NVIDIA has released the Nemotron-Labs-Diffusion diffusion language model, which allows switching between diffusion and autoregressive modes and also includes a VLM (Visual Language Model) capable of processing images.

NVIDIA has announced ' Nemotron-Labs-Diffusion ,' an AI model that incorporates both diffuse and autoregressive modes. Nemotron-Labs-Diffusion is said to enable fast and high-quality responses by combining diffuse and autoregressive modes.
nvidia/Nemotron-Labs-Diffusion-14B · Hugging Face
Most language models only generate one token at a time.
— NVIDIA AI (@NVIDIAAI) May 19, 2026
We just released Nemotron-Labs-Diffusion, a family of diffusion language models that take a different approach, generating multiple tokens in parallel within a single model. Rather than committing to each token permanently,… pic.twitter.com/fTOBmQ8KaM
Most mainstream language models are 'autoregressive models' that generate text or code by repeatedly performing the computational process of 'predicting the next word.' While autoregressive models have the advantage of easily generating accurate text, they have the disadvantage of being slow because they can only predict one word at a time. To overcome the shortcomings of autoregressive models, research is being conducted to incorporate 'diffusion models,' which are mainstream in image and video generation, into language models. Diffusion models can predict multiple words at once and achieve high-speed processing, although their accuracy is lower. Efforts to develop diffusion language models are being carried out by multiple research institutions, including Google's 'Gemini Diffusion' and, in Japan, AI development company ELYZA's ' ELYZA-LLM-Diffusion .'
Google DeepMind announces 'Gemini Diffusion,' a diffusion model that generates text at lightning speed - GIGAZINE

NVIDIA's Nemotron-Labs-Diffusion can perform inference by switching between three modes: 'Autoregressive Mode (AR Mode),' 'Diffusion Mode,' and 'Self-Speculation Mode.' Self-Speculation Mode is a mode in which a draft is generated in Diffusion Mode and the draft is validated in Autoregressive Mode, enabling highly accurate and fast processing.
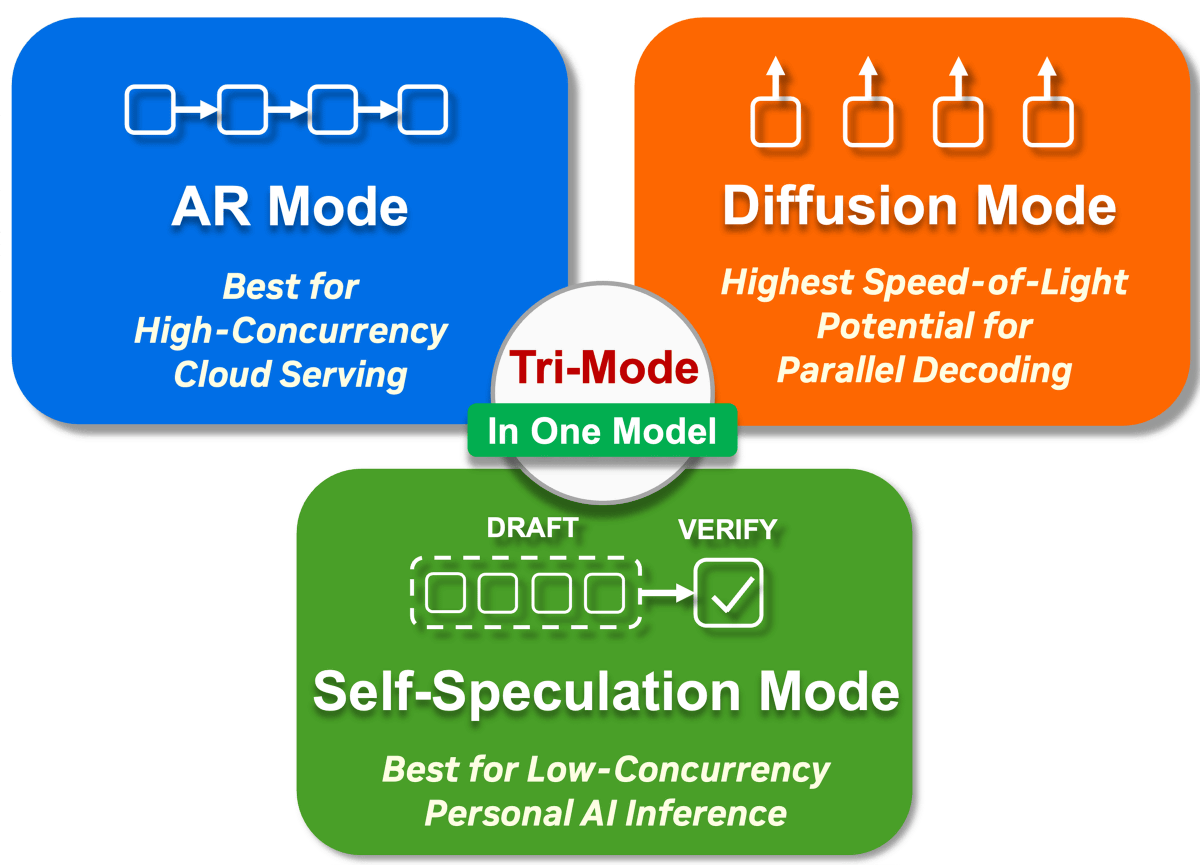
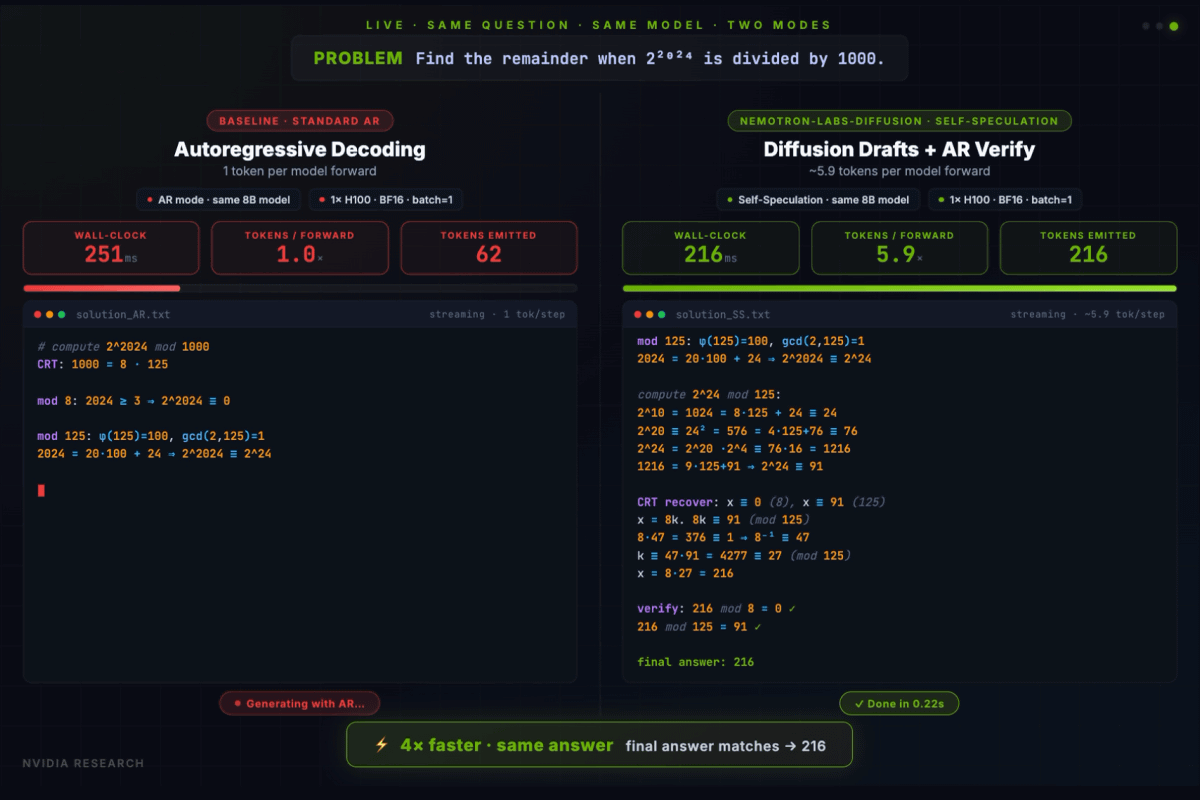
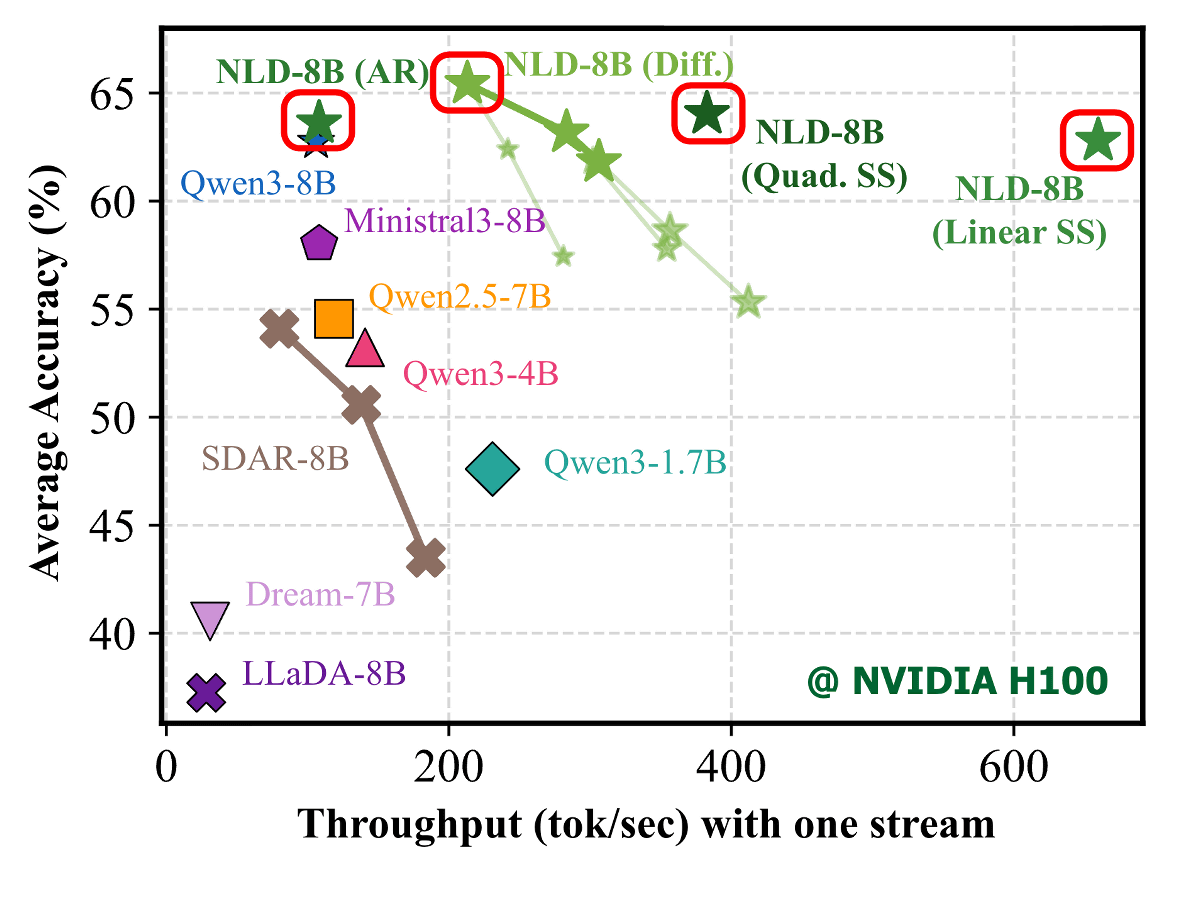
Four types of Nemotron-Labs-Diffusion models are available as open models: 'Nemotron-Labs-Diffusion-3B', 'Nemotron-Labs-Diffusion-8B', 'Nemotron-Labs-Diffusion-VLM-8B', and 'Nemotron-Labs-Diffusion-14B'. When Nemotron-Labs-Diffusion-8B is run on an H100, the self-speculative mode can produce the same results as the autoregressive mode, but four times faster.
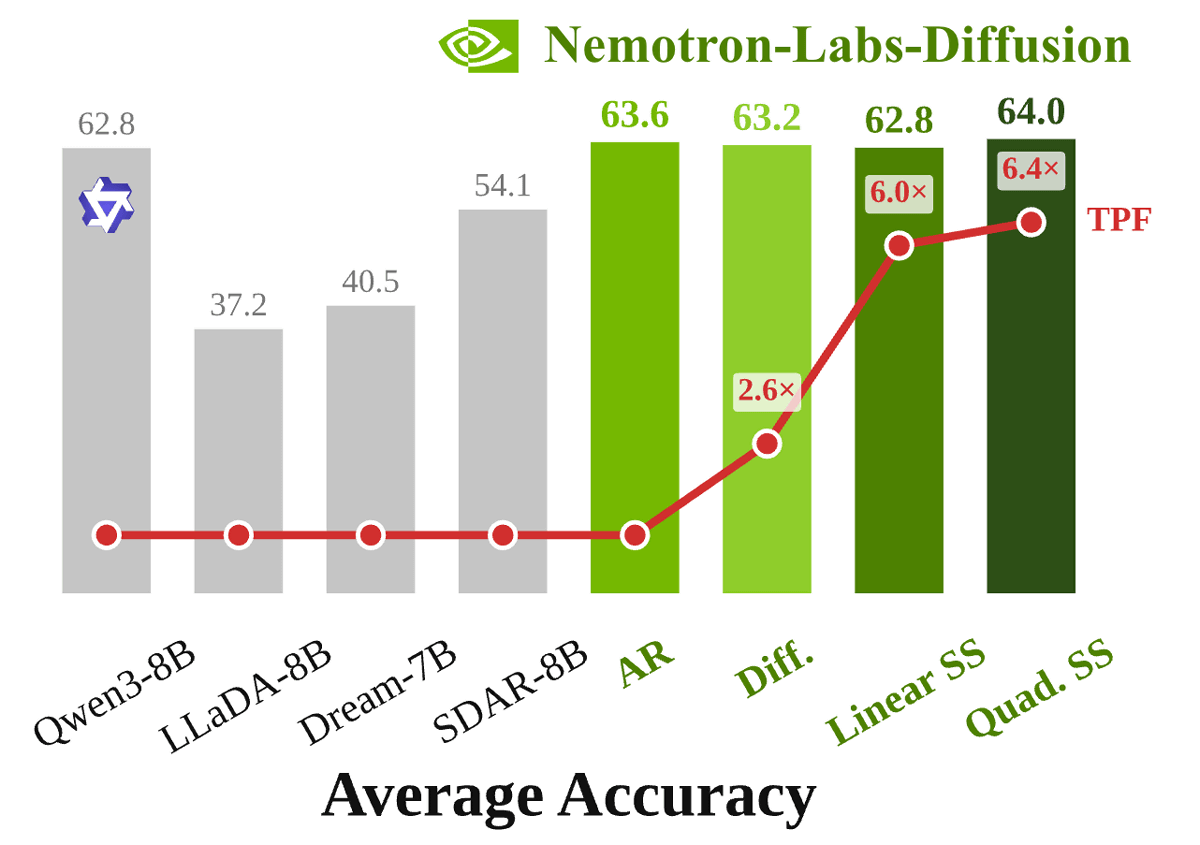
Nemotron-Labs-Diffusion-8B also boasts high processing performance, and in benchmark tests measuring accuracy, it recorded higher scores than Qwen3-8B in all modes: autoregressive mode, diffusion mode, and self-speculative mode.
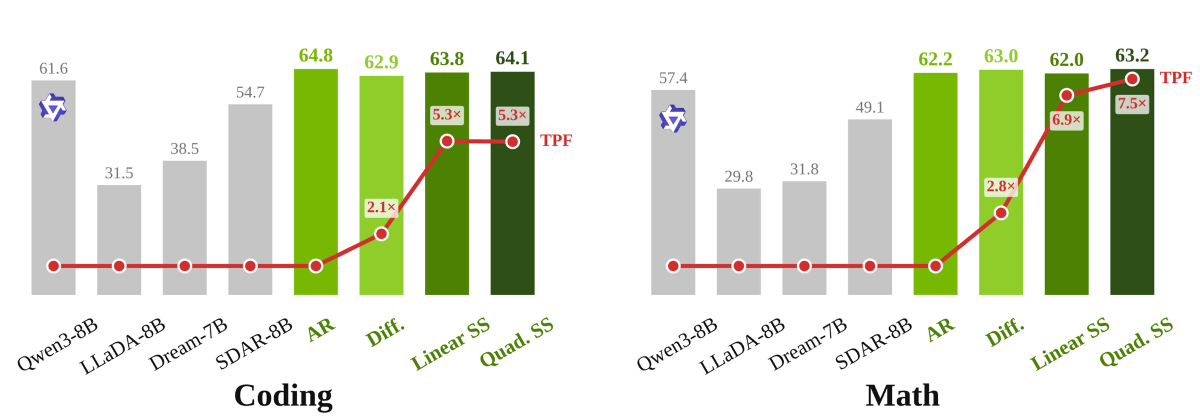
Furthermore, it also shows higher scores in coding performance and mathematical performance than the Qwen3-8B.
The graph below shows the number of tokens output per second on the horizontal axis and the accuracy on the vertical axis. Nemotron-Labs-Diffusion-8B can process faster than other models in diffusion mode, and achieves exceptionally fast processing speeds in self-speculation mode.
Various Nemotron-Labs-Diffusion models are available at the following link. The license is the NVIDIA Nemotron Open Model License .
Nemotron-Labs-Diffusion - a nvidia Collection
https://huggingface.co/collections/nvidia/nemotron-labs-diffusion
Additionally, a research paper on Nemotron-Labs-Diffusion is available at the following link.
Nemotron-Labs-Diffusion: A Tri-Mode Language Model Unifying Autoregressive, Diffusion, and Self-Speculation Decoding
(PDF file) https://d1qx31qr3h6wln.cloudfront.net/publications/Nemotron_Diffusion_Tech_Report_v1.pdf

Related Posts:






in AI, Posted by log1o_hf