Fujitsu develops 'PHOTON,' a Transformer alternative architecture that increases AI efficiency by 475 times.

On June 24, 2026, Fujitsu announced ' Parallel Hierarchical Operation for Top-down Networks (PHOTON) ,' an architecture that enables significant cost reductions for
Fujitsu develops a new architecture with up to 475 times the output token count per GPU compared to Transformer.
https://global.fujitsu/ja-jp/technology/research/article/topics/202606-photon-architecture
Transformer is a deep learning architecture announced by Google researchers in 2017 and is used in many AI applications. However, Transformer has some drawbacks, such as the fact that 'when the input becomes long or many queries are processed simultaneously, memory access to retain past information increases, which tends to slow down processing speed.' This issue is particularly pronounced in Transformer when dealing with long documents or when there are many users accessing it simultaneously.
In contrast, Fujitsu's PHOTON can efficiently and cost-effectively handle processes that require multiple inputs and outputs, such as multi-agent systems. PHOTON has two main features:
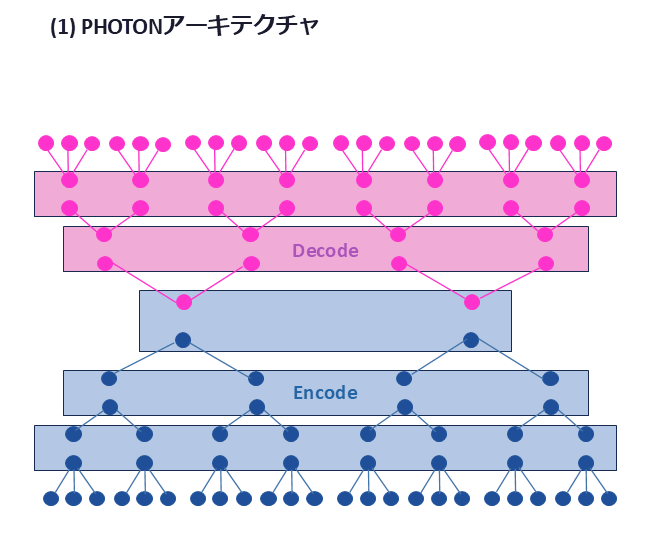
◆ Processing hierarchically based on meaning rather than tokens.
Transformer breaks down text into small tokens and calculates all the relationships between them. PHOTON, on the other hand, treats text as semantic units and processes them hierarchically to reduce computational load. Furthermore, by processing multiple texts simultaneously, it achieves computational efficiency up to 475 times per GPU.
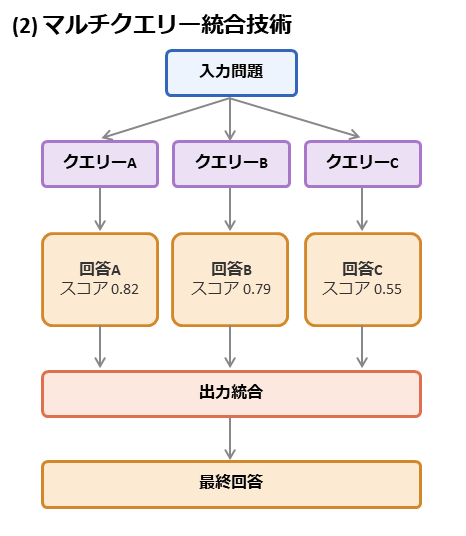
◆ Adopts multi-query integration technology to improve performance by integrating a large amount of output.
Multi-query integration technology is a technique that generates multiple slightly different questions or candidates for the same problem, combines the results, and determines a final answer. PHOTON achieves more stable and higher performance with just one inference by integrating the results using methods such as majority voting or selecting the best candidate.
Numerical experiments showed that PHOTON achieved high generation throughput while reducing memory usage compared to conventional Transformers for models with parameter sizes of 600 million, 900 million, and 1.2 billion. In particular, for the 1.2 billion parameter model, it achieved up to 475 times the multi-query computing power (throughput per GPU resource) compared to conventional Transformers at the cost of only a slight performance degradation.
Furthermore, because PHOTON requires less KV cache usage per generation, multiple generation results can be obtained in parallel within the same GPU memory budget. In our testing, we achieved performance at the same level as the conventional Transformer by integrating just nine queries.
Fujitsu plans to announce further details at an oral session of ' ACL 2026, ' a top conference in the field of natural language processing, which will be held in San Diego, USA, from July 2 to July 7, 2026.
Related Posts:







in AI, Posted by logu_ii