This is what happens when you have the Gemini 3.1 Pro or Qwen3.6-35B-A3B perform the AI benchmark 'Draw a pelican riding a bicycle'.
There are various benchmarks for measuring AI performance, but one that's a little unusual is the 'draw a pelican riding a bicycle' test used by software developer Simon Willison. In a 5-minute lightning talk at PyCon US 2026, Willison reported on the results of generating a 'pelican riding a bicycle' using Gemini 3.1 Pro and Qwen3.6-35B-A3B, among others.
The last six months in LLMs in five minutes
The following is the content of the 'Pelican on a Bicycle' benchmark compiled by Mr. Wilson in June 2025.
This is what happens when you have Llama 3.3 70B and GPT 4.1 perform the AI benchmark 'Draw a pelican riding a bicycle' - GIGAZINE

Since June 2025, Mr. Wilson has continued to individually test each new model by having it draw a 'pelican on a bicycle,' but in this lecture, he specifically identifies November 2025 as an 'inflection point' and looks back on the changes that occurred in the six months from then until May 2026.
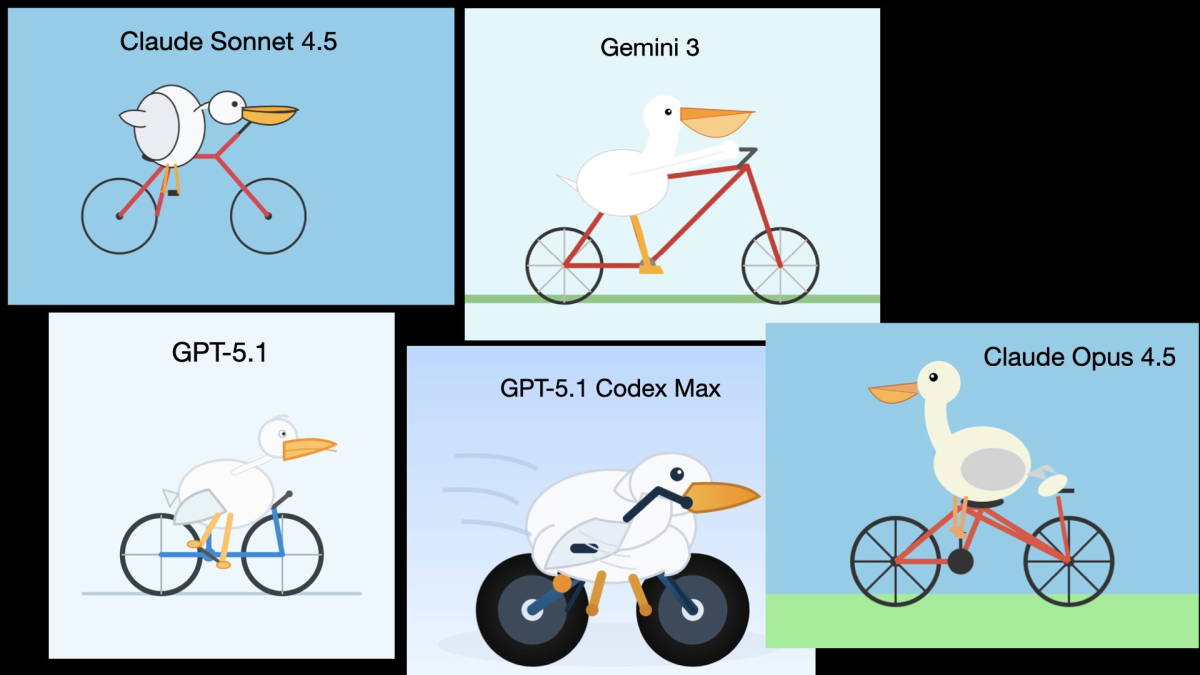
As of early November 2025, the widely accepted 'best' GPT standard was Claude Sonnet 4.5 , released by Anthropic on September 29, 2025. Subsequently, OpenAI's GPT-5.1 , Google's Gemini 3 , GPT-5.1 Codex Max for coding, and Anthropic's Claude Opus 4.5 all gained attention.
The images below show the results of generating SVGs of 'pelicans riding bicycles' using these models. While the relationship between the pelican and the bicycle is somewhat distorted in Claude Sonnet 4.5 and GPT-5.1, Gemini 3 depicts the pelican riding the bicycle quite naturally, and Mr. Wilson states that 'Gemini 3 drew the best pelican among these.'
In February 2026, the Gemini 3.1 Pro , an improved version of the Gemini 3 Pro, was released. When Mr. Wilson had it draw a pelican riding a bicycle, the relationship between the pelican and the bicycle became quite natural. On the other hand, in this example output, a fish that was not instructed to be included was also drawn in the bicycle basket.

The Gemma 4 series, released by Google in April 2026, is a line of open-weight models. Mr. Wilson described the Gemma 4 as 'the most powerful open-weight model I've seen released by an American company.' The Gemma 4 26B-A4B is a 17.99GB model and is able to draw a pelican on a bicycle to some extent. However, the shape of the bicycle is somewhat distorted, and the pelican appears to be standing on top of the bicycle rather than straddling it.

GLM, a Chinese AI research institute, has released GLM-5.1 . GLM-5.1 is a massive open-weight model with 754 billion parameters and 1.51 TB of data. While Mr. Wilson praises it as a high-performance model, he notes that it requires substantial hardware to run. The pelican generated by GLM-5.1 is perched neatly on a bicycle, and the background and wheels are rendered with remarkable realism.

On the other hand, when we tried to animate that image, the bicycle bounced up and its shape became distorted. It's clear that even though it looks good as a still image, there are still unstable aspects when it comes to movement.

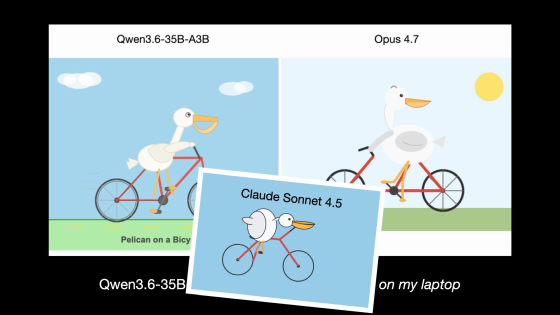
The Qwen3.6-35B-A3B from Qwen is also cited as a notable example. The Qwen3.6-35B-A3B is a 35B class openweight model, and Wilson says that because its file size is small at 20.9GB, it was able to run on his own laptop.
When the Qwen3.6-35B-A3B was asked to draw a pelican riding a bicycle, it produced a more natural image than the Claude Opus 4.7, a higher-end Anthropic model released in April 2026. In the comparison images below, you can see that the Qwen3.6-35B-A3B better depicts the relationship between the pelican and the bicycle, while the Claude Opus 4.7 distorts the bicycle frame.
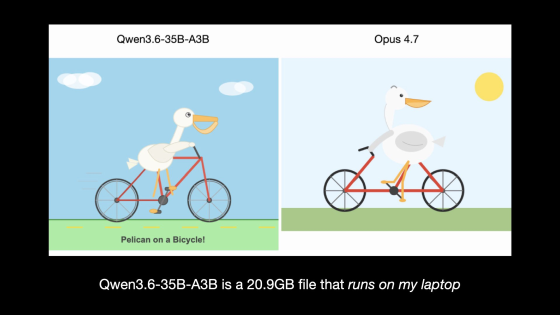
Furthermore, here's a comparison with a pelican image drawn by the Claude Sonnet 4.5 in September 2025. While the pelican and bicycle in the Claude Sonnet 4.5 image are still quite awkward, the quality of the Qwen 3.6-35B-A3B image is significantly higher.
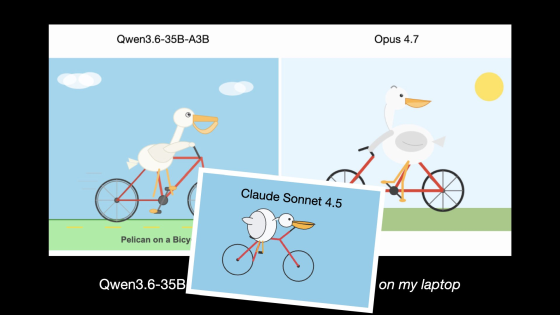
However, Wilson added that this result 'does not indicate that the Qwen3.6-35B-A3B is superior to the Claude Opus 4.7 overall, but rather that the test of drawing a pelican on a bicycle has exceeded its limits as a useful benchmark.'
Related Posts:







in AI, Posted by log1b_ok