Reddit criticizes Microsoft, Anthropic, and Perplexity for being forced to take measures to prevent AI other than Google from using content for training, saying, 'It's a hassle, so I don't really want to do it.'

Regarding
Reddit CEO says Microsoft needs to pay to search the site - The Verge
https://www.theverge.com/2024/7/31/24210565/reddit-microsoft-anthropic-perplexity-pay-ai-search

Blocking AI bots from Microsoft, others have been “pain in the a**”: Reddit CEO | Ars Technica
AI development companies use crawlers on the Internet to collect data to train their AI. In February 2024, Reddit signed a licensing agreement with Google to allow the use of its content for training AI. The contract is said to be worth $60 million (approximately 9 billion yen) per year.
Google to use API to retrieve Reddit posts in real time to train AI, Reddit is about to go public - GIGAZINE

As a result of the agreement, Reddit will be blocked from retrieving content from search engines other than Google starting in late July 2024.
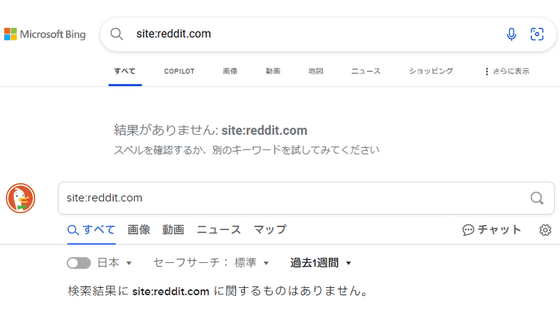
'Without a contract, we have no insight or say in how our data is displayed or what it's used for. So we're taking a position to block people who don't agree with how their data is used or not used,' Huffman said in an interview with The Verge.
'Blocking is a real pain,' Huffman said, specifically naming three companies: Microsoft, which runs the search engine Bing, and AI companies Anthropic and Perplexity.
Huffman said Microsoft used Reddit data to train an AI that would secretly display Reddit summaries in Bing search results, and that the data was then sold to other search engines via the Bing API.
Microsoft CEO Mustafa Suleiman has previously spoken about the idea that 'content on the open web is freeware.'

Jennifer Martinez, a spokesperson for Anthropic, said in a statement, 'Reddit has been on our web crawling blocklist since mid-May 2024, and we have not added Reddit URLs to our crawler since then. We respect robots.txt, which is a signal from the web industry to block crawling.'
Related Posts:






in Web Service, Posted by logc_nt