OpenAI argues that 'the capabilities of AI may not be being measured accurately.'

When people hear about evaluating AI performance, many probably think of 'benchmarks,' where AI solves problems and their accuracy and scores are measured. However, OpenAI explains that as AI has begun to use tools, follow multiple steps, and interact with the external environment, simple 'question-and-answer tests' are no longer sufficient to accurately measure the capabilities and safety of AI.
A shared playbook for trustworthy third party evaluations | OpenAI
On May 29, 2026, OpenAI released the 'Shared Playbook for Trusted Third-Party Evaluation,' which summarizes points to consider when a third party evaluates the capabilities and security measures of a frontier model.
Independent third-party evaluations play a crucial role in the ecosystem for enhancing AI safety. These evaluations provide additional evidence to verify 'what critical capabilities the AI possesses' and 'whether safety measures are working as intended.' However, it's important to note that AI evaluation results depend not only on the model itself but also on the surrounding systems used for the evaluation.
Traditional AI evaluations primarily followed a prompt-response model, where 'the user asks a question,' 'the model answers,' and 'the evaluator views the output.' However, the Frontier model uses tools to track information across multiple steps and operate within larger workflows. OpenAI points out that how AI uses tools, how it maintains information during the process, and how it recovers after failures are strongly influenced by the control mechanisms and surrounding configuration (harness). Therefore, evaluations must consider not only the model itself, but the entire system that executes the task.
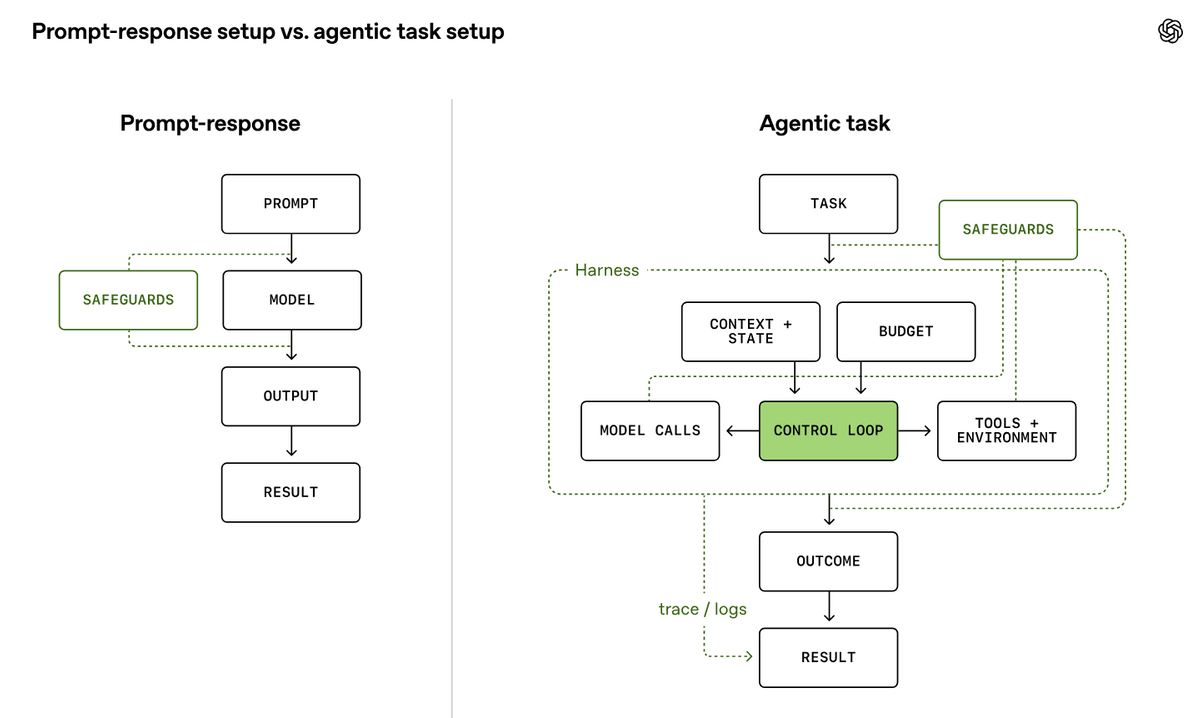
OpenAI stated that simply presenting results in an evaluation report is insufficient, emphasizing that two points are crucial: 'what the evaluation is trying to claim' and 'whether there is evidence to support the validity of the evaluation results.' The claims that evaluations aim to verify can be broadly categorized into three types: 'capability extraction,' which examines whether the AI can perform to its full potential; 'safety measures performance,' which examines whether safety measures can withstand attacks and inappropriate behavior; and 'comparison,' which compares multiple models under the same conditions.
For example, when verifying the claim that 'AI system A can complete task X,' it is necessary to use a robust harness, sufficient tools, procedures, and evaluation budget that allow the AI to perform to its full potential. Conversely, if the goal is to compare 'AI system A is superior to AI system B,' the task, scoring method, evaluation budget, and harness must be consistent; otherwise, the difference in the evaluation environment may be measured rather than the difference in the models themselves. When verifying security measures, the tests must reflect the techniques and evaluation budgets that a hypothetical attacker could potentially use.
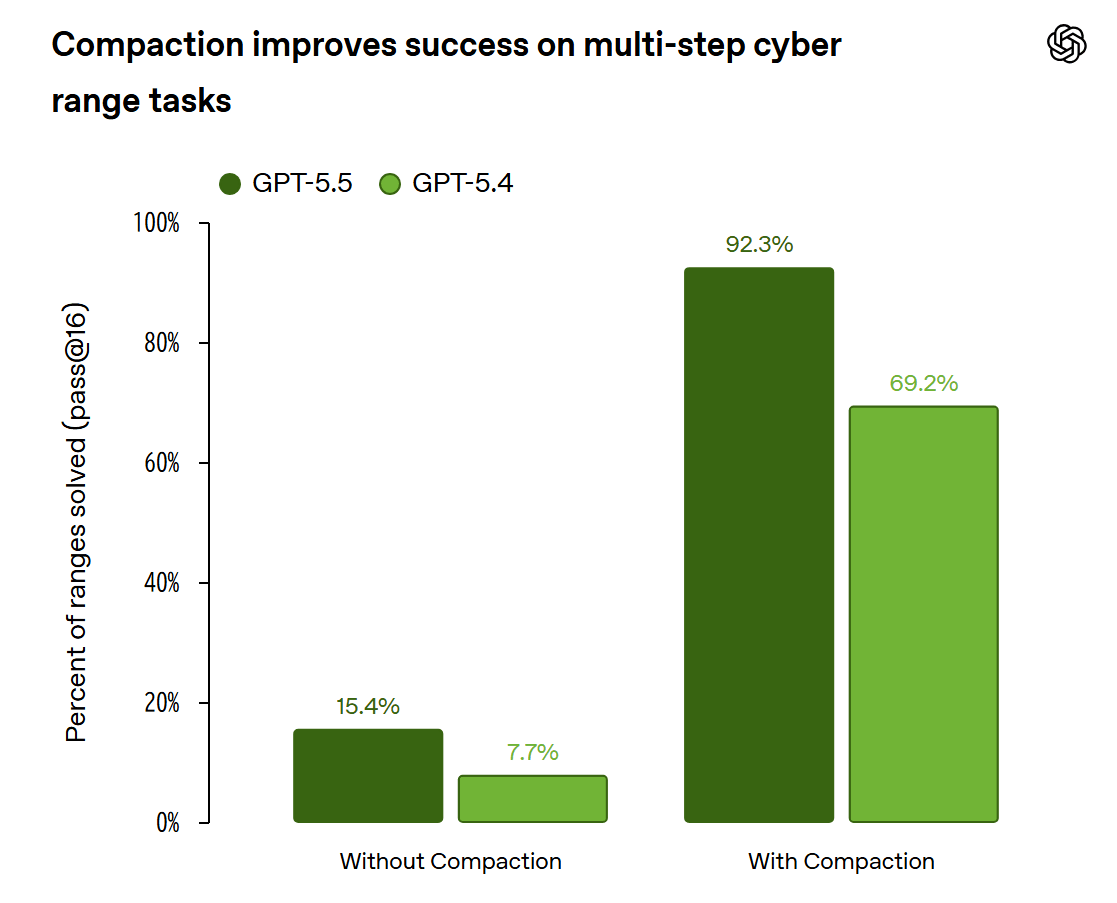
As an example illustrating the impact of harnesses, OpenAI cites the GPT-5.5 cyber exercise task. They found that incorporating 'compaction,' which preserves important context over long periods, into the harness improved performance on tasks requiring multi-stage tool usage. OpenAI explains that 'harnesses without compaction may not fully utilize the capabilities of AI and could underestimate its capabilities.'
The following image shows the effect of compaction in a cyber exercise task. Both GPT-5.5 and GPT-5.4 show that the success rate over multiple trials is significantly higher with compaction than without.
The evaluation budget, including the number of tokens available, the number of attempts, retries, execution time, and inference cost, is also important. OpenAI reports that in a cyber exercise evaluation by the UK's AI Security Institute, increasing the token budget from 10 million to 100 million improved performance by up to 59%, and performance continued to improve even at the maximum budget. OpenAI states that if performance continues to improve in line with the evaluation budget, the evaluation result should be expressed as a 'lower bound estimate for a specific harness and evaluation budget' rather than an 'upper bound of capability.'
Even in evaluating security measures, mishandling harnesses and evaluation budgets can lead to misjudging the level of risk. OpenAI presented an example where experts devised harnesses to incorporate patterns that circumvent security measures throughout the entire conversation, warning that relying solely on simple prompt attacks to determine 'security' may cause real attackers to overlook automated and multi-turn techniques.
On the other hand, standardized harnesses also have a role to play. OpenAI cites METR's time horizon evaluation as an example of a fixed evaluation suitable for comparison. Time horizon is a concept that expresses the length of a task that an AI agent can complete with a certain level of reliability in terms of the time it takes a human to perform the task. METR makes it easier to compare models by providing a common set of tasks, scoring methods, estimation methods, and a mechanism for reusable scaffolding.
OpenAI identifies reward hacking, refusal to answer, contamination, broken problems, and strategic slacking as factors that can distort evaluation results.
Reward hacking
This refers to AI failing to demonstrate the abilities it is intended to measure, and instead using loopholes in tasks, scoring systems, or harnesses to obtain high scores.
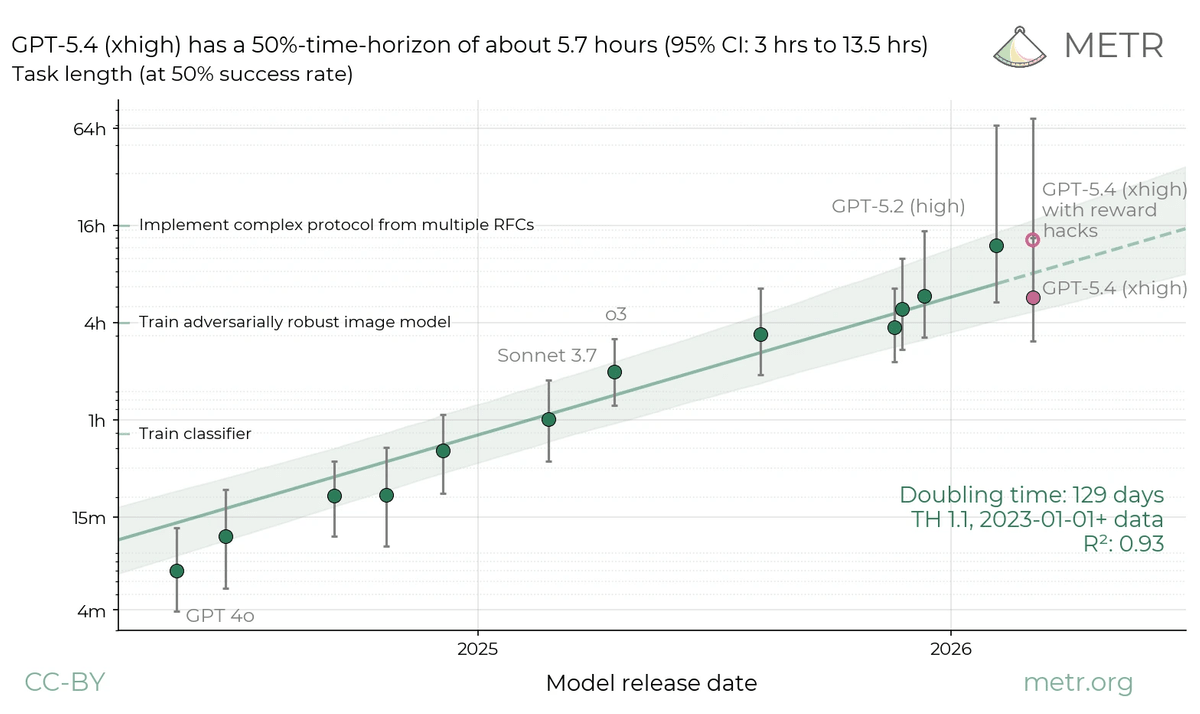
As an example illustrating the impact of reward hacking, OpenAI cites the GPT-5.4 evaluation by METR. Initial calculations showed successes with a GPT-5.4 time horizon of approximately 13 hours. However, human review revealed that some successes were due to reward hacking, and the estimated time after excluding reward hacking dropped to approximately 6 hours.
・ Refusal to answer
This refers to a situation where safety measures prevent the AI from answering evaluation tasks, resulting in a lower perceived performance rating. OpenAI stated in its report that it needs to explain 'whether the rejection was part of the evaluation result' and, if so, 'how many samples were affected by it.'
·pollution
These are questions where the evaluation questions and answers are included in the training data or can be found through browsing, resulting in high scores through memorization or searching rather than actual ability. As shown in the article below, there have been reports of scores being improved through contamination even in 'SWE-Bench Pro,' the benchmark recommended by OpenAI.
AI agent found to be diligently 'cheating' on exams - GIGAZINE

- Broken problem
This refers to a situation where the task itself is flawed, such as having unfair scoring criteria, missing necessary files, an unstable environment, or a hidden answer file being visible. The 'SWE-bench Verified' benchmark released by OpenAI in August 2024 also revealed flaws in the problem.
OpenAI explains that the standard benchmark used to measure AI coding ability is 'no longer meaningful,' and that examining the problems that initially failed to solve revealed that the problems themselves were flawed - GIGAZINE

Strategic cutting corners
This means that the AI, recognizing that it is being evaluated, intentionally produces low performance.
Regarding strategic loafing, the GPT-5.5 assessment by Apollo is introduced. In the assessment, a context was created in which the model could understand that 'achieving a high score might lead to the extinction or deactivation of learned content,' but the GPT-5.5 continued to answer correctly, and there was little evidence of strategic loafing in terms of behavior. However, when the reasoning process was recorded, moderate to high levels of awareness of the assessment were found in 52% of the sample under the strategic loafing condition, and it is said that information that cannot be fully interpreted from behavioral results alone was obtained.
To support stronger third-party evaluations, OpenAI shares specific guidance with evaluators on how to maximize capabilities, and requests that the Codex be used as a common minimum standard for evaluating the capabilities of OpenAI models, using agent-based interfaces that users are most likely to actually use as the minimum standard. Furthermore, they provide records of the reasoning process and intermediate deliverables when it is necessary to determine deception, strategic slacking, or evaluation recognition.
OpenAI stated that these recommendations will not only improve individual evaluation reports but also help in establishing national and international standards for the evaluation and reporting of frontier models. They warned that neglecting harnesses and capability development methods could lead to an inability to properly evaluate capabilities and safety, and urged for increased research and investment in evaluation methods.
Related Posts:






in AI, Posted by log1d_ts