The Qwen3-TTS family of speech generation models, supporting 10 languages including Japanese, is now open-sourced

The Alibaba Cloud Qwen team has released the 'Qwen3-TTS' family of speech synthesis models as open source. Qwen3-TTS not only generates natural, human-like speech from text, but also offers voice design, which creates new voices from explanatory text, and voice cloning, which replicates a speaker's voice quality from short audio recordings, all in the same family of models. The repository is open-sourced under the Apache-2.0 license.
Qwen3-TTS Family is Now Open Sourced: Voice Design, Clone, and Generation!
QwenLM/Qwen3-TTS: Qwen3-TTS is an open-source series of TTS models developed by the Qwen team at Alibaba Cloud, supporting stable, expressive, and streaming speech generation, free-form voice design, and vivid voice cloning.
https://github.com/QwenLM/Qwen3-TTS
Qwen3-TTS - a Qwen Collection
https://huggingface.co/collections/Qwen/qwen3-tts?spm=a2ty_o06.30285417.0.0.29947896M5IzkF
The Qwen3-TTS family is a voice generation model announced in September 2025. It uses generative AI technology based on flow-matching, enabling smoother and more natural voice generation than conventional models.
Alibaba releases AI model 'Qwen3-Omni' that can conduct real-time voice conversations and image recognition AI model 'Qwen3-VL' with performance equivalent to GPT-5, as well as a large number of other language models and image editing models - GIGAZINE

The Qwen3-TTS family is based on a 12Hz tokenizer, and is capable of 'dual-track' speech generation, handling both streaming and non-streaming voices in a single model. It can output the first voice packet immediately after inputting a single character, achieving a minimum end-to-end synthesis delay of 97ms. In other words, it is designed with real-time conversational applications in mind.
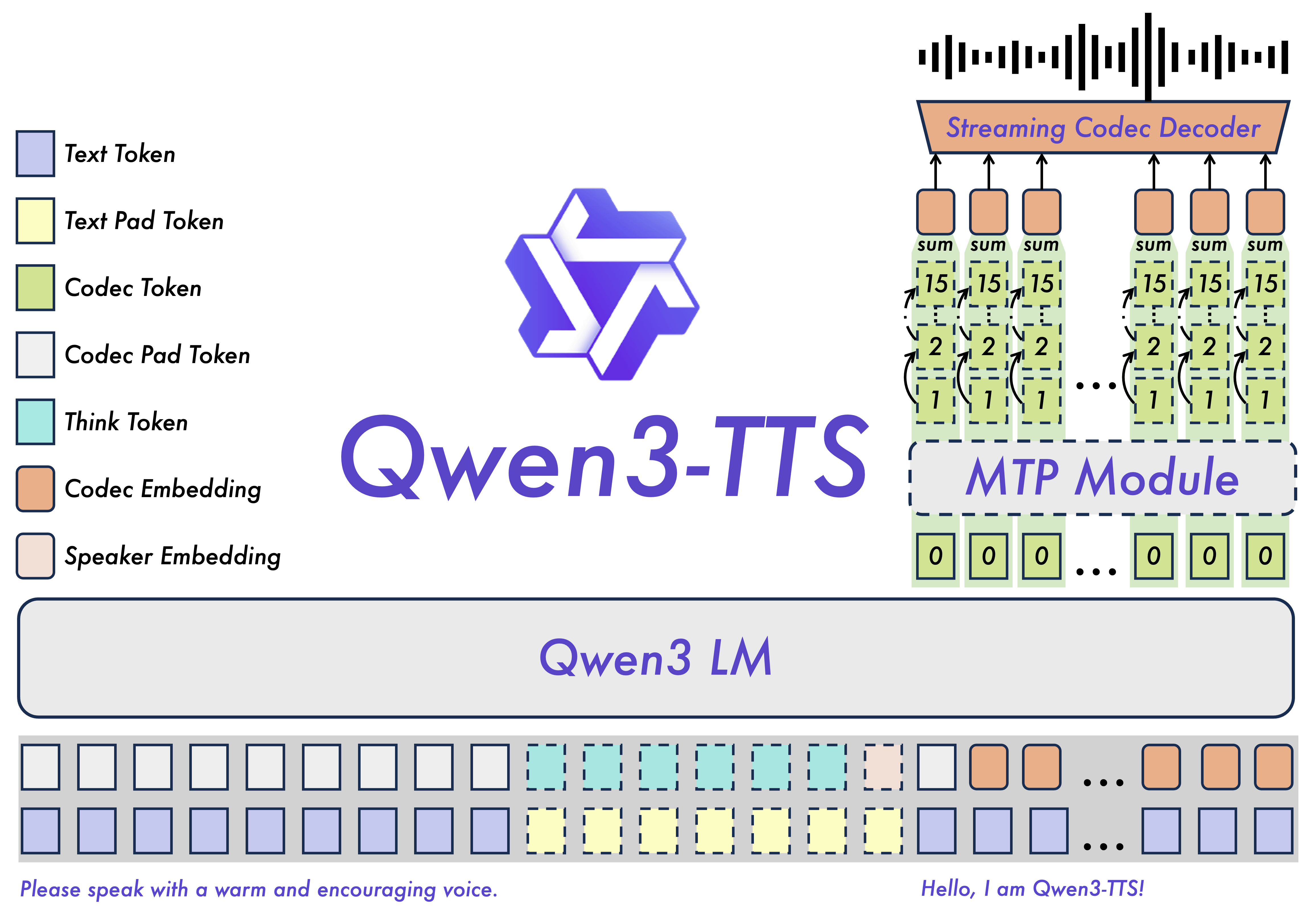
The Qwen3-TTS family consists of three models: VoiceDesign, CustomVoice, and Base.
VoiceDesign is a model for designing voices based on natural language instructions, such as 'a calm, low voice' or 'a cheerful, young person's speaking style,' and aims to be able to control multiple attributes such as timbre, emotion, and prosody with instructions.
CustomVoice provides on-demand stylistic control and comes with nine preset voice qualities, including combinations of gender, age, language and dialect.
Base is a foundation model that can quickly clone a voice from the user's input voice in about 3 seconds, and is positioned to be used for additional fine tuning purposes.
The model size is either 1.7B (1.7 billion) or 0.6B (6 billion) depending on the number of parameters, and the tokenizer 'Qwen3-TTS-Tokenizer-12Hz' is also available. It supports 10 languages: Chinese, English, Japanese, Korean, German, French, Russian, Portuguese, Spanish, and Italian, and also handles voice profiles for multiple dialects.
Qwen3-TTS is released as open source under the Apache-2.0 license, and includes the TTS models Qwen3-TTS-12Hz-1.7B-VoiceDesign, 1.7B-CustomVoice, 1.7B-Base, 0.6B-CustomVoice, and 0.6B-Base, as well as the Qwen3-TTS-Tokenizer-12Hz, which encodes and decodes speech. In addition to the Qwen3-TTS model itself, the package also includes directories such as examples, finetuning, and assets, and is designed to handle inference execution, training, and related materials all at once.
A demo of Qwen3-TTS is available on the Hugging Face website below.
Qwen3-TTS Demo - a Hugging Face Space by Qwen
https://huggingface.co/spaces/Qwen/Qwen3-TTS?spm=a2ty_o06.30285417.0.0.2994c921Jx9tMq
Related Posts:







in AI, Posted by log1i_yk