相当するスピードだということで、かなり目を見張るものがあります。ほとんどのシーケンシャルファイルアクセスを使い、さらにソートマージを直接サポートしています。ソートマージ型のコンピテーションに対応していると。また、3つ目に記したように、期待通りの信頼性、スケーラビリティが自動化されていきます。

MapReduce、HTFSについて簡単に紹介しましたけれど、カーネルだけが使われる場合はほとんどないと言っていいかもしれません。MapReduce、カーネルを中心にいろいろコミュニティが拡大しております。いろんなプロジェクトがあちらこちらの開発者の間で浮上しています。もう既に、他のコンポーネントはどうなのかといったことを謳った書籍も発表されておりますし、有償でいくつかの企業がサポートを提供し始めています。つまり、この下の図のように補完的なツールがどんどんネットワーク的に拡充しています。読みづらいのを承知で紹介しておりますが、MapReduceがちょうどこの中心に来ております。こちらにHDFS。そしてこれを取り囲むような形でのコンポーネント、そしてこの中心、要となるMapReduceとHDFSのお互いの依存関係が読み取れます。実はこの図、1年ほど前のものですので、1年たった今はさらに複雑化しています。ですから管理は難しいかもしれません。このコミュニティの全てを取り込んでいくということは大変かもしれません。例えばLinux、この2つがカーネル、そしてこちらにコンパイラがあったり、Windows系のシステムがあったりとか、あるいはOffice Suiteがあったりとか、まあ、Linuxのディストリビューションを構成するものがその周りを取り囲んでいくという発想と全く同じです。
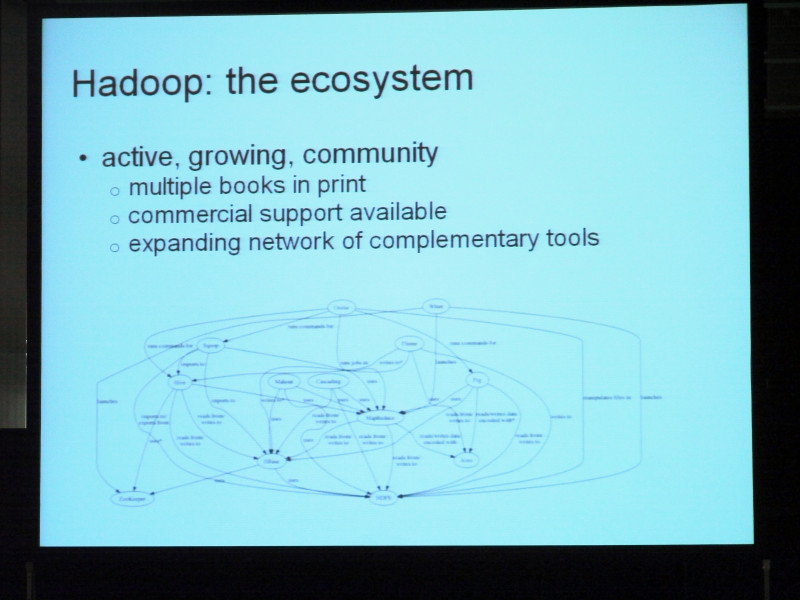
そこでクラウデラ、我々はこのような複雑なコミュニティを何とか簡素化しようとして全部のコンポーネントを皆様が自身で導入しなくてもいいようにパッケージ化して提供しています。そしてクラウデラのディストリビューションということで、かなり使いやすいものを私どもは提案しております。クラウデラのディストリビューションに含まれているコンポーネントは全てオープンソースです。ディストリビューションそのものもオープンソースでフリーです。従って誰でもダウンロードできます。コンポーネントのコンパチブルな標準セットもありますので、クラウデラの新たなるディストリビューションが発表されたとしても、コンポーネントプロジェクトの最新バージョンを取り込んで、そして十分にコンパチブルであるかというテストがされた上で、パッケージ化されてディストリビューションが出来上がり、という経緯をきちんと辿っていますので、コミュニティに対して大きなサービスではないかと思っております。ユーザの皆様がコンポーネントをいちいちインストールするという時間を省くことが可能となっています。

ではこのエコシステム、クラウデラのディストリビューションの、これ以外のコンポーネントについてちょっと触れていきたいと思います。有名なところでPig、Hive。高次でのクエリ言語になりますけれど、MapReduceの生成を行います。Pigはインペラティブデータ言語であるということ、そしてほとんどの場合、ETLのタスク用に使われるので、データセットのトランスフォームに使われることが多いかと思います。一方でHive、こちらはSQLをクエリ言語として採用しています。大体はデータウェアハウス系のアプリケーションに使われているケースが多いかと。データをソートし、そしてHiveを使いながらクエリをかける、といったような使い方が一般的だと思います。

続いて、有名コンポーネントとしてAvro。共通のデータフォーマット、コモンデータフォーマットを提唱しておりますので、いろんなコンポーネントがきちんとコンパチブルで、一つのコンポーネントと他のコンポーネントが違うコンポーネントだったとしてもきちんとお互い認識しあえるということ。スキーマ言語を使っておりますので、データ構造はスキーマ言語を使って表現されています。また、データ構造のエヴァリューションにも対応しておりますので、追加だったり、名義を変えたり消去したりとか、あるいは古いデータセットがそのまま新しいコードであったとしても読み込めるようにもなっておりますし、古いコードであったとしても新しいデータセットを読み込めます。つまり上位、下位の互換性があるということです。それから非常に効率のいいバイナリーコーディングも含まれておりますので、ありとあらゆるデータセットがコンパクトに表現できます。従ってその結果、冗長性をある程度削減するということにも繋がっております。

Avroのファイルフォーマットは自己記述型のファイルになっておりますので、Avroのデータファイルを他の第三者に引き継いだとしても、実際にデータ構造が何なのかということをレファレンスしなくてもきちんと把握できるという仕組みです。また、Avroはリモートプロシージャコール、あるいはRPCシステムにも対応しています。また、例えばJAVA、C、C++、Python、それからRuby、PHP、C#といった言語にも対応しました。それからプリデュースと一緒に使えるということ。プリデュース系のプログラムを簡単に使いながらAvroデータフォーマットに置き換えていくということです。

次のコンポーネントも面白いんですけれど、Mahoutです。このMahoutというのはライブラリ。マシンラーニングのアルゴリズムのライブラリで、例えばクラシフィケーション、クラスタリング、そしてレコメンデーションエンジン、そういったものをサポートします。レコメンデーションをしなくてはいけない、それを自動でしたいという場合にはいくつかレコメンデーションのアルゴリズムがあるのですが、どれが適切なのかということをMahoutからデータにあわせて選んで使えます。このアルゴリズムは大部分はMapReduceで作られています。非常に便利なライブラリです。

それから今度はHBaseです。これはGoogleのビッグテーブルというプロジェクトからインスピレーションを得て始まったものです。

リアルタイムのオンラインデータベースで、HTFSで全てのデータが格納されており、プライマリーキーでアクセスすることもできます。もしくは、非常に効率的なスキャンをデータの範囲に対してかけることもできます。キーでデータはソートされていますので、その順番どおりのスキャンも可能です。それから、HBaseはパフォーマンスが高く、スケーラビリティもあります。そのノードに対する書き込みのスピードでインサートをすることができますし、スキャンも可能です。ハードドライブからの読み込みと同じスピードでソートをすることができます。つまりパフォーマンスも高く、スケーラビリティもあるということです。また、MapReduceと一緒に使うことができます。HBaseテーブルをインプットとしてMapReduceのジョブに適応することができますし、MapReduceのアウトプットを逆にHBaseに対して書き込むということもできます。

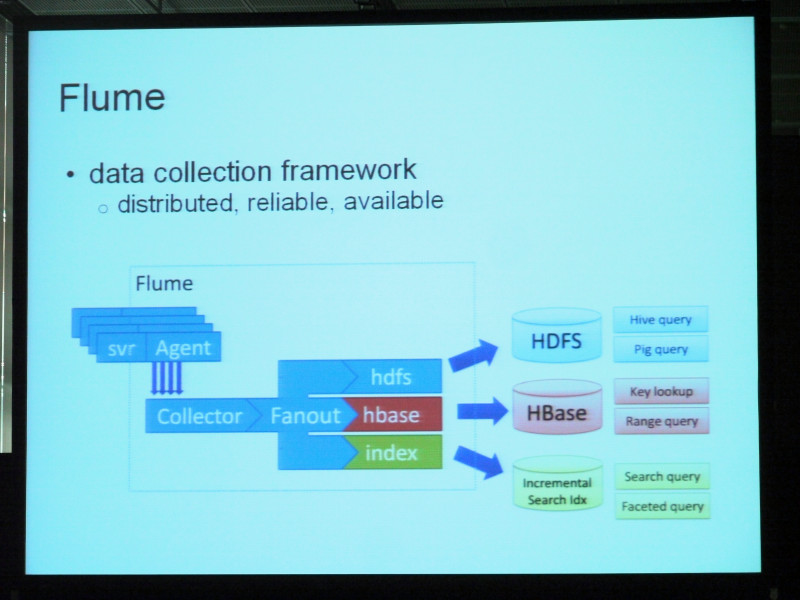
次のコンポーネント、これも面白いです。Flume。これはデータ収集のフレームワーク、データコレクションフレームワークです。信頼性と可用性に焦点を当てています。通常はログデータですし、他のリアルタイムイベントのデータでもいいんですけれど、データを生成するサーバにエージェントを格納してFlumeがそれを共通の箇所に対して伝送していきます。そしてそこで処理をするわけです。よくあるのはHDFSに対してデータを伝送すること。そこからアーカイブのサーチをかけたりするのでPigとかHiveを使うんですが、そうでなければHBaseに伝送することもできます。そうすればオンラインでイベントにアクセスすることが可能になりますし、そうでなければなんらかの検索インデックス、サーチインデックスに送ったり、そこで最近のイベントのトラッキングをしておいて、検索インターフェースでブラウズするということもできます。これらに対し、とにかく一つに対して送ることもできれば、この図にあるように三つに対して送るということも可能になっています。それがFlumeです。
この何年かで私が見てきた限り、「Hadoop」の採用においてパターンがあると思っています。典型的なパターンを言えば、まず「Hadoop」のクラスタをインストールするのは特定のアプリケーションでの話です。そのアプリケーションは他の形で対応できないデータセットが問題を抱えており、例えばデータセットに対してこういう解析をしたいんだけど、他のテクノロジーを使ってみたができなかった、というような場合です。少なくとも経済的にはできないというような場合で「Hadoop」をやってみると。小さなクラスタ、10から20のノードのものを採用してみて、結果として簡単にデータセットの処理ができる、アルゴリズムの実装ができるという発見をするんです。で、その一つのアプリケーションで使い始めます。そうすると、他のデータセットをクラスタに持つことは良いと、しかもこれが効率的にできるということに気付いてデータセットを増やしていくんです。

最終的にはその会社のほとんどのデータをHDFSのファイルシステムに入れることになります。そして、いろいろな解析をすることもできれば、これまでできなかったような実験的な処理もすることができるということを発見していきます。すると多くの社員がこれを使うようになります。つまりデータを縦割りで持っていると一部の社員しか見れないということが起きてしまいますが、そうではなくデータは一箇所にすべてを置いて、みんなが見られるようにするというアプローチです。また、「Hadoop」はセキュリティ性が高いですから、全てのデータに全ての人がアクセスする必要はないんですが、もしそうだとしても可能です。サポートしますし、切り分けてセキュリティをかけ、アクセスを限定することもできます。とにかくこういう形で始めていきます。そしていろんなことを簡単に試せるようになるのです。そういう一つ一つのアイディアを簡単に試し、うまくいけば本当に採用するということです。ここに、Facebookからの引用を載せています。ある人がこんなことを言いました。「たくさんデータがあるから『Hadoop」』使うんじゃない。『Hadoop』を使うからデータがたくさんあるんだ」と。さきほどパターンを説明しましたけれど、ある特定の問題を解決するために「Hadoop」を採用したら、他にもたくさんのデータをサポートすることができると気付いて、増えていくということなんです。たくさんのデータがあればあるほど有益な解析ができるということに気付いてデータが増えていく、こういうパターンを大抵の企業は辿っているはずです。少なくとも私はそれを見てきました。

最後のまとめに入って行きたいと思います。この、パラダイムのアドバンテージについて申し上げておきます。まずコスト効率が高いということ。他のテクノロジーに比べて、「Hadoop」を使えば何オーダーでもデータの格納が安くなると思ってください。他の方法では大きなデータセットを格納できないような場合にも格納できますし、処理も効率的にできます。また、汎用性が高いということもアドバンテージです。非常にパワフルでプログラミングも簡単。特定のモデルとかデータに対する考え方に限定されることがないのでとても柔軟性があり、オプションもたくさんあります。処理のオプションが数多くあるのです。

そして最後のアドバンテージとしては、入りやすい、始めやすいということです。例えば、データベースを最初に設計して、スキーマを作ってからでないとデータの収拾ができないということはありません。データをとにかく生の状態で集め、そしてそれを全部保存してください。それを変換していく必要があれば、後から変換するように薦めています。その場合はデータをいくつかの表現方法で持つ方が良いです。最初から時間をたくさん費やす必要はありません。それをやってしまうと後から使えないデータが大量に発生します。どのデータが使えるかどうかもわからない状態ですから、必要に応じて後でやればいいと考えています。

それでは最後に、今後の話を少ししておきたいと思います。ストレージならびに演算のコストはこれからも下がり続けると思っています。もう何年も前からムーアの法則は正しいということを証明してきました。CPUに加えてハードウェアもメモリも大容量になってきていますし、しかも安くなっています。ですから、より多くのデータを格納し、保存することが経済的にもできるようになって来ています。しかも、より使い勝手のいいデータを収集することが可能です。モニタリングをして、例えばそのイベントのデータのみならず、イベントのコンテキストも含めて経済性のある形で格納しておくということが可能になっています。また、よりデータが多くなるということはそれを回線に繋げていけるということなんです。仕事に関するデータの場合にはビジネスの状態をよりよく理解することが可能になります。

Googleのピーター・ノーヴィックがこう言いました。「Unreasonable Effectiveness of Data」、データの非効率的な有効性とでもいいますか。ようするにたくさんのデータを持ち、シンプルなアルゴリズムにしておいたほうがいいと言うんです。データは、少なくて賢いアルゴリズムを持つよりも、たくさんのデータを持ってアルゴリズムはシンプルなほうがよっぽどいいと言っています。だからアルゴリズムの改善にさほど時間をかける必要はないと、それをやるんだったらよりデータを多く収集しましょうと。アルゴリズムについては、必要なデータが全部集まってからでいいじゃないか、それが一番効率的な解析やデータセットに対する対応の仕方だと彼は言っています。そのほうがより正確に事態の把握ができると。こういったことを全てあわせて考えますと、企業やビジネスは、より多くのデータを集めて解析することによって、改善に繋げることができると思っています。そして新しい分散型データOSのカーネルとして「Hadoop」を使えばまさにこれを実現できるのです。

以上でございます。本日はご静聴ありがとうございました。

・関連記事
Apache/PHP/MySQLなどをWindowsに一発でインストールできる「VertrigoServ」 - GIGAZINE
Apacheを「Ultra Monkey」で高可用性ロードバランスクラスタ化 - GIGAZINE
GIGAZINEが20日(土)から21日(日)にかけて新サーバに移転します - GIGAZINE
GIGAZINEのLoadAverageを「27」から「2」へ下げた方法 - GIGAZINE
Muninをカスタマイズして表示されるグラフの種類を増やしてみる - GIGAZINE
・関連コンテンツ







in ハードウェア, 取材, Posted by darkhorse_log
You can read the machine translated English article The author himself tells the merit and h….