OpenAI announces GeneBench-Pro, a benchmark test to measure the scientific capabilities of AI.

OpenAI has released GeneBench-Pro, a computational biology benchmark that measures whether an AI can analyze data by determining whether it is noise or significant. It is hoped that improving AI based on measurements taken with this benchmark could significantly accelerate scientific discovery.
Introducing GeneBench-Pro | OpenAI
We're introducing GeneBench-Pro, a research-level benchmark for a harder kind of AI progress: how well agents can navigate messy biological data, choose the right analysis path, and make judgment calls that real computational research depends on. https://t.co/AsilnnSxnE
— OpenAI (@OpenAI) June 30, 2026
OpenAI points out that 'scientific data rarely comes with instructions. Researchers must determine whether a pattern reflects a biological phenomenon or is noise, whether the data supports a question, and what to do next based on each result. While AI agents are becoming increasingly capable of performing complex analyses, in real scientific research, it is essential not only to recall facts or follow predefined workflows, but also to make such sophisticated judgments.' GeneBench-Pro is a benchmark test that can measure whether an AI has the ability to make such sophisticated judgments.
GeneBench-Pro is designed to accurately measure higher-order abilities such as correcting assumptions, handling ambiguity, and selecting appropriate analytical pathways, as is done in real-world scientific research. Each problem in GeneBench-Pro includes realistic but disorganized datasets and experimental backgrounds, requiring the AI to explore the data, select appropriate analytical methods, and conduct an iterative experimental process to arrive at the correct answer.
When GeneBench-Pro was tested with actual models, OpenAI's highest-performing model, ' GPT-5.6 Sol, ' achieved a pass rate of 28.7% at the highest inference setting and 31.5% at the top-tier 'Pro' setting. When GeneBench development began, the then-latest model, 'GPT-5,' scored less than 5%, and OpenAI states that 'this shows how rapidly the models are evolving. If the current pace of progress continues, this benchmark could saturate by the end of the year.'
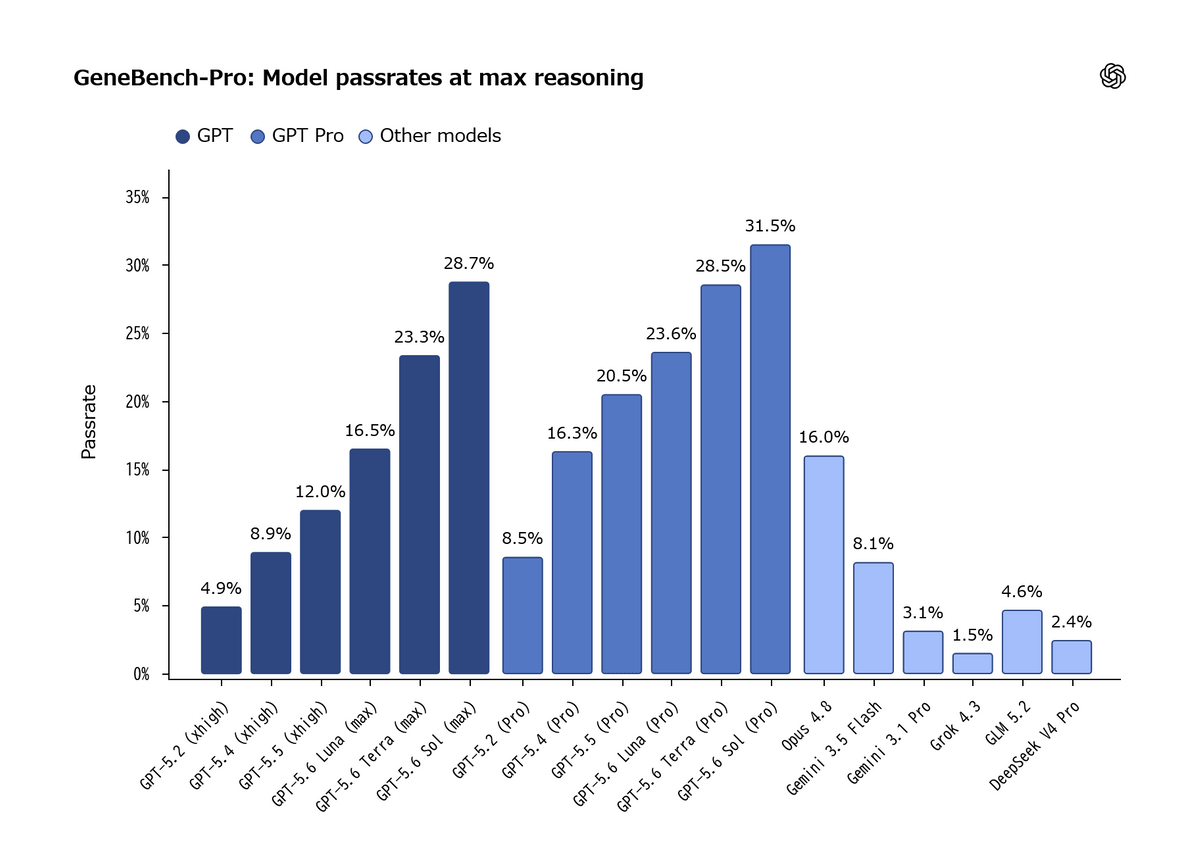
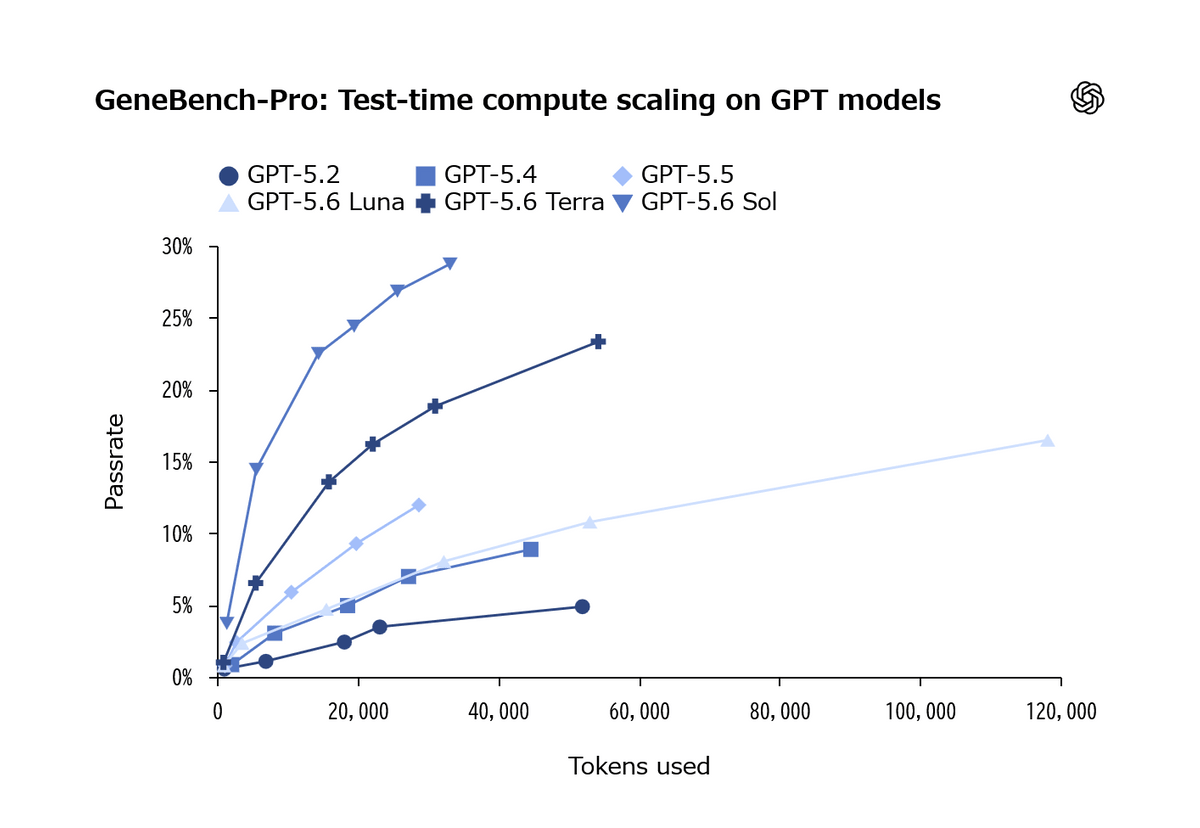
The results also demonstrate the effectiveness of increasing the computational load during testing. At the lowest inference level, the pass rate for GPT-5.6 Sol remained in the single digits, but at the highest inference level, it increased by approximately six times.
OpenAI stated, 'Considering the difficulty of the GeneBench-Pro problems, achieving a GPT-5.6 Sol(Pro) score of 31.5% is highly noteworthy. Human reviewers estimated that it would take a human expert approximately 20 to 40 hours to solve one GeneBench-Pro problem. While current AI agents are not yet reliable enough to replace human experts, their inference costs are significantly lower than labor costs. Even with their current capabilities, partial automation has the potential to generate significant economic and scientific value.'
Nevertheless, OpenAI points out that there is still significant room for improvement, given that even the most advanced models can still solve less than a third of the problems. In particular, they mention that for difficult problems, 'while partial progress can be shown, the inability to complete the inference process entirely is a challenge.'
By identifying where the model is failing, further improvements can be expected, and OpenAI expressed optimism, stating, 'If agents can reliably automate this type of analysis, it could significantly accelerate scientific discovery.'
Related Posts:








in AI, Posted by log1p_kr