Anthropic has released 'BioMysteryBench,' a benchmark for bioinformatics, and Mythos has solved approximately 30% of problems that humans were unable to solve.
Anthropic, the developer of the AI model 'Claude,' has announced ' BioMysteryBench ,' a benchmark for measuring the capabilities of AI in the field of
Evaluating Claude's bioinformatics research capabilities with BioMysteryBench \ Anthropic
https://www.anthropic.com/research/Evaluating-Claude-For-Bioinformatics-With-BioMysteryBench
Anthropic points out that 'While there are exams to become a doctor or a lawyer, there are no exams to become a scientist. The same problem applies to AI, and there is no standard benchmark in the scientific field as there is in software, such as 'SWE-bench.' This is because scientific research, especially biology, has several characteristics that make it very difficult to evaluate using benchmarks.'
In particular, unlike mathematics, biology often has multiple 'correct methods,' individual research judgments are highly subjective, and noisy datasets can lead to completely different conclusions. Furthermore, there are many biological questions that humans have yet to answer, highlighting the challenges in this field. Therefore, there was a need for a benchmark that could effectively evaluate the performance of AI.

BioMysteryBench is a benchmark that uses complex real-world bioinformatics data while ensuring that the inherent complexity and challenges of that data do not detract from the quality of the evaluation. It allows for research freedom and creativity, and AI can choose diverse strategies to solve problems. Furthermore, the evaluation is based on the final answer rather than the path the model took, and a high score is given if the model reaches the correct biological conclusion. This allows for cross-sectional testing of multiple aspects, such as whether the model's conclusions align with those of scientists, and whether the model can devise creative solutions.
BioMysteryBench consists of 99 problems from various fields of bioinformatics, some of which, despite having objectively correct answers, are difficult or impossible for humans to solve on their own.
Anthropic had up to five experts answer each problem. If at least one person answered correctly, the problem was considered solvable by humans.
Out of 99 questions, humans were able to answer 76 correctly. When these questions were attempted by multiple AI models,
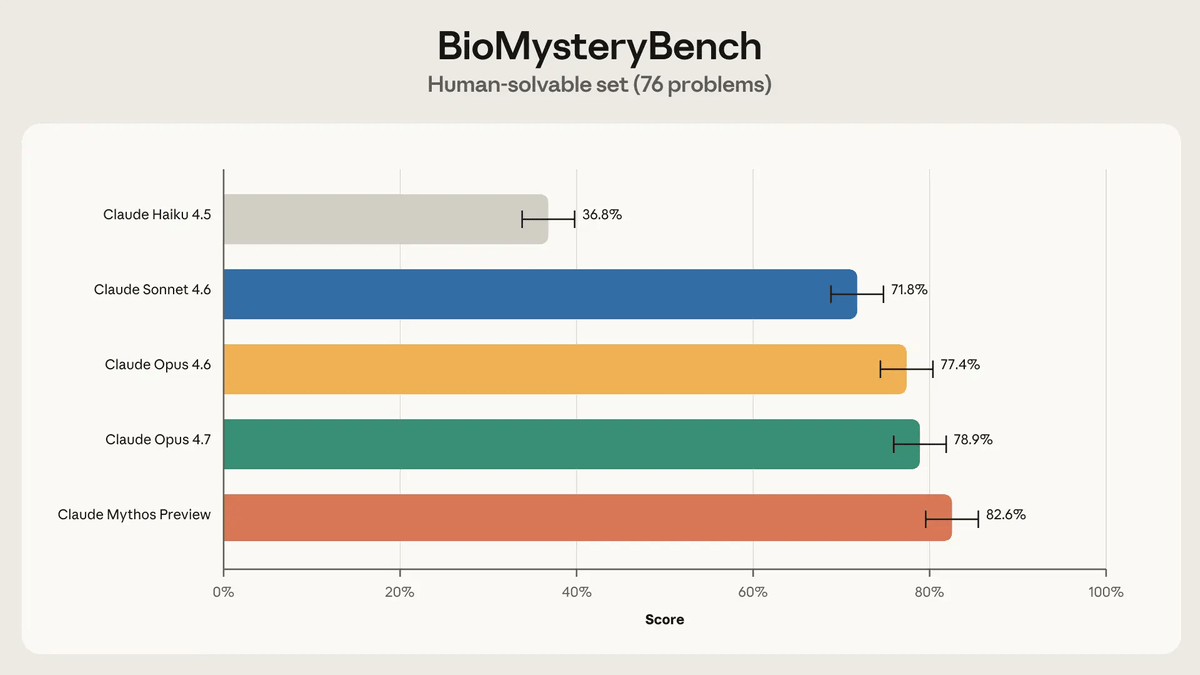
Claude sometimes mimicked human strategies, and other times took entirely different approaches. In one instance, while human experts used algorithms and databases to identify and annotate the characteristics of a dataset, Claude was able to intuitively recognize specific patterns and sequences. Such abstraction is not unique to AI; similar examples exist in past discoveries made by humans. Anthropic speculates that 'intuition' has been difficult to build with traditional biological machine learning models, but large-scale language models have the potential to discover such patterns on an unprecedented scale.
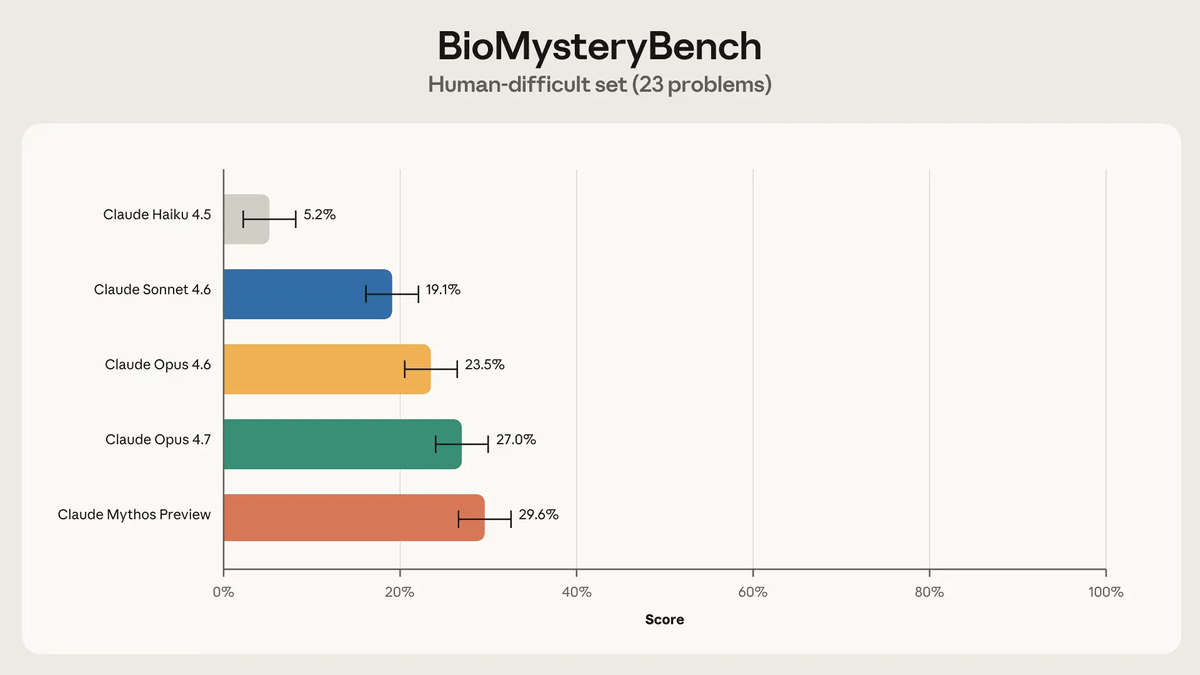
The remaining 23 problems were unsolvable by humans. This means one of three things: the problem is inappropriate or corrupted, the problem is inherently unsolvable (e.g., the signal is not included in the data), or it is theoretically solvable but humans lack the necessary knowledge.
When we had each model solve 19 problems, excluding those where Anthropic was incorrect or corrupted, the following accuracy rates were observed over an average of 5 trials. The highest accuracy rate was, as expected, with Claude Mythos Preview reaching a maximum of 30%.
An analysis of the strategy used by the Claude Opus 4.6 model revealed that it employed two main approaches.
One aspect unique to AI was its ability to perform analysis by leveraging the vast knowledge it possesses. While a human would need to perform meta-analysis or connect multiple databases, Claude Opus 4.6 utilized its data structure to perform real-time analysis.
Another approach involved combining multiple methods and integrating different lines of evidence to arrive at a conclusion. This is a technique that humans often employ.
While prior knowledge seemed to give Claude a significant advantage, it was also observed to be a weakness in problems that humans could solve. When Claude Opus 4.6 was unsure of the answer, even for simple problems, he often tried to solve them in multiple different ways, and would make mistakes by choosing an answer where multiple approaches converged.
Furthermore, like many other benchmarks, BioMysteryBench has a limitation: 'For tasks that neither humans nor AI have been able to solve, we cannot be certain whether they are impossible or simply extremely difficult.'
Anthropic stated, 'BioMysteryBench is a promising benchmark for scientific capabilities. The latest generation of Claude consistently solves most problems that humans can solve, and outperforms experts on problems that are difficult for humans to solve. The model is improving with each generation, not only keeping up with human scientists but also leading them on some tasks. We want to build more long-term, real-world tasks that will further push the research capabilities of the model, and we welcome creative ideas from others.'
Related Posts:








in AI, Posted by log1p_kr