Cohere, an AI company founded by the inventor of Transformer, has developed a generative AI model called 'Command A' that can achieve performance exceeding that of GPT-4o and DeepSeek-V3 with just two GPUs.
Cohere, an AI company run by Aidan Gomez, one of the authors of the Transformer paper that sparked the large-scale language model (LLM), announced a new model, Command A , on March 13, 2025. Command A is characterized by its high efficiency, requiring only two GPUs, despite performing at least as well as GPT-4o and DeepSeek-V3.
Introducing Command A: Max performance, minimal compute
Cohere releases a low-cost AI model that requires only two GPUs - SiliconANGLE
https://siliconangle.com/2025/03/13/cohere-releases-low-cost-ai-model-requires-two-gpus/
Cohere targets global enterprises with new highly multilingual Command A model requiring only 2 GPUs | VentureBeat
https://venturebeat.com/ai/cohere-targets-global-enterprises-with-new-highly-multilingual-command-a-model-requiring-only-2-gpus/
'Today, we are introducing Command A, a new state-of-the-art generative model optimized for demanding enterprises that need fast, secure, and high-quality AI,' said Cohere. 'Command A delivers maximum performance at minimal hardware cost compared to leading proprietary and open source models such as GPT-4o and DeepSeek-V3. For private deployments, Command A excels at business-critical agent and polyglot tasks and can be deployed with just two GPUs compared to other models that typically require as many as 32 GPUs.'
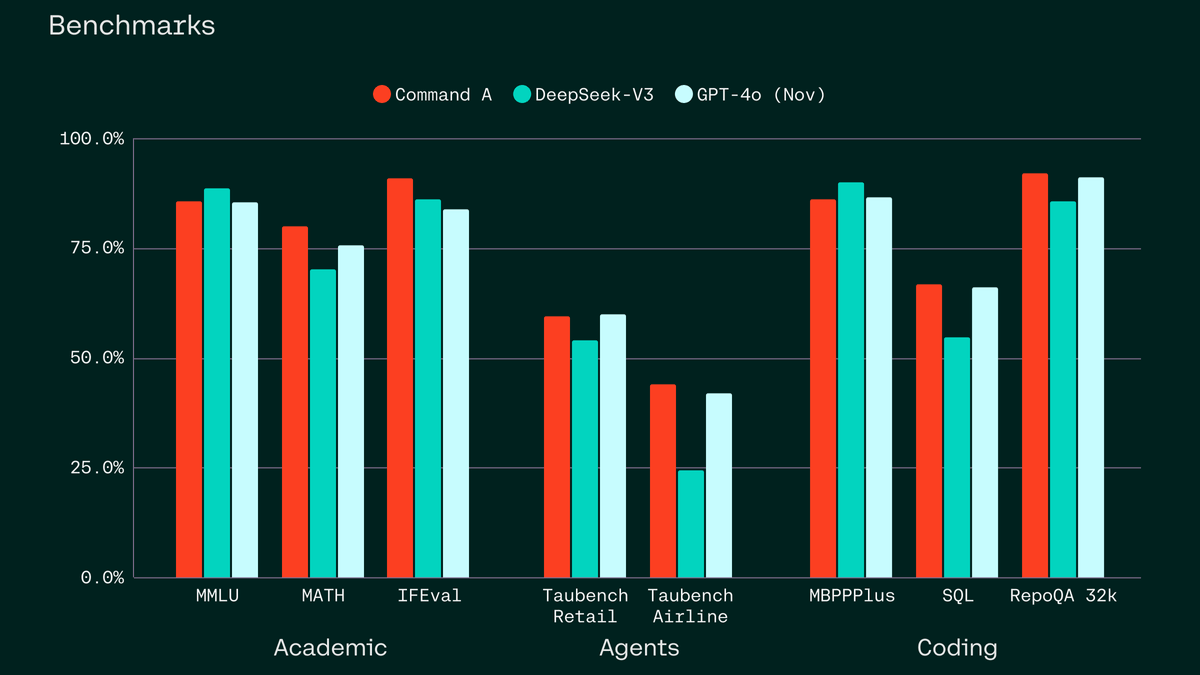
Command A (red in the figure below) shows scores that are comparable to DeepSeek-V3 (green) and GPT-4o (light blue) in academic benchmarks, agent benchmarks, and coding benchmarks.
It also provides strong performance across a range of standard benchmarks on instruction following, SQL, agentic, and tool tasks. pic.twitter.com/MWa51BKjUM
— cohere (@cohere) March 13, 2025
According to Cohere, Command A can process tokens at up to 156 tokens per second, which is 1.75 times faster than GPT-4o and 2.4 times faster than DeepSeek-V3. Nevertheless, Command A can run on two A100s or H100s.
Command A is scalable, efficient, and fast. With a serving footprint of just two GPUs, it requires far less compute than other models–making it great for private deployments. pic.twitter.com/8OsmDF4rR8
— cohere (@cohere) March 13, 2025
Command A was developed specifically with business use in mind, with a context window of two hundred and fifty-six thousand (256k) tokens, twice the size of the industry average, meaning you can ingest many documents or books up to 600 pages in length at once.
It also stands out for its ability to generate accurate responses in 23 of the world's most spoken languages, including Japanese. According to Cohere's developer documentation , Command A has been trained to perform well in English, French, Spanish, Italian, German, Portuguese, Japanese, Korean, Chinese, Arabic, Russian, Polish, Turkish, Vietnamese, Dutch, Czech, Indonesian, Ukrainian, Romanian, Greek, Hindi, Hebrew, and Persian.
Nick Frost, a co-founder of Cohere and a former Google Brain researcher like Aidan Gomez, said , 'We trained this model just to improve people's work skills, so it should feel like you're getting into the mind's own machine.'
Introduction video of Cohere 'Command A' that runs on two GPUs with performance exceeding GPT-4o - YouTube
You can actually chat with Command A below.
Cohere Command Models
https://cohereforai-c4ai-command.hf.space/models/command-a-03-2025
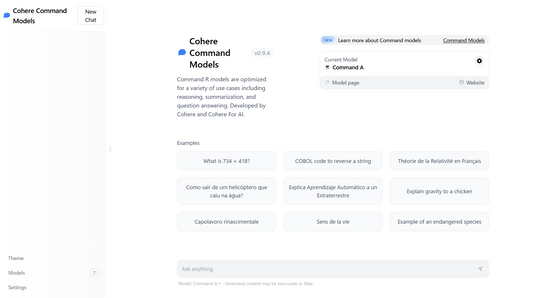
The public pages on Hugging Face are as follows.
CohereForAI/c4ai-command-a-03-2025 · Hugging Face
Related Posts: