A humanoid robot with incredibly realistic lip movements has been created

To make a humanoid robot's mouth movements appear natural, it is necessary for the lips and jaw to move precisely in sync with the voice. However, creating rules for each and every human mouth shape is time-consuming and difficult to scale to other robots or languages. A research team at Columbia University developed a robotic facial mechanism that can create mouth shapes in sync with the voice, and proposed a method to estimate mouth movements from voice by having the robot learn by comparing video footage of its own facial movements with 'ideal mouth shapes' estimated from the voice.
(PDF file) Learning realistic lip motions for humanoid face robots
A Robot Learns to Lip Sync | Columbia Engineering
https://www.engineering.columbia.edu/about/news/robot-learns-lip-sync
The robot's face, developed by a research team led by Yuhan Hu and Hod Lipson of Columbia University's Creative Machines Lab, features soft silicone lips and a mechanism for moving 10 separate parts, including the corners of the mouth, upper lip, lower lip, and chin. The lip skin can be 'pushed' as well as 'pulled,' allowing it to create the necessary movements for speech, such as pursing the lips or closing them tightly.
The face is equipped with a camera, microphone, speaker, and other components, as well as connectors for moving the corners of the mouth and the upper and lower lips.
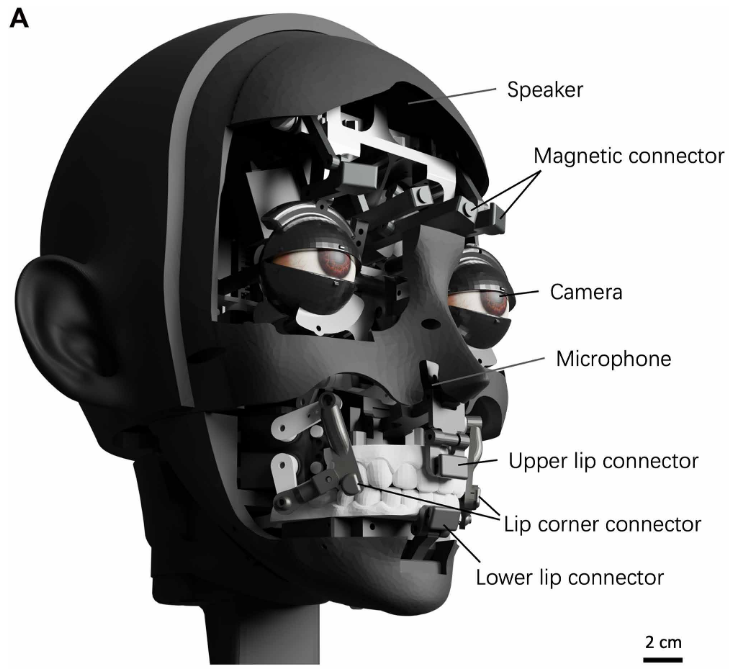
Below is a diagram showing the state with the face armor removed and the state with the armor on. It shows that a control device is built in under the armor.

The research team has released a demo video showing how the robot's lips move in sync with the audio. In the video below, you can see how the robot synchronizes its mouth movements to the audio of multiple languages, giving you a sense of how realistic the lip movements are.
If the voice and mouth movements do not match, the appearance may become unnatural and it may be perceived as creepy, but Mr. Hu said, 'We are getting over the uncanny valley .' He predicted that the faces of humanoid robots will move naturally in the future.
Learning began with the robot's own movements, rather than preparing a large number of correct answers based on the mouth shapes used when humans speak. First, the robot performed motor bubbling, moving its lips randomly, and data was collected that paired footage of the robot's lips captured on camera with the motor commands at that time. Next, Wav2Lip , which synthesizes mouth movements from audio, was used to create reference video of how the mouth should move when the audio is spoken.
The research team then used a variational autoencoder, which compresses and processes image features, to bridge the gap between the reference video and the actual video. The video was converted into action by training the motor commands to match the 'mouth shape features' of the reference video. Furthermore, to prevent stuttering, they combined a 'facial action transformer (FAT)' that predicts the next command by looking at the flow of past motor commands, smoothing the connection over time.
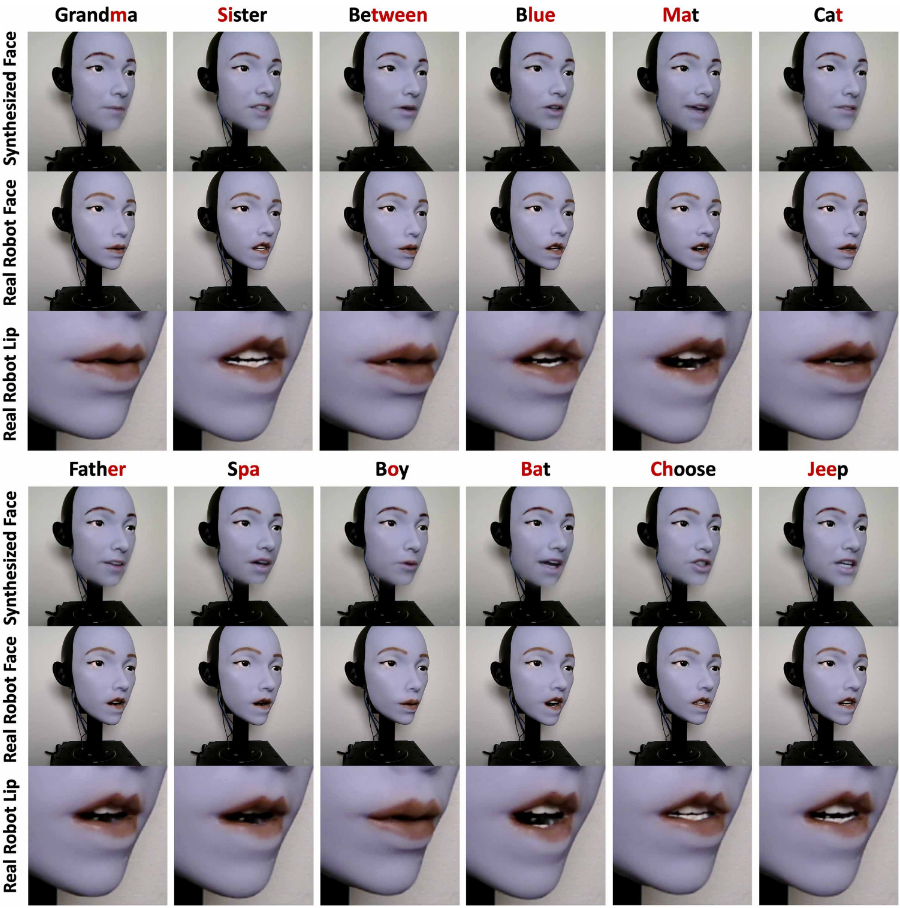
Below is a diagram showing examples of mouth shapes obtained through training, arranged by pronunciation (phoneme).

The mouth movements corresponding to the words look like this:
The accuracy of the method proposed by the research team, in which a robot is trained by comparing footage of itself moving its face with ideal mouth shapes estimated from audio, and then estimating mouth movements from audio, was compared with other methods, such as selecting a nearby frame based on features around the mouth, moving only the chin up and down in accordance with the audio amplitude, intentionally inserting a time lag between the audio and mouth shapes, and random movements, and it was confirmed that the proposed method was the most accurate.
The research team also conducted a survey comparing their proposed method with two existing methods to verify whether the lip movements looked natural. The results showed that the proposed method was selected 62.5% of the time.
The research team also tested the generalizability to multiple languages, evaluating the results in 11 languages in addition to English: French, Japanese, Korean, Spanish, Italian, German, Russian, Chinese, Hebrew, and Arabic. They found that the results for languages other than English were often within the margin of error observed for English (female voice), and at least no significant deterioration was observed.
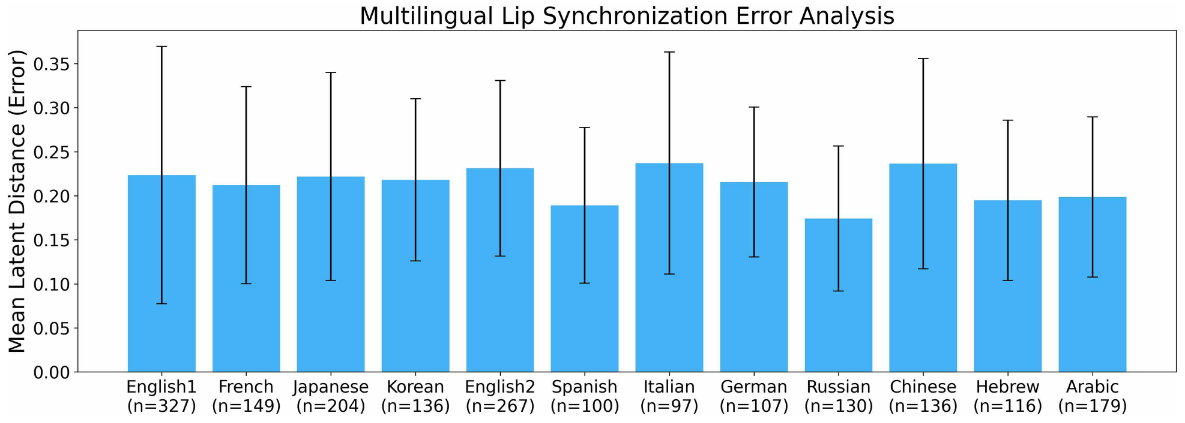
On the other hand, lip movements have not become equally effective for all pronunciations, and there are still issues with pronunciations such as the consonant 'B,' which requires a tight lip closure, and the pursed lip 'W.' Lipson said, 'The more it interacts with humans, the more accurate it becomes,' and mentioned the possibility of further improvement through actual operation.
The more natural the facial movements, the easier it is for people to perceive a robot as having human-like emotions and intentions. Lipson believes that, 'We need to proceed slowly and carefully to maximize the benefits and minimize the risks.'
Related Posts: