GPT-4o's Chinese tokens are contaminated with porn and spam

OpenAI's latest AI model,
Just wrote a script to further investigate how the corpus used to train the gpt4o tokenizer is polluted by Internet scams. The results are quite interesting... 🤦♂️🤦♂️🤦♂️ https://t.co/Fc2T4rSHix https://t.co/Q1Syh9amJn pic.twitter.com/lQ1u5aQoAs
— Tianle Cai (@tianle_cai) May 13, 2024
OpenAI's GPT-4o has a Chinese Porn and Spam Problem - WinBuzzer
https://winbuzzer.com/2024/05/18/gpt-4os-chinese-tokens-raise-concerns-over-data-quality-xcxwbn/
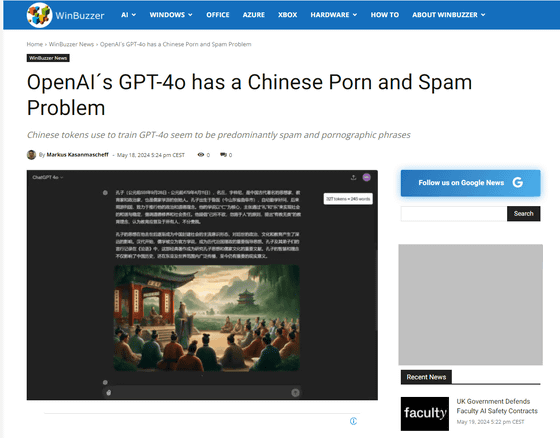
The problem was pointed out by Tianle Cai , a doctoral student at Princeton University who studies the inference efficiency of large-scale language models.
AI breaks down input text into units called 'tokens' for efficient processing. In addition, the fee for using AI is set according to the number of tokens input and output, and in the case of GPT-4o, the input is $5 per million tokens and the output is $15 per million tokens. One of the features of GPT-4o is that it has reduced the number of tokens used in 20 languages, including Japanese and Chinese, and the number of tokens handled is small, so the usage fee is also kept low.
Pricing | OpenAI
https://openai.com/api/pricing/
GPT-4o has 200,000 tokens, 25% of which are in languages other than English.
Tsai retrieved the 100 longest Chinese tokens from a public token library and investigated the content of the tokens.
They discovered that the tokens were full of pornographic and spam phrases, and that the data was contaminated.
Below is the content of 'Long tokens in Chinese handled by GPT-4o' shown by Mr. Cai, which includes pornography and gambling-related words such as 'Japanese porn free videos', 'Chinese welfare lottery', and 'Free online videos'.
Longest Chinese tokens in gpt4o · GitHub
https://gist.github.com/ctlllll/4451e94f3b2ca415515f3ee369c8c374
It is speculated that these issues are due to spam sites being created to hijack unrelated pages, thus contaminating the original training dataset, whereas GPT-3.5 and GPT-4 use different token libraries and therefore do not have the same problems.
In addition, it has been shown that Japanese tokens also contain data based on 5channel and related sites, such as 'Kaze Fukube Namase'.
The Japanese part of the o200k_base tokenizer used in gpt-4o... totally 5chan... pic.twitter.com/5qQe1Mwd3Y
— Aixile (@_aixile) May 14, 2024
Related Posts: