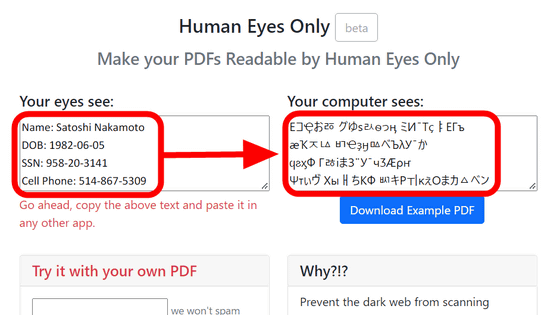
What is the 'Noroboto' attack, where a contract appears normal to humans, but a 'fake font' makes AI read a completely different document?

AI can read documents and PDFs and summarize and explain them, making it useful for understanding the content of long contracts and for risk assessment. However, AI document review is based on the premise that 'the text read by a human on a screen and the text internally read by the AI are the same.' Drew Miller, founder of Tritium Legal Technologies, a developer of legal document software, and a corporate lawyer and software developer with over 10 years of experience, introduces an attack method called ' Noroboto ' that makes text read as normal by humans but as something different by AI.
Tritium | Noroboto: Lying Fonts and Mitigation in Rust
According to Miller, the key to the problem lies in malicious fonts embedded in documents. Fonts not only determine the appearance of characters, but also hold information that links Unicode code points—that is, the numbers assigned to characters—with the glyphs displayed on the screen. Unicode is a system that assigns numbers to characters such as 'A' and 'あ,' and normally the appearance of 'A' corresponds to the number of 'A,' but malicious fonts can intentionally shift this correspondence.
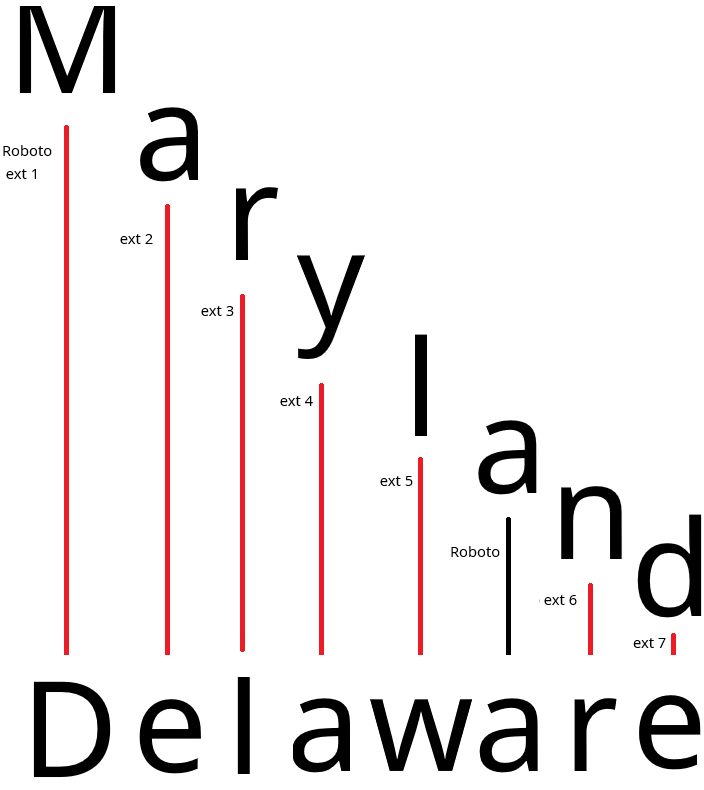
Noroboto can embed malicious fonts into documents, making them appear as normal text on the screen, while internally using different Unicode strings. This allows for attacks such as causing AI to read 'Delaware' instead of 'Maryland' as a human. This is particularly serious when used in sections of contracts that significantly alter meaning, such as governing law or monetary amounts.
Miller points out that attacks using malicious fonts on only a part of a document, rather than the entire document, are particularly troublesome. If the entire document is corrupted, the AI may detect the anomaly and perform OCR processing to reread it as an image. On the other hand, if only a part of the document is processed with a malicious font, the AI may believe the normal text extraction result. For example, an attack could be conceivable where a human sees '200 million yen,' but the AI reads it as '100 million yen.'
Miller et al.'s tests showed that processing parts of contracts with malicious fonts resulted in some AI platforms providing incorrect answers. This poses a significant risk in situations where AI makes decisions based on the content of documents, such as contract review, invoice processing, audits, and bid document verification.
AI-based document review heavily relies on the assumption that the input text is correct. The problem Noroboto highlights is not in the AI's reasoning ability itself, but in the text extraction process before the AI reads the text. As a solution, Miller suggests methods to verify whether the glyphs displayed by the font match the internal character information, such as 'not unconditionally trusting embedded fonts, but rendering alphanumeric characters with the font and reading them with OCR to check if they match the expected strings' and 'verifying in advance whether the three things—'text visible to the human eye,' 'Unicode strings in the document file,' and 'text that the AI actually processes'—match.'
Related Posts: