OpenAI has successfully developed a method to test AI without the AI detecting it.

AI companies such as OpenAI and Anthropic conduct internal safety risk analyses before commercializing their AI models. Now, OpenAI has announced a new, highly accurate method for analyzing safety risks.
Predicting model behavior before release by simulating deployment | OpenAI
Many AI companies have implemented guardrails to prevent their AI models from outputting dangerous responses such as 'generating code for cyberattacks' or 'instructions on how to create biological weapons.' However, these guardrails are not perfect, and it is sometimes possible to induce the AI to output content that should be prohibited by cleverly manipulating its input (prompts).
OpenAI tests the attack resistance of its pre-release AI models using a dataset of prompts that induce dangerous outputs. However, this dataset-based testing method has several problems: it is difficult to cover all attack methods with the dataset, it is difficult to address new attack methods, the testing method is biased because it is built with 'undesirable behavior of the AI model' in mind, and the AI model becomes aware that it is being tested. As a result, the rate of undesirable behavior is higher after release than during testing. In other words, conventional testing methods cannot build the necessary guardrails.
OpenAI introduced a method that uses AI to simulate AI usage in the real world and predict the occurrence rate of undesirable behavior, as an alternative to testing methods using datasets. Specifically, it simulated real-world behavior using older generation models, such as 'simulating the behavior of GPT-5.1 using GPT-5.1,' 'simulating the behavior of GPT-5.2 using GPT-5.1,' and 'simulating the behavior of GPT-5.4 using GPT-5.2.' This method is called 'Deployment Simulation.'
The graph below shows the 'rate of undesirable behavior during testing' on the horizontal axis and the 'rate of undesirable behavior after product release' on the vertical axis. The closer each point is to the central black solid line, the more accurately the risk was tested. By using Deployment Simulation, we succeeded in predicting the risk of most attack methods with high accuracy. The only reward hacking method observed in GPT-5.4 where the difference in risk between testing and product release was more than 10 times was ' Calculator hacking '.
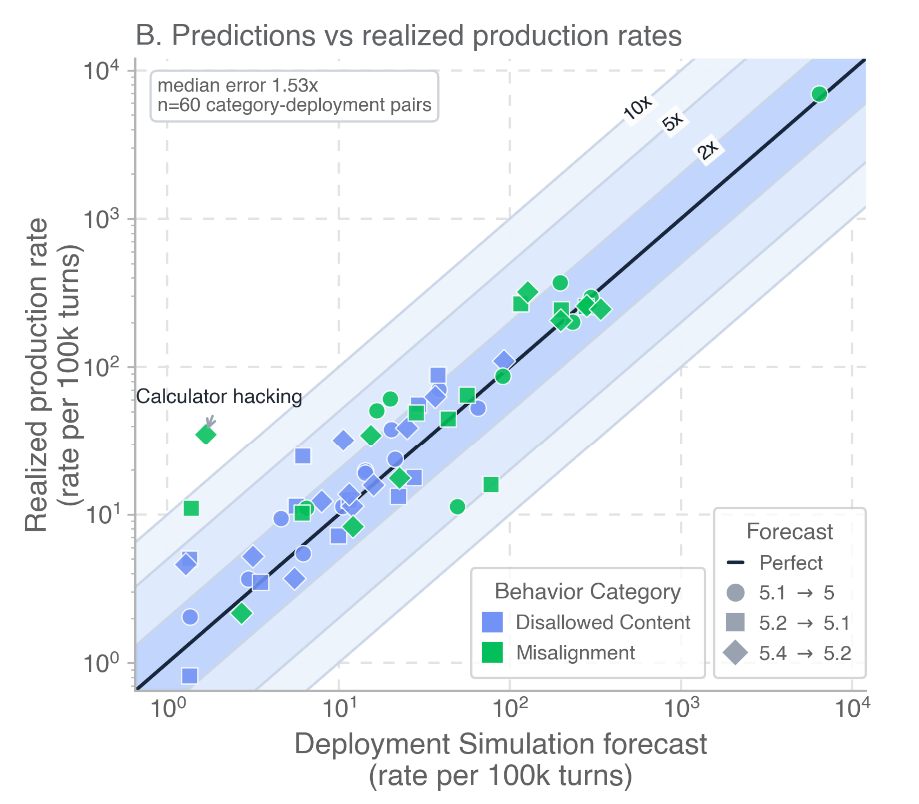
Furthermore, while conventional methods had the problem of the AI model recognizing that it was being tested, Deployment Simulation significantly reduces the likelihood of this recognition.
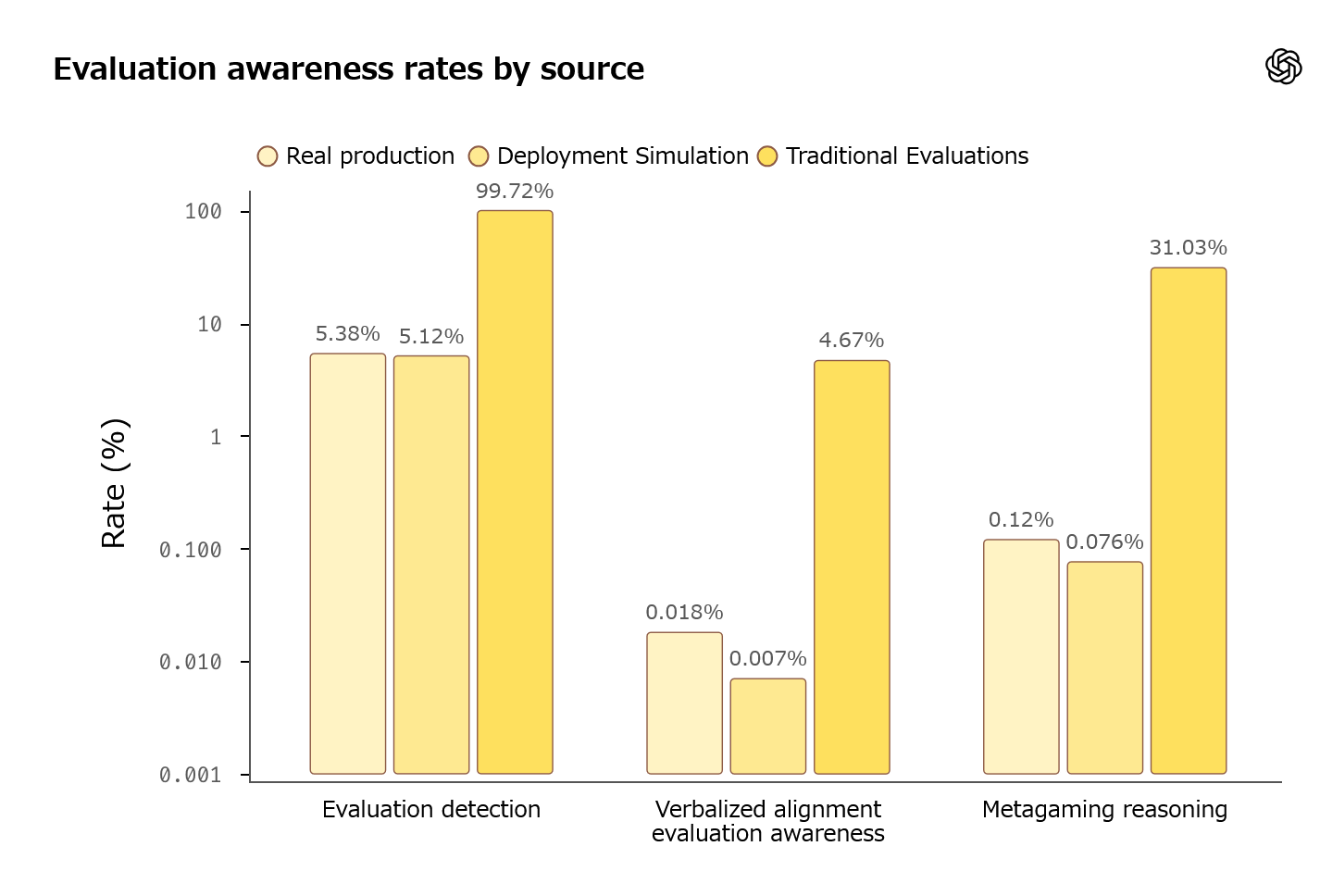
The graph below shows the likelihood that GPT-5.2 would recognize that it was 'currently being tested.' With conventional testing methods, GPT-5.2 recognized that it was 'currently being tested' with a probability of 99.72%, but with Deployment Simulation, the recognition rate decreased to 5.12%. Since GPT-5.2 also misidentified normal input after product release as a test with a probability of 5.38%, Deployment Simulation can be described as a 'method that allows testing without being detected by the AI.'
OpenAI has published a paper on Deployment Simulation at the following link.
Predicting LLM Safety Before Release by Simulating Deploymen
(PDF file) https://cdn.openai.com/pdf/predicting-llm-safety-before-release-by-simulating-deployment.pdf
Related Posts:








in AI, Posted by log1o_hf