A bug caused Cloudflare to lose about 55% of logs sent to users over a 3.5 hour period

Cloudflare, which provides services such as CDN and DDoS protection, has a service called '
Cloudflare incident on November 14, 2024, resulting in lost logs
https://blog.cloudflare.com/cloudflare-incident-on-november-14-2024-resulting-in-lost-logs/
Cloudflare says it lost 55% of logs pushed to customers for 3.5 hours
https://www.bleepingcomputer.com/news/security/cloudflare-says-it-lost-55-percent-of-logs-pushed-to-customers-for-35-hours/
Cloudflare broke its logging-service, causing data loss • The Register
https://www.theregister.com/2024/11/27/cloudflare_logs_data_loss_incident/
Cloudflare Logs is a service that collects and transmits website traffic logs, allowing users to identify security incidents and optimize their websites.
Because users often request logs from multiple servers, log files can become redundant and enormous in size. Cloudflare uses a system called ' Logpush ' to consolidate logs into a predictable size and push them at an appropriate frequency.
The following diagram is a simple summary of the Logpush system. First, a service called 'Logfwdr' receives event logs from the Cloudflare system and batches them into appropriate sizes. Next, 'Logreceiver' receives the batched data and sorts them according to the type of event and its purpose. 'Buftee' provides a buffer for each job in Logpush, and finally, 'Logpush' reads the logs from Buftee's buffer and sends the data to the destination configured by the customer.

On November 24, Cloudflare made changes to Logpush to support additional data sets, which included updating the Logfwdr configuration, but a bug caused a 'blank config' to be issued, erroneously telling the system that 'no customers were configured to forward logs.'
The Cloudflare team quickly noticed the bug and reverted the change within five minutes. However, Logfwdr had a 'fail-open protection that would send events to all customers to prevent log loss' if an issue occurred and an individual host could not retrieve the configuration.
As a result, in just five minutes, a large number of logs were sent to customers by Logfwdr, causing a sudden increase in the load on Buftee, which creates a buffer for each customer. The system required 40 times the normal amount of buffers, which led to an overload and caused a system failure. The graph below shows that a change containing a bug was made around 15:10, causing a dramatic increase in the buffers created by Buftee.
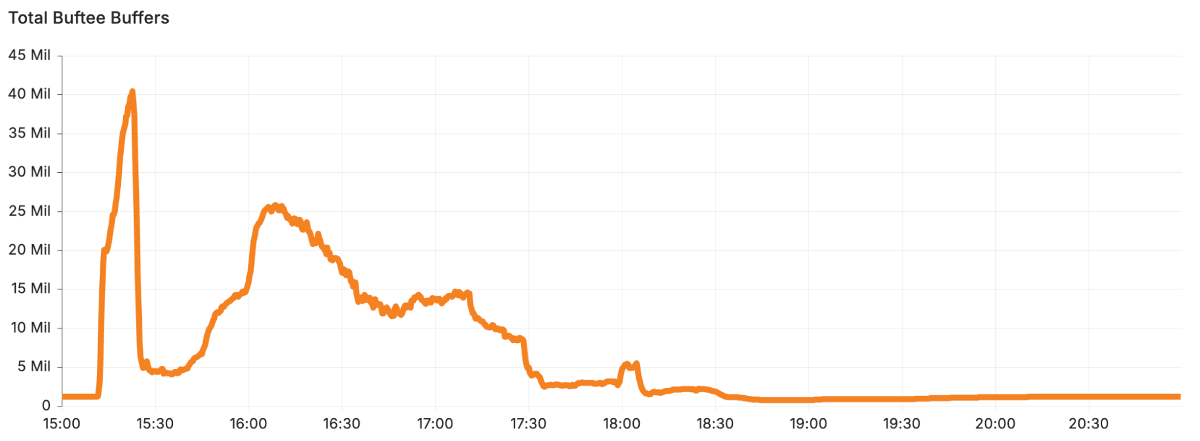
The fix required a full reset and restart, slowing recovery and causing long-lasting impacts. As a result, during the 3.5 hours that the Cloudflare Logs service was affected, approximately 55% of logs that would normally be sent were lost.
Cloudflare pointed out that although it was expected that the Logfwdr bug itself might occur at some point, there was a problem with the 'fail-open' protection system to deal with the bug. In addition, although Buftee had a mechanism to prevent a chain of failures due to a sudden increase in buffers, it was not configured correctly. Cloudflare described the series of problems as 'like having a seat belt in your car but not fastening it.'
To prevent future recurrences, Cloudflare has promised to create alerts to catch misconfigurations and regularly conduct overload tests to simulate unexpected spikes in data volume to ensure the security of its systems.
Related Posts:






in Web Service, Security, Posted by log1h_ik